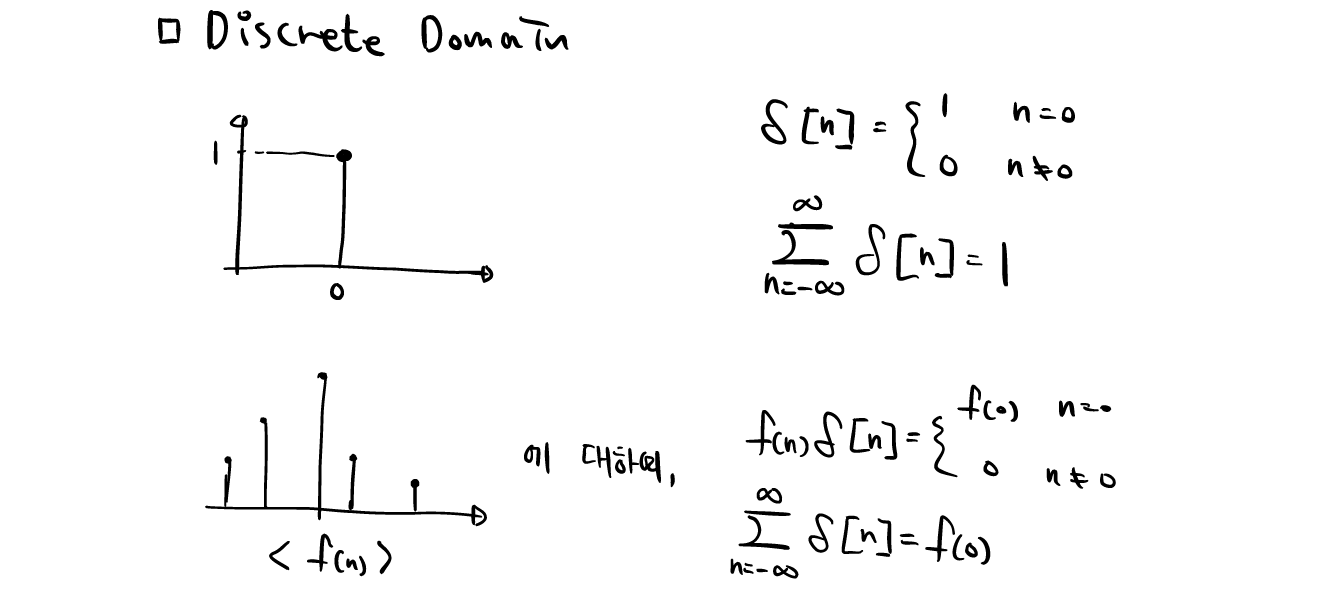
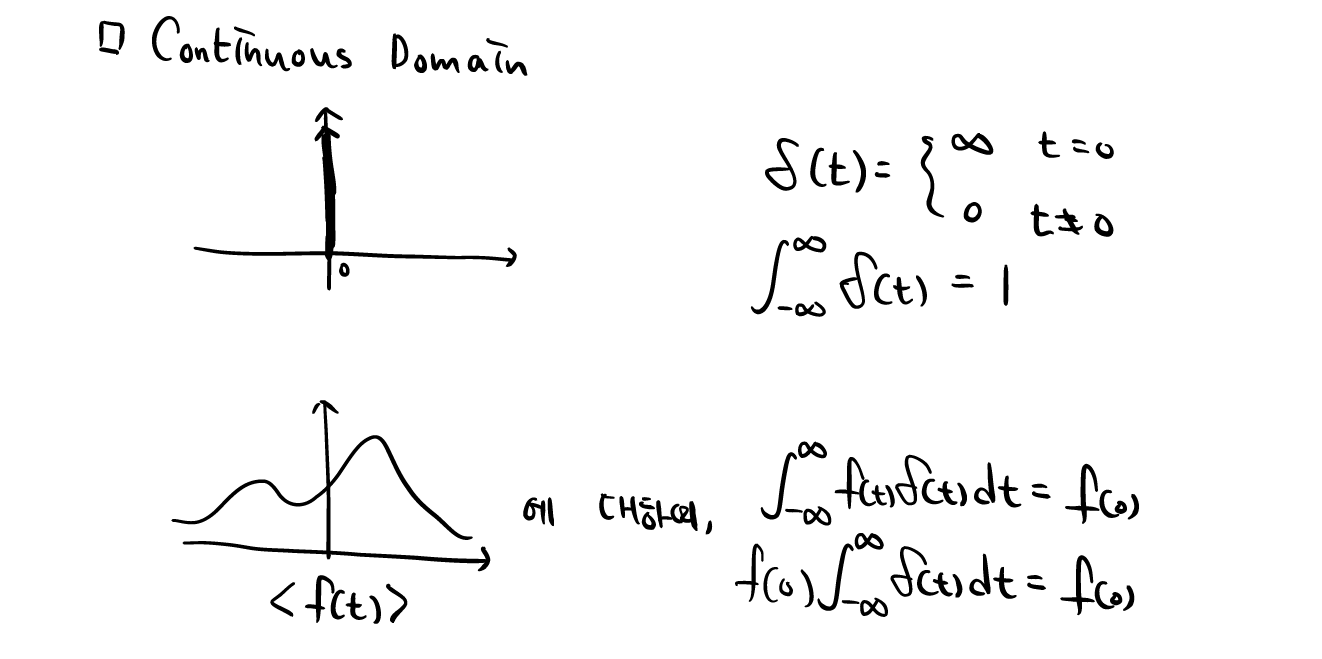
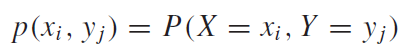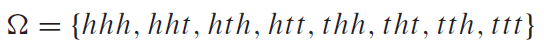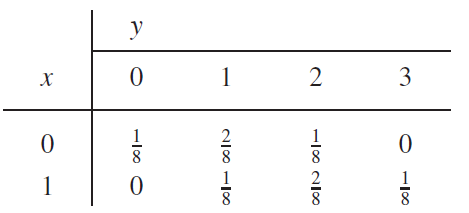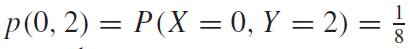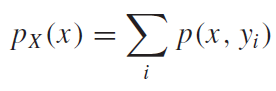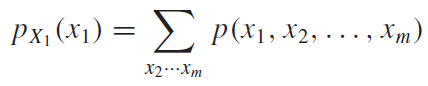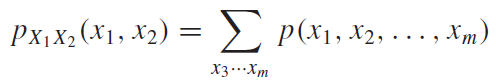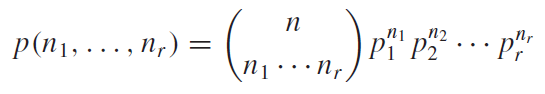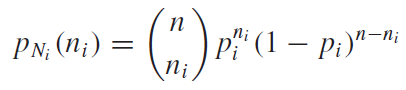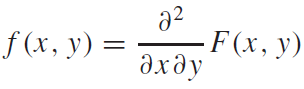