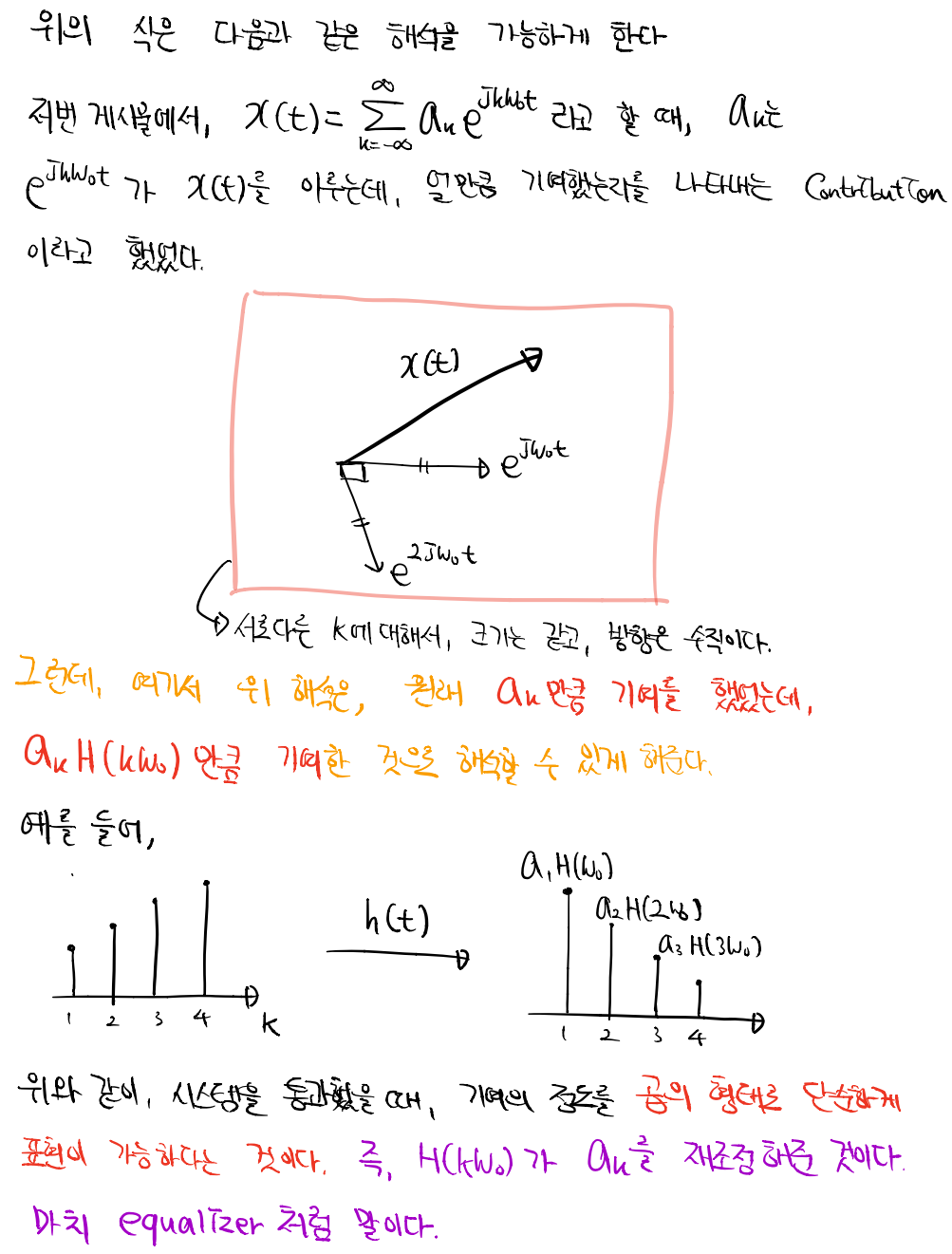
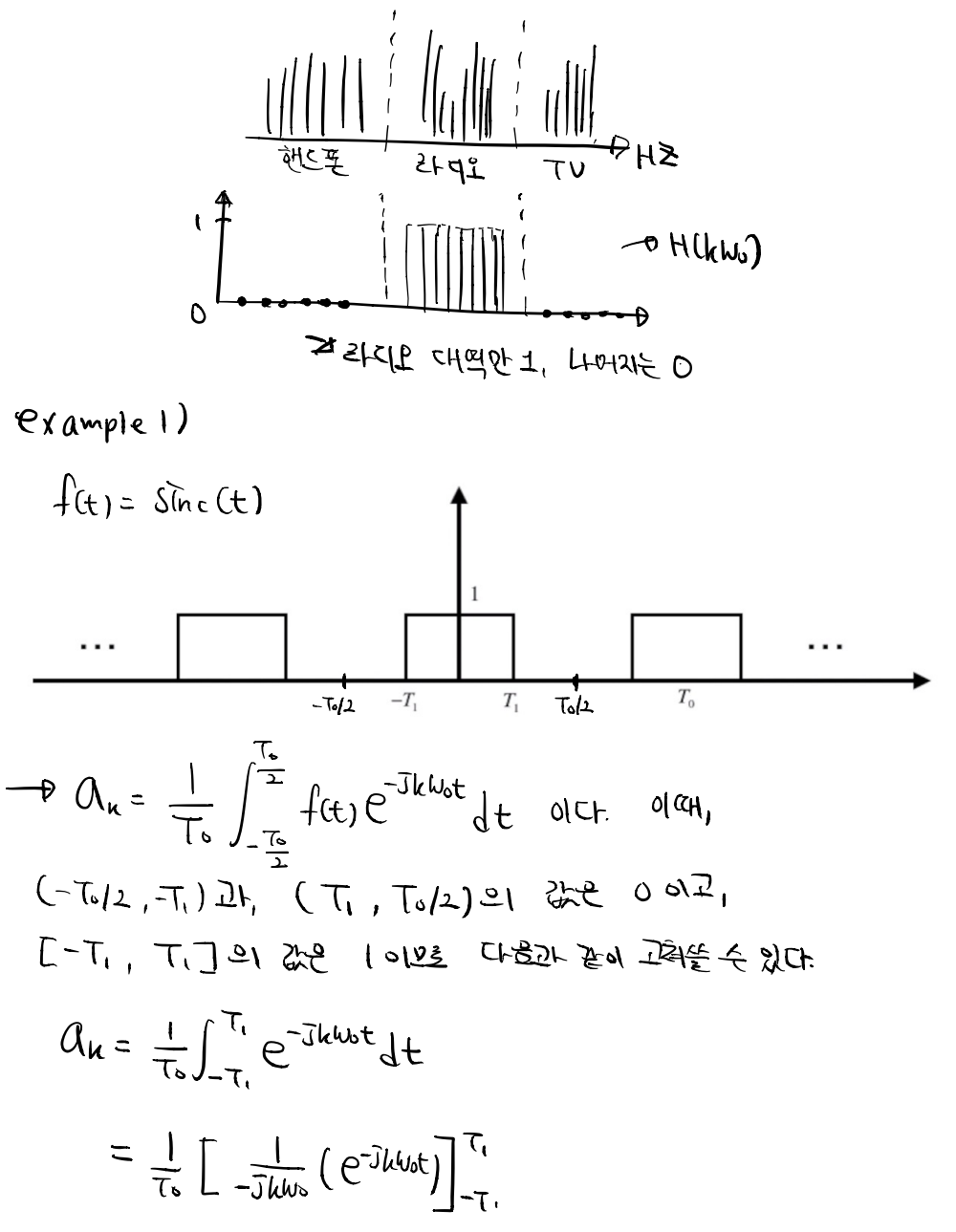
Signals and Systems-3.1 푸리에 복소정현파 왜 배울까
02 Mar 2020 | Signals and Systems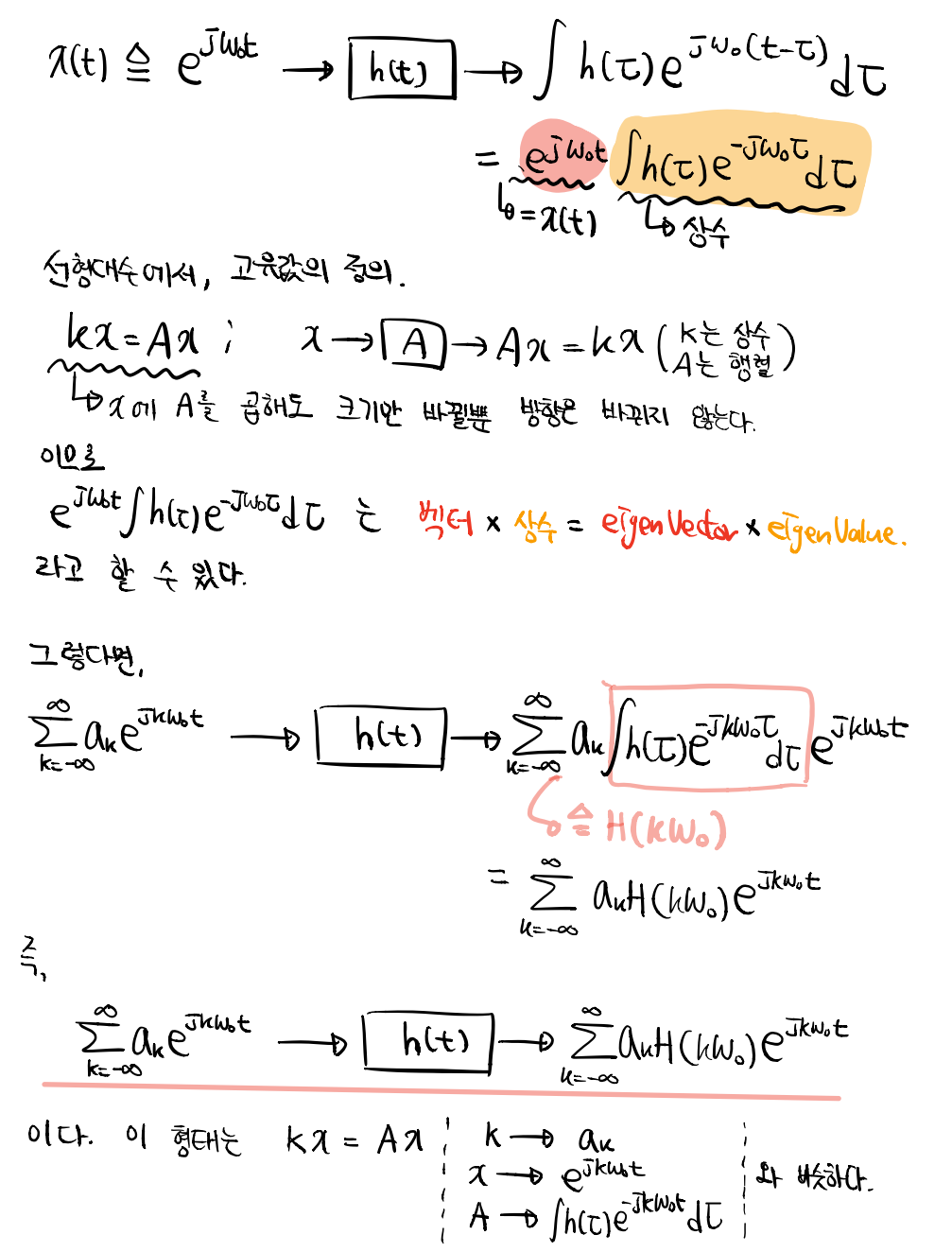