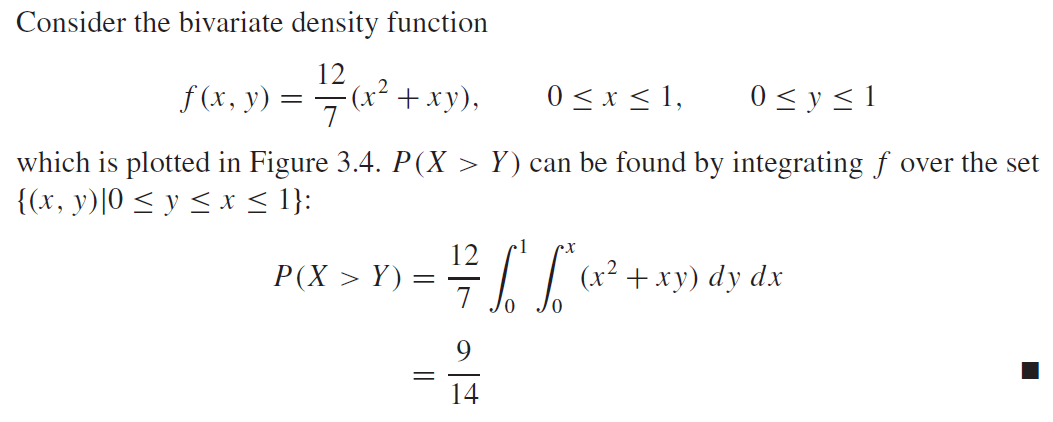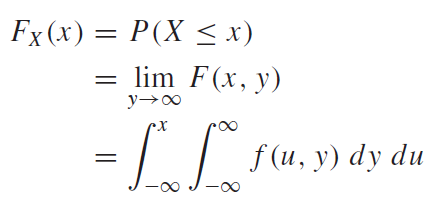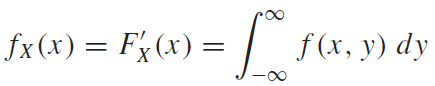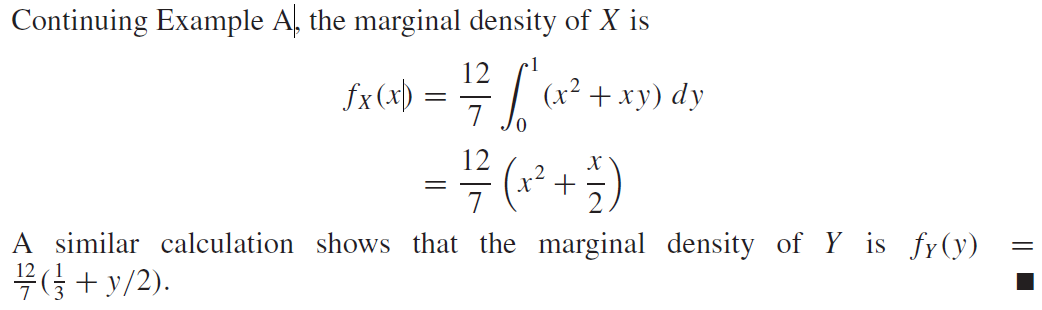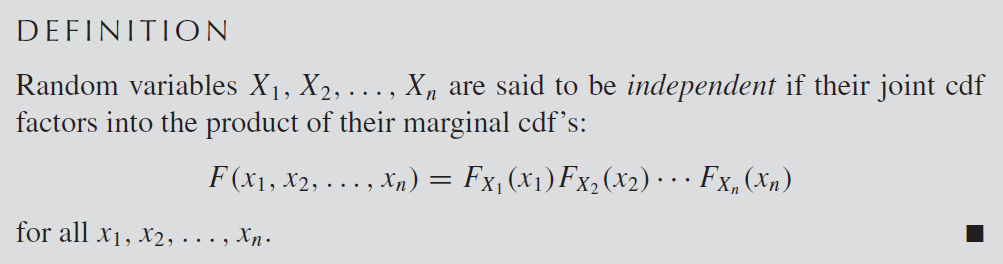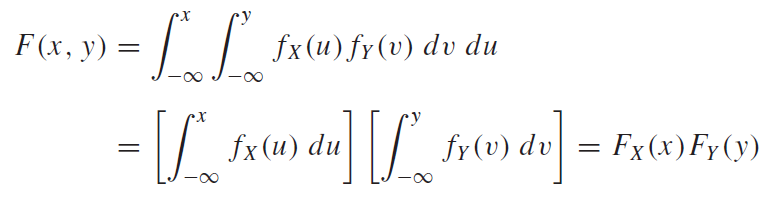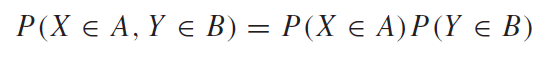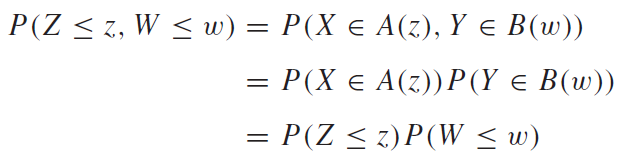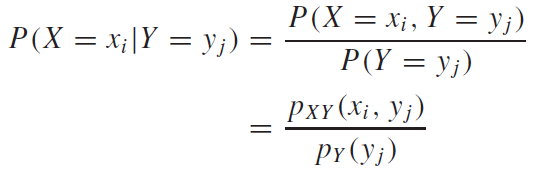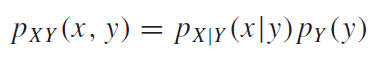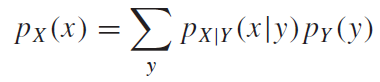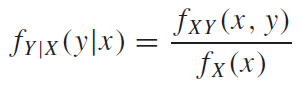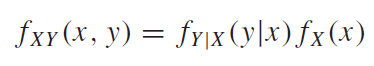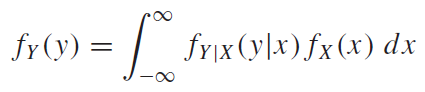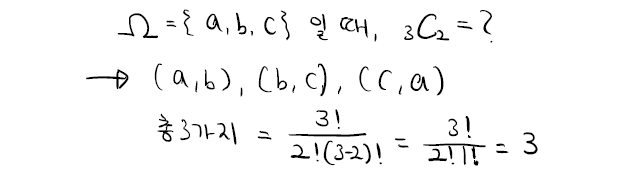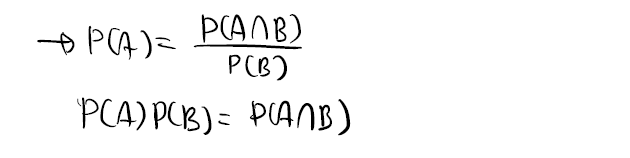Signals and Systems-2. 푸리에 급수(Fourier Series)
16 Jan 2020 | Signals and Systems푸리에 급수(Fourier Series)
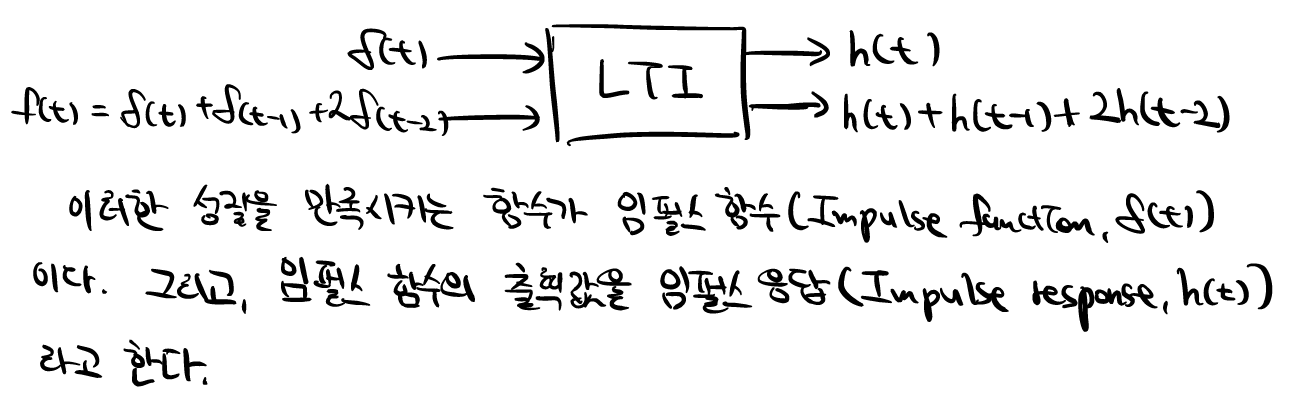
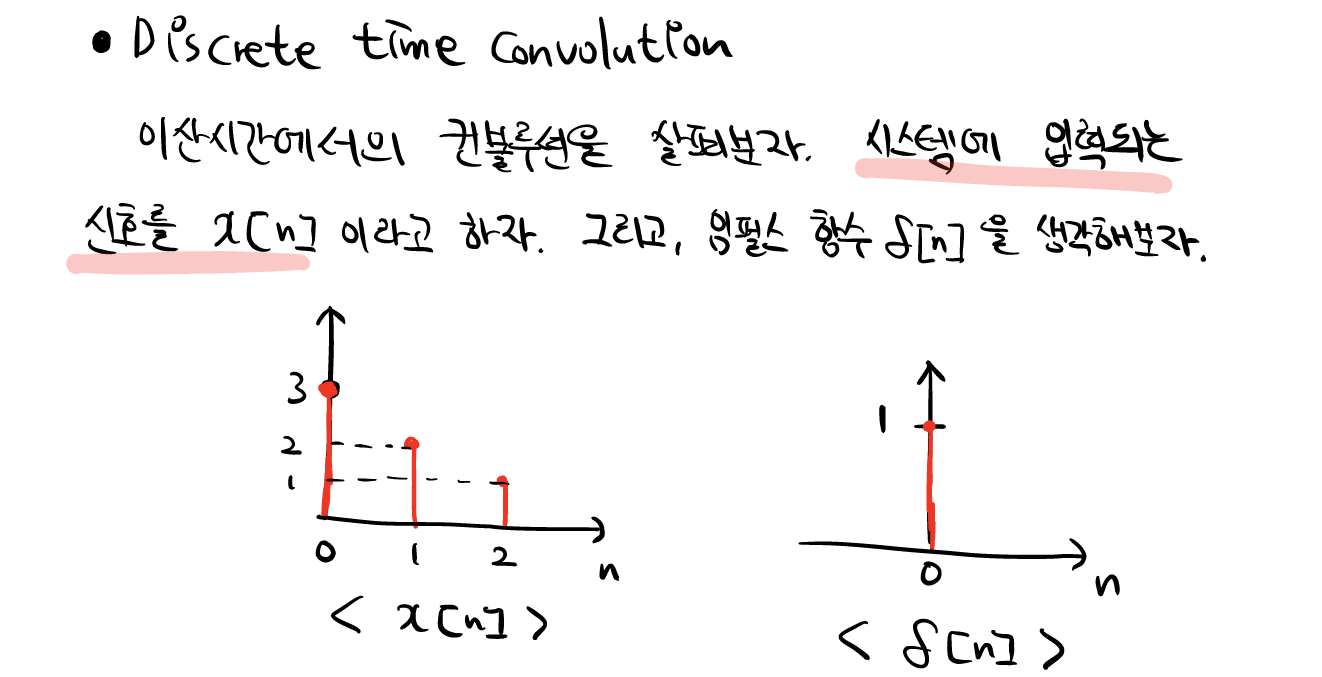
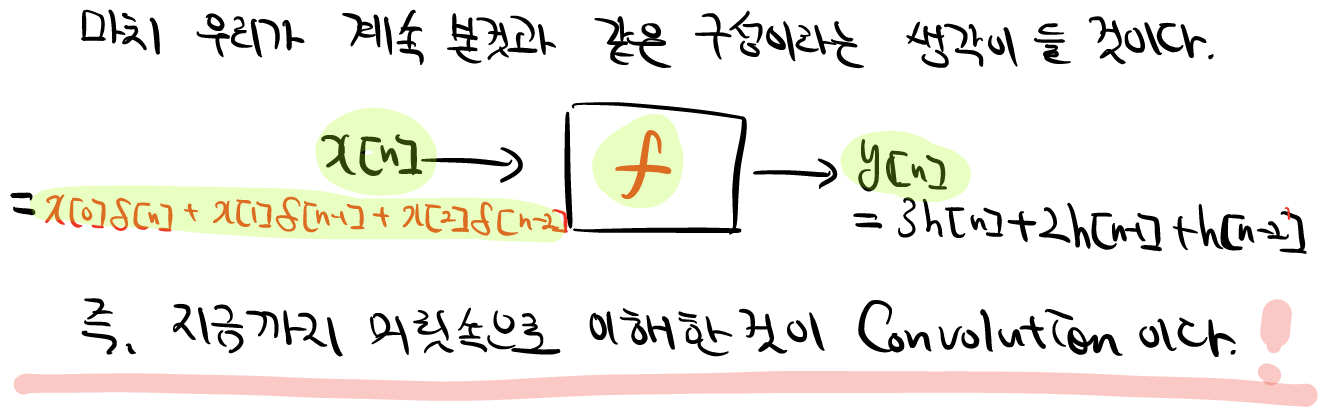
지난 시간에 컨볼루션(Convolution)에 관해서 배웠다. 컨볼루션은 입력함수x단위임펄스함수의 합, 즉 급수(Series)였다. LTI시스템을 가정했을 때, 우리는 단위임펄스함수(입력함수)에대한 