 Sunwoo Kim's Computer Vision, Machine & Deep Learning Blog
Sunwoo Kim's Computer Vision, Machine & Deep Learning Blog
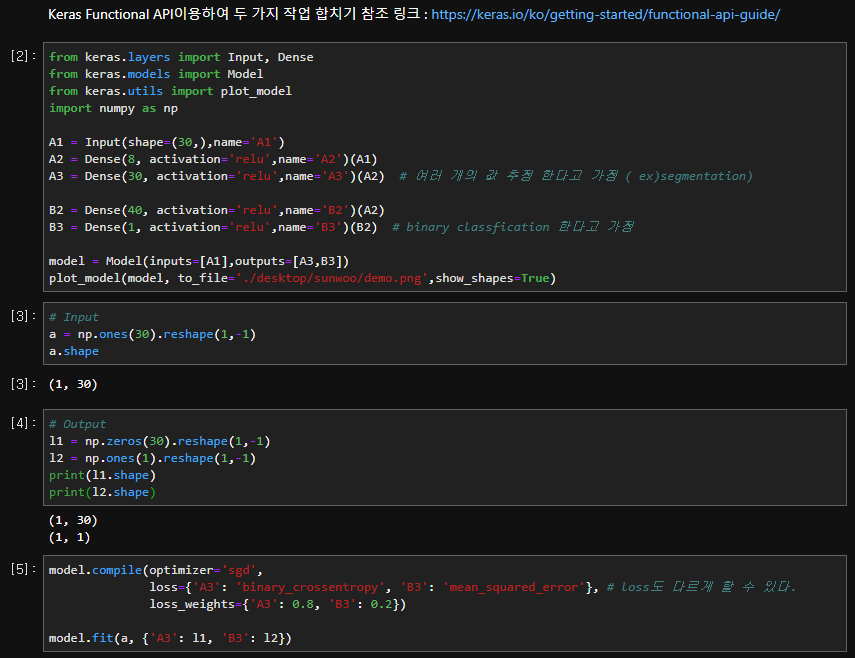
Keras를 사용하요 모델을 작성하다가 두 개 이상의 모델을 이용해야 할 경우가 생겼다. 예를들어 Segmentation과 Classfication을 동시에 학습시켜 성능을 측정해보는 이번 작업의 경우가 그러하였다. 그럴 경우에 유용할 수 있는 예제 코드를 documentation을 통해서 한 번 간단하게 실습해보았다.