시스템의 임펄스응답(출력함수)를 앎으로, LTI시스템의 Superposition성질을 이용하여 입력함수를 단위임펄스함수를 이용하여 단위임펄스함수외의 다른 입력함수들의 출력함수 및 출력값을 간단하게 구할 수 있는 역할을 하였다.
오늘은 또다른 급수를 배운다. 그게 바로 푸리에 급수다. 푸리에 급수는 신호 도메인의 테일러 급수와 라고 할 수 있다. 테일러 급수는 f라는 함수를 다른 다양한 함수의 함을 통하여 근사시켜 표현한다. 이렇게 표현하면, 다항함수로 표현되어 미분 적분 및 다른 연산이 용이해진다는 장점이 있었다. 푸리에 급수는 테일러급수가 어떤 함수를 다른 함수를 통하여 근사시켜 표현한다면, 푸리에 급수는 입력신호 를 다른 신호의 합으로 근사시켜 표현하는 것이다.
그렇다면 여기서 말하는 단순한 신호는 무엇일까? 우리가 1장에서 배웠던 삼각함수로 구성된 오일러함수(Euler Function) 이다. 즉 복소평면까지 다룬 삼각함수의 합이라고 생각하면 된다.
여기서 다시 한 번 오일러 함수를 복습해보자.
/img_1.png)
위 오일러 함수는 크기가 A인 오일러 함수이다. 그 때,
이 때 봐야할게 두 가지가 있다. 첫 번째는 바로 $\omega_0 $다. $\omega_0 = 2\pi f$라고 해보자. 여기서 $\pi$는 원주율을 의미하고, $f$는 주파수(frequency)를 의미한다. 그럴 때 오일러 함수를 다시 생각해보자. $f=1hz$라고 하면, $\omega_0 = 2\pi$가 된다. 이 뜻은 **오일러 함수의 주기가 $2\pi/sec$ 라는 것이다. 왜냐하면 $t=1sec$일 때, $\theta=2\pi$가 됨으로, 한 바퀴를 돌았다는 뜻이 되기 때문이다. 그렇다면 $f=2hz$일 때에는 어떻게 될까? $\omega_0 = 4\pi$ 그리고 $t=0.5sec$ 일 때, $\theta=2\pi$ 가 됨으로 0.5초에 한 바퀴를 돌았다는 뜻이 된다. 즉 주기가 $2\pi/0.5sec$ 로 두 배 빨라졌다.
두 번째로, $k$ 를 집중해서 봐보자. $k$를 보았을 때, 어떤 공통점이 있을까? 우선 정수(Integer)라는 것이다. 그리고 차수가 입력함수의 주기의 배수(입력:$2\pi$, 더해지는 함수들의 주기: $(1/2n) \pi$, $(k=2n\pi)$ )로 이루어 져야 한다. 이런 항의 합으로 이루어진 급수를 하모닉스(harmonics)라고 한다. 그렇다면 하필 실수가 아닌 정수만의 합으로 표현이 될까? 사실 실수여도 아무 상관이 없다. 하지만 그럴 필요가 없기 때문이다. 무한개의 개수의 항으로 표현된다고 한다면, 정수만으로 표현을 하여도 충분히 근사시킬수 있기 때문에, 실수와 정수를 동시에 사용하여 복잡하게 표현할 필요도 없고 불필요하게 계산량을 늘릴 필요도 없기 때문이다.
그런데 여기서 또 하나 의문이 드는 점이 생긴다. 오일러 함수는 복소함수이다 즉, 실수와 허수값이 모두 존재하는데 실제로 이런 신호는 존재하지 않는다. 실수항만 남겨서 신호를 표현해야 하는데 그러면 이 신호를 어떻게 표현해야 할까? 그것은 바로 간단하게 덧셈을 이용하면 된다.
벡터공간(Vector space)
갑자기 웬 벡터? 라는 생각이 들 것이다. 관련이 있으니 다음 내용을 같이 살펴보자. 우선 벡터공간(Vector space)란 무엇일까? 바로 아래의 8가지 공리를 만족시킨다면 무엇이든지 벡터공간이라고 할 수 있다.
/img_2.png)
우리가 흔히 아는 벡터는 방향성을 가지고 화살표로 표현되는 애들, 혹은 매트릭스로 표현되는 것들 뿐만이 아니다. 벡터 공간에 속하는 모든 것은 벡터라고 할 수 있는 것이다.
그렇다면 이제 이렇게 생각해보자. 어떤 빈 공간A가 있다. 그리고 우리는 임의로 크기와 주기가 다른 오일러 함수들을 저 공간A로 모두다 집어 넣을 것이다! 즉, 어떤 빈공간 A에 우리가 정의한 오일러 함수 $Ae^{jw_0t}$에서 $A와 w_0$의 모든 조합(Combination)이 존재한다고 생각하자. 그 후, 이제 그 공간A 안에 있는 원소들끼리 연산을 하여 8가지 공리를 만족시키는지 확인하자. 만약에 공간A 안의 모든 원소에 대해서 8가지 공리를 만족시킨다면, 공간A는 벡터공간이라고 할 수 있을 것이고, 그 안에 있는 원소는 벡터라고 할 수 있게 된다. 여기서 신호=벡터가 될 수 있다는 것이 중요한 점이다! 여기서 보면 간단히 대부분의 공리가 만족하는 것을 알 수 있다. 여기서 중요한게 세번째 공리이다. 세번째 공리를 만족 시키려면 공간안에서 0이 정의 되야한다. A가 0이면 0인 신호가 만들어지므로, $x + 0 = 0 + x = x$ 을 만족한다. 그리고 나머지 7가지의 공리를 만족하는 것을 임의의 두 함수를 잡고 연산을 해보면 모든 연산에서도 만족하는 것을 예상할 수 있다. 결국 오일러 함수 $Ae^{jw_0t}$를 벡터로 취급할 수 있다는 것이 가장 중요한 것이다.
내적(Inner product)
위에서 벡터인것을 파악은 했는데 이번에는 내적? 왜 내적이 나왔을까? 결론부터 말하자면 주파수가 다른 서로다른 두 신호는 수직관계를 이룬다는 점이다. 선형대수에서도 배웠겠지만, 수직인 벡터의 내적은 0이 나오는 것을 알고있을 것이다. 실수 영역의 두 벡터 a,b에 대해서 내적은 다음과 같이 정의된다.
방금 실수 영역 이라고 했다. 우리가 다루는 오일러함수는 복소평면에서의 벡터라는 것을 위에서 알았다. 복소평면에 존재하는 벡터의 내적은 실수 영역에 존재하는 벡터의 내적과 약간 다르다. 두 복소벡터 a,b가 있을 때, 두 벡터의 내적은 다음으로 정의된다.
위에서 말했듯이, 오일러 함수는 벡터이기도 하다. 그리고 내적 공간(Inner product space) 에 속한다. 내적 공간의 정의는 각자 찾아보도록 하자. 내적 공간에 속한다는게 뜻하는 것은, 내적 공간안에 속하는 벡터들 끼리는 내적이 모두 성립한다는 것이다. 내적이 정의 되면, 벡터의 길이 및 벡터 사이의 각도에 대해서 논할 수 있게 된다. 결론은, 오일러 함수는 내적이 가능한 벡터라는 것이다.
오일러 함수는 복소함수이다. 두 복소함수 f, g 의 내적은 다음과 같이 정의된다.