Epoch 1/1
1/1 [==============================] - 2s 2s/step - loss: 0.3095 - A3_loss: 0.1675 - B3_loss: 0.8776
학습이 진행되는 모습을 볼 수 있다. 이렇게 두 가지 작업을, 각각 다른 loss함수로, 그리고 가중치까지 주어서 학습할 수 있다는 것을 보았다.
from keras.layers import Input, Dense
from keras.models import Model
from keras.utils import plot_model
import numpy as np
A1 = Input(shape=(30,),name='A1')
A2 = Dense(8, activation='relu',name='A2')(A1)
A3 = Dense(30, activation='relu',name='A3')(A2) # 여러 개의 값 추정 한다고 가정 ( ex)segmentation)
B2 = Dense(40, activation='relu',name='B2')(A2)
B3 = Dense(1, activation='relu',name='B3')(B2) # binary classfication 한다고 가정
model = Model(inputs=[A1],outputs=[A3,B3])
plot_model(model, to_file='./desktop/sunwoo/demo.png',show_shapes=True)
# Input
a = np.ones(30).reshape(1,-1)
a.shape
# Output
l1 = np.zeros(30).reshape(1,-1)
l2 = np.ones(1).reshape(1,-1)
print(l1.shape)
print(l2.shape)
model.compile(optimizer='sgd',
# loss도 다르게 할 수 있다.
loss={'A3': 'binary_crossentropy', 'B3': 'mean_squared_error'},
loss_weights={'A3': 0.8, 'B3': 0.2}) # Dictionary 형태로 접근
model.fit(a, {'A3': l1, 'B3': l2}) # Dictionary 형태로 접근
fit_generator를 이용하다가 불편한점이 하나 있었는데 그것은 바로 Segmentation되는 중간결과를 확인하지 못한다는 것이다. model.fit() 혹은 model.train_on_batch()를 사용하게 되면 직접 배치를 반환받아 그 값을 fit(X, Y), train_on_batch(X, Y)와 같은 방식으로 입력 받을 수 있기 때문에, X, Y, model.predict(X)의 값을 반환 받아서 중간중간에 Plotting 해볼 수 있다는 장점이 있는데, fit_generator는 그 안에서만 진행이 되기 때문에 중간중간에 prediction을 해볼 수 없다는 단점이 있습니다.
그래서 중간중간에 결과를 plotting해보기 위해서 github에 있는 keras의 fit_generator에 아주 간단한 코드를 추가하여 결과를 중간에 볼 수 있도록 할 수 있습니다.
Keras 공식 코드 를 참조해주세요. 실제 저희가 사용하는 부분과 똑같은 부분입니다. 해당 홈페이지에 들어가서 ctrl+F를 누르고 test_on_batch 를 검색해주세요. 그러면 test_on_batch부분이 사용된 부분을 찾을 수 있습니다. 그 부분을 집중적으로 보고 코드를 추가할 예정입니다.
364번째 줄에 while steps_done < steps 부분이 보이실 겁니다. 이 부분이 이하가 바로 step만큼 validation을 진행하는 부분입니다. 그래서 x,y 값을 부르고, 399번째 줄에서 test_on_batch가 실행되면서 validation batch에 대한 evaluation을 진행하게 됩니다. 그리고 그 부분을 아래와 같이 바꿔줍니다. (Segmentation 작업을 수행하여서 다음과 같이 결과를 plotting 했습니다.) 그리고 파일 상단에 import matplotlib.pyplot as plt코드를 넣어서 matplotlib을 import 해줍니다.