이 때, $f(t)=e^{jk\omega_0t}, g(t)=e^{jr\omega_0t}$인 주기가 서로 다른 변수를 가지는 오일러 함수라고 하자. 그렇다면, 두 함수의 내적은 다음과 같이 쓸 수 있다.
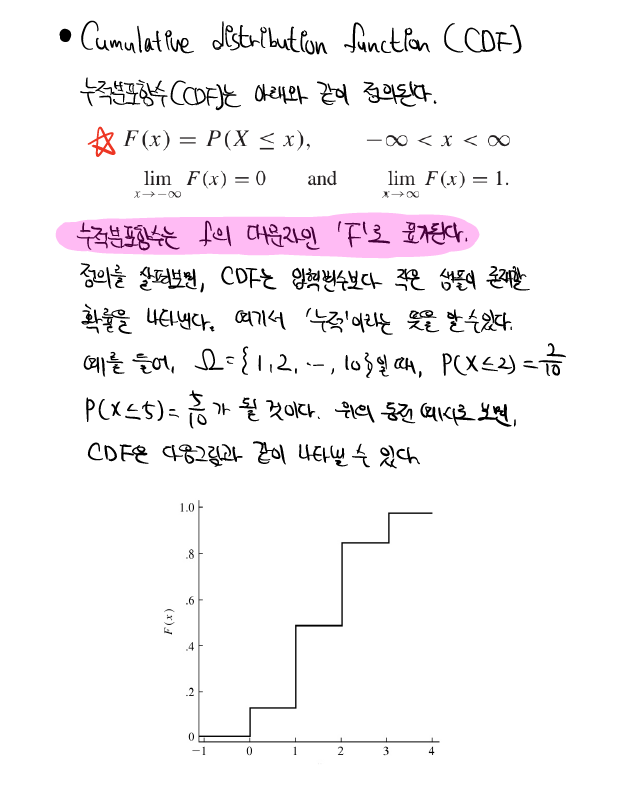
k와r이 같은 경우, 식1 에서 $e^0 = 1$ 이므로, 1을 해당 구간에서 적분하면 $T_0$라는 값을 간단하게 얻을 수 있다. k와r이 다른경우에는 적분을 한 번 해보면 된다. 이 때, $T_0$는 fundamental period이다. fundamental period란 모든 n에 대해서 $f(t) = f(t +nT_0)$ 를 만족시키는 $T_0$를 의미한다. 예를 들어, \(Periodic \ \ Funcion 는\ f(t)=f(t+nT)을\ 만족시키는\ 함수f를\ 뜻한다. \\ 이\ 때, n은\ 모든\ 정수,\ T는\ 함수f의\ 주기를\ 뜻한다. \\ 그리고,\ T중\ 가장\ 작은\ T를\ T_0(fundamental\ period)라\ 한다. \\ 에를 들어, sin(x)의 주기는\ 2\pi , 4\pi, 8\pi가 될 수 있다. 이 때, T_0=2\pi이다.\\\) ex) \(f(t) = sin(10\pi t)일 때,\ 주기함수인\ sin함수의\ 주기는\ 2\pi\ 이므로, \\ sin(10\pi t + 2n\pi) = sin(10\pi (t+nT_0))를 만족해야한다. \\ 이때, T_0는\ f(t)의 fundamentla\ period다. 그러면, \\ 10\pi t + 2n\pi = 10\pi (t+nT_0) \\ 2n\pi = 10\pi nT_0 \\ T_0 = 1/5 \\ fundamental\ period = 1/5\)
/img_3.png)
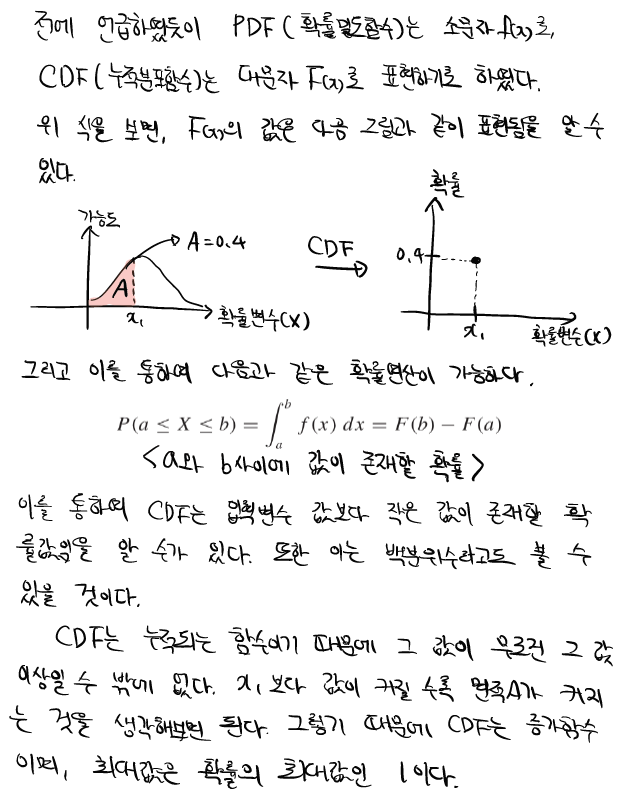
푸리에급수는 주기가 Harmonics를 이룬다고 했다. 즉, 입력함수의 주기가 $2\pi$ 라면 그 입력함수를 이루는 함수들의 주기는 그의 배수인 $\pi$ , $(1/2)\pi$ , $(1/4)\pi$ … 의 주기를 가진 함수들의 합으로 이루어진다는 것이다. 그렇기 때문에 가장 긴 주기를 fundamental period를 적분구간 으로 설정한다면, sin및 cos함수는 한 주기의 적분 값이0이기 때문에, 주기가 배수인 함수들에 대해서 적분 결과가0 이므로, 최종적으로 적분 결과가 0인 값을 얻어낼 수 있다. 푸리에 급수식을 다시 요약해보자.
여기서 잠깐 선형대수의 지식을 기억해보자! 기저(basis)에 대해서 다시 기억을 떠올려 보자. 우리가 아는 2차원 유클리디안 좌표평면의 기저는 무엇일까? $\left[ \begin{array}{rr}1 \ 0\end{array} \right]$, $\left[ \begin{array}{rr}0 \ 1\end{array} \right]$ 이다 그리고 우리는 이 기저의 선형결합(Linear combination) 을 통해서 2차원 유클리디안 좌표계의 모든 좌표를 표시할 수 있다. 이런식으로 3차원이면 3개의 기저가 있으면 모든 3차원 좌표계를 표시할 수 있다. 즉, 이런식으로 n차원에 n개의 기저가 있다면 n차원의 모든 좌표를 표시할 수 있다. 여기서 가장 중요한 것이 있다. 푸리에 급수 식을 다시 보자. 푸리에 급수를 구성하는 함수들은 모두 수직 이며 이는 곧 독립이라는 것을 뜻한다. 즉, 급수를 구성하는 모든 함수가 기저인 것이고, 앞의 상수를 곱하여 선형결합을 통하여 나타낸 것이다. $n->\infty$ 이라면, 푸리에 급수를 통하여 무한차원 까지 표현이 가능하다.
푸리에 계수(Fourier Coefficient)
마지막으로 푸리에 계수를 구하는 방법을 알아야 한다. 우리는 이때 내적을 이용하고 아까 배웠던 주기가 같으면 값이 나오고, 주기가 다르면 값이0이 나오는 성질을 이용하여 계수를 구할 것이다. 입력신호$x(t)$를 푸리에 급수를 이용하여 표현하면 아래와 같았다.
이때, 우리는 $a_k$의 값을 구해야하는 것이다.
첫 번째, 양변에 $e^{-jr\omega_0t}$를 곱하자.
두 번째, 양변에 $x(t)$의 주기( $T_0$ )까지의 구간으로 적분을 하자.
이 때, $k==r$인 경우를 제외하고는 모두 0이 되므로, 결론적으로 $k==r$일 때, $a_r$ 만 남게 된다.
이므로, 좌변 우변을 항을 잘 조절하면
그런데, $k==r$인 경우의 결과이므로, r을 k로 치환 가능하다.
이 식을 외우는게 아니고, 내적에 따른 결과로 기억하면 더 좋을것 같다. 이 식을 풀어쓰면 우리가 흔히 아는 cos, sin의 형태에서의 두 계수 역시 구할 수 있다.
마지막에 하나만 더 챙기고 가보자. 그렇다면 이 푸리에계수가 의미하는 것이 무엇일까? 조금 전에, 푸리에급수를 이루는 항들은 모두 독립적인 기저라고 하였고, 푸리에 급수는 이런 기저들의 선형결합(Linear Combination)이라고 하였다. 그런데, 조금전에 구한 푸리에 계수의 일반식을 보면, 입력신호 x 기저의켤레(conjugated basis) 의 적분인 것을 볼수 있다. 이것은 입력신호와 기저간의 내적을 의미한다. 즉, 푸리에 계수는 입력신호와 기저와 내적의 결과값인 것이다.
내적의 값은 벡터끼리의 각도차이가 작을수록 값이 크게 나온다. 이 말은 즉, 입력신호와 비슷할 수록 내적값이 크게 나온다는 것이다. 결론적으로 푸리에 계수는 기저함수가 입력신호를 구성하는데 얼만큼의 지분을 가지고 있는가를 나타내는 기여정도(contribution) 라고 볼 수 있다.