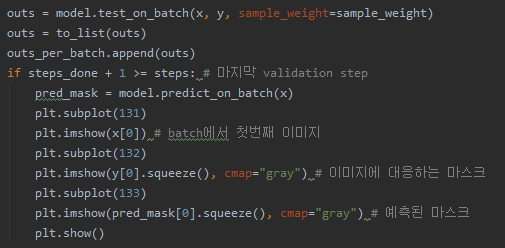
실제 적용하려면 현제 로컬에 저장된 경로에서 찾아야 되는데요 다음과 같은 경로에서 찾아보시면 됩니다.
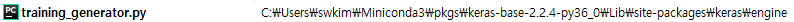
이 때, 적용해도 안 바뀔수가 있는데, 코드에서 작동되는 keras및 tensorflow가 진짜로 참조한는 py파일이 어떤 파일인지 잘 찾아보셔야 합니다. 가상환경을 사용하시는데, pubilc한 부분의 파일을 바꾸면 가상환경안에 있는 파일이 아니기 때문에 작동하지 않습니다.
이렇게 바꾸고, Spyder를 이용하여 코드를 돌리면 다음과 같이 결과를 출력할 수 있습니다.

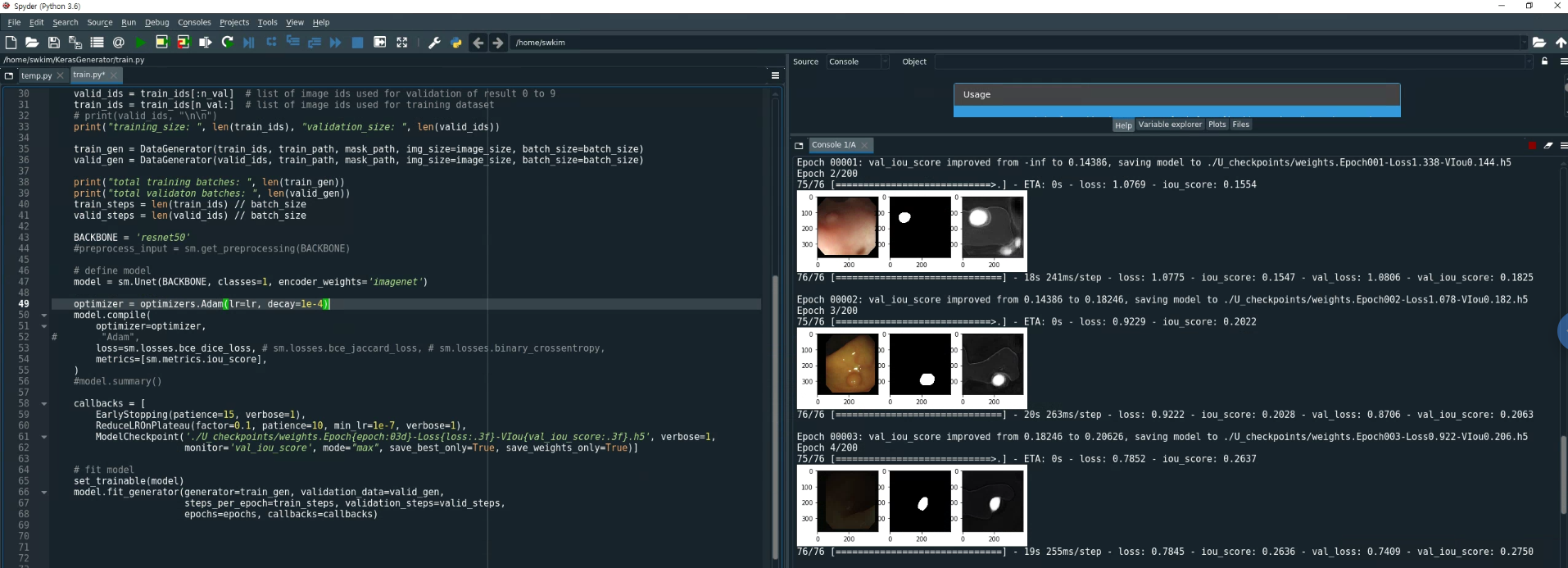
왼쪽부터 차례대로, 원본이미지, Ground Truth, Predicted Mask 입니다.
혹시몰라. 주변 부분의 코드를 보고 잘 찾아서 추가하시라고 전체코드를 첨부합니다. keras의 training_generator.py에 plotting하는 코드만 첨가한 코드입니다.
"""Part of the training engine related to Python generators of array data.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import warnings
import numpy as np
from .training_utils import iter_sequence_infinite
from .. import backend as K
from ..utils.data_utils import Sequence
from ..utils.data_utils import GeneratorEnqueuer
from ..utils.data_utils import OrderedEnqueuer
from ..utils.generic_utils import Progbar
from ..utils.generic_utils import to_list
from ..utils.generic_utils import unpack_singleton
from .. import callbacks as cbks
import matplotlib.pyplot as plt
def fit_generator(model,
generator,
steps_per_epoch=None,
epochs=1,
verbose=1,
callbacks=None,
validation_data=None,
validation_steps=None,
class_weight=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
shuffle=True,
initial_epoch=0):
"""See docstring for `Model.fit_generator`."""
wait_time = 0.01 # in seconds
epoch = initial_epoch
do_validation = bool(validation_data)
model._make_train_function()
if do_validation:
model._make_test_function()
is_sequence = isinstance(generator, Sequence)
if not is_sequence and use_multiprocessing and workers > 1:
warnings.warn(
UserWarning('Using a generator with `use_multiprocessing=True`'
' and multiple workers may duplicate your data.'
' Please consider using the`keras.utils.Sequence'
' class.'))
if steps_per_epoch is None:
if is_sequence:
steps_per_epoch = len(generator)
else:
raise ValueError('`steps_per_epoch=None` is only valid for a'
' generator based on the '
'`keras.utils.Sequence`'
' class. Please specify `steps_per_epoch` '
'or use the `keras.utils.Sequence` class.')
# python 2 has 'next', 3 has '__next__'
# avoid any explicit version checks
val_gen = (hasattr(validation_data, 'next') or
hasattr(validation_data, '__next__') or
isinstance(validation_data, Sequence))
if (val_gen and not isinstance(validation_data, Sequence) and
not validation_steps):
raise ValueError('`validation_steps=None` is only valid for a'
' generator based on the `keras.utils.Sequence`'
' class. Please specify `validation_steps` or use'
' the `keras.utils.Sequence` class.')
# Prepare display labels.
out_labels = model.metrics_names
callback_metrics = out_labels + ['val_' + n for n in out_labels]
# prepare callbacks
model.history = cbks.History()
_callbacks = [cbks.BaseLogger(
stateful_metrics=model.stateful_metric_names)]
if verbose:
_callbacks.append(
cbks.ProgbarLogger(
count_mode='steps',
stateful_metrics=model.stateful_metric_names))
_callbacks += (callbacks or []) + [model.history]
callbacks = cbks.CallbackList(_callbacks)
# it's possible to callback a different model than self:
if hasattr(model, 'callback_model') and model.callback_model:
callback_model = model.callback_model
else:
callback_model = model
callbacks.set_model(callback_model)
callbacks.set_params({
'epochs': epochs,
'steps': steps_per_epoch,
'verbose': verbose,
'do_validation': do_validation,
'metrics': callback_metrics,
})
callbacks.on_train_begin()
enqueuer = None
val_enqueuer = None
try:
if do_validation:
if val_gen and workers > 0:
# Create an Enqueuer that can be reused
val_data = validation_data
if isinstance(val_data, Sequence):
val_enqueuer = OrderedEnqueuer(
val_data,
use_multiprocessing=use_multiprocessing)
validation_steps = validation_steps or len(val_data)
else:
val_enqueuer = GeneratorEnqueuer(
val_data,
use_multiprocessing=use_multiprocessing)
val_enqueuer.start(workers=workers,
max_queue_size=max_queue_size)
val_enqueuer_gen = val_enqueuer.get()
elif val_gen:
val_data = validation_data
if isinstance(val_data, Sequence):
val_enqueuer_gen = iter_sequence_infinite(val_data)
validation_steps = validation_steps or len(val_data)
else:
val_enqueuer_gen = val_data
else:
# Prepare data for validation
if len(validation_data) == 2:
val_x, val_y = validation_data
val_sample_weight = None
elif len(validation_data) == 3:
val_x, val_y, val_sample_weight = validation_data
else:
raise ValueError('`validation_data` should be a tuple '
'`(val_x, val_y, val_sample_weight)` '
'or `(val_x, val_y)`. Found: ' +
str(validation_data))
val_x, val_y, val_sample_weights = model._standardize_user_data(
val_x, val_y, val_sample_weight)
val_data = val_x + val_y + val_sample_weights
if model.uses_learning_phase and not isinstance(K.learning_phase(),
int):
val_data += [0.]
for cbk in callbacks:
cbk.validation_data = val_data
if workers > 0:
if is_sequence:
enqueuer = OrderedEnqueuer(
generator,
use_multiprocessing=use_multiprocessing,
shuffle=shuffle)
else:
enqueuer = GeneratorEnqueuer(
generator,
use_multiprocessing=use_multiprocessing,
wait_time=wait_time)
enqueuer.start(workers=workers, max_queue_size=max_queue_size)
output_generator = enqueuer.get()
else:
if is_sequence:
output_generator = iter_sequence_infinite(generator)
else:
output_generator = generator
callback_model.stop_training = False
# Construct epoch logs.
epoch_logs = {}
while epoch < epochs:
for m in model.stateful_metric_functions:
m.reset_states()
callbacks.on_epoch_begin(epoch)
steps_done = 0
batch_index = 0
while steps_done < steps_per_epoch:
generator_output = next(output_generator)
if not hasattr(generator_output, '__len__'):
raise ValueError('Output of generator should be '
'a tuple `(x, y, sample_weight)` '
'or `(x, y)`. Found: ' +
str(generator_output))
if len(generator_output) == 2:
x, y = generator_output
sample_weight = None
elif len(generator_output) == 3:
x, y, sample_weight = generator_output
else:
raise ValueError('Output of generator should be '
'a tuple `(x, y, sample_weight)` '
'or `(x, y)`. Found: ' +
str(generator_output))
# build batch logs
batch_logs = {}
if x is None or len(x) == 0:
# Handle data tensors support when no input given
# step-size = 1 for data tensors
batch_size = 1
elif isinstance(x, list):
batch_size = x[0].shape[0]
elif isinstance(x, dict):
batch_size = list(x.values())[0].shape[0]
else:
batch_size = x.shape[0]
batch_logs['batch'] = batch_index
batch_logs['size'] = batch_size
callbacks.on_batch_begin(batch_index, batch_logs)
outs = model.train_on_batch(x, y,
sample_weight=sample_weight,
class_weight=class_weight)
outs = to_list(outs)
for l, o in zip(out_labels, outs):
batch_logs[l] = o
callbacks.on_batch_end(batch_index, batch_logs)
batch_index += 1
steps_done += 1
# Epoch finished.
if steps_done >= steps_per_epoch and do_validation:
if val_gen:
val_outs = model.evaluate_generator(
val_enqueuer_gen,
validation_steps,
workers=0)
else:
# No need for try/except because
# data has already been validated.
val_outs = model.evaluate(
val_x, val_y,
batch_size=batch_size,
sample_weight=val_sample_weights,
verbose=0)
val_outs = to_list(val_outs)
# Same labels assumed.
for l, o in zip(out_labels, val_outs):
epoch_logs['val_' + l] = o
if callback_model.stop_training:
break
callbacks.on_epoch_end(epoch, epoch_logs)
epoch += 1
if callback_model.stop_training:
break
finally:
try:
if enqueuer is not None:
enqueuer.stop()
finally:
if val_enqueuer is not None:
val_enqueuer.stop()
callbacks.on_train_end()
return model.history
def evaluate_generator(model, generator,
steps=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
verbose=0):
"""See docstring for `Model.evaluate_generator`."""
model._make_test_function()
if hasattr(model, 'metrics'):
for m in model.stateful_metric_functions:
m.reset_states()
stateful_metric_indices = [
i for i, name in enumerate(model.metrics_names)
if str(name) in model.stateful_metric_names]
else:
stateful_metric_indices = []
steps_done = 0
wait_time = 0.01
outs_per_batch = []
batch_sizes = []
is_sequence = isinstance(generator, Sequence)
if not is_sequence and use_multiprocessing and workers > 1:
warnings.warn(
UserWarning('Using a generator with `use_multiprocessing=True`'
' and multiple workers may duplicate your data.'
' Please consider using the`keras.utils.Sequence'
' class.'))
if steps is None:
if is_sequence:
steps = len(generator)
else:
raise ValueError('`steps=None` is only valid for a generator'
' based on the `keras.utils.Sequence` class.'
' Please specify `steps` or use the'
' `keras.utils.Sequence` class.')
enqueuer = None
try:
if workers > 0:
if is_sequence:
enqueuer = OrderedEnqueuer(
generator,
use_multiprocessing=use_multiprocessing)
else:
enqueuer = GeneratorEnqueuer(
generator,
use_multiprocessing=use_multiprocessing,
wait_time=wait_time)
enqueuer.start(workers=workers, max_queue_size=max_queue_size)
output_generator = enqueuer.get()
else:
if is_sequence:
output_generator = iter_sequence_infinite(generator)
else:
output_generator = generator
if verbose == 1:
progbar = Progbar(target=steps)
while steps_done < steps:
generator_output = next(output_generator)
if not hasattr(generator_output, '__len__'):
raise ValueError('Output of generator should be a tuple '
'(x, y, sample_weight) '
'or (x, y). Found: ' +
str(generator_output))
if len(generator_output) == 2:
x, y = generator_output
sample_weight = None
elif len(generator_output) == 3:
x, y, sample_weight = generator_output
else:
raise ValueError('Output of generator should be a tuple '
'(x, y, sample_weight) '
'or (x, y). Found: ' +
str(generator_output))
outs = model.test_on_batch(x, y, sample_weight=sample_weight)
outs = to_list(outs)
outs_per_batch.append(outs)
if steps_done + 1 >= steps: # 마지막 validation step
pred_mask = model.predict_on_batch(x)
plt.subplot(131)
plt.imshow(x[0]) # batch에서 첫번째 이미지
plt.subplot(132)
plt.imshow(y[0].squeeze(), cmap="gray") # 이미지에 대응하는 마스크
plt.subplot(133)
plt.imshow(pred_mask[0].squeeze(), cmap="gray") # 예측된 마스크
plt.show()
if x is None or len(x) == 0:
# Handle data tensors support when no input given
# step-size = 1 for data tensors
batch_size = 1
elif isinstance(x, list):
batch_size = x[0].shape[0]
elif isinstance(x, dict):
batch_size = list(x.values())[0].shape[0]
else:
batch_size = x.shape[0]
if batch_size == 0:
raise ValueError('Received an empty batch. '
'Batches should contain '
'at least one item.')
steps_done += 1
batch_sizes.append(batch_size)
if verbose == 1:
progbar.update(steps_done)
finally:
if enqueuer is not None:
enqueuer.stop()
averages = []
for i in range(len(outs)):
if i not in stateful_metric_indices:
averages.append(np.average([out[i] for out in outs_per_batch],
weights=batch_sizes))
else:
averages.append(np.float64(outs_per_batch[-1][i]))
return unpack_singleton(averages)
def predict_generator(model, generator,
steps=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
verbose=0):
"""See docstring for `Model.predict_generator`."""
model._make_predict_function()
steps_done = 0
wait_time = 0.01
all_outs = []
is_sequence = isinstance(generator, Sequence)
if not is_sequence and use_multiprocessing and workers > 1:
warnings.warn(
UserWarning('Using a generator with `use_multiprocessing=True`'
' and multiple workers may duplicate your data.'
' Please consider using the`keras.utils.Sequence'
' class.'))
if steps is None:
if is_sequence:
steps = len(generator)
else:
raise ValueError('`steps=None` is only valid for a generator'
' based on the `keras.utils.Sequence` class.'
' Please specify `steps` or use the'
' `keras.utils.Sequence` class.')
enqueuer = None
try:
if workers > 0:
if is_sequence:
enqueuer = OrderedEnqueuer(
generator,
use_multiprocessing=use_multiprocessing)
else:
enqueuer = GeneratorEnqueuer(
generator,
use_multiprocessing=use_multiprocessing,
wait_time=wait_time)
enqueuer.start(workers=workers, max_queue_size=max_queue_size)
output_generator = enqueuer.get()
else:
if is_sequence:
output_generator = iter_sequence_infinite(generator)
else:
output_generator = generator
if verbose == 1:
progbar = Progbar(target=steps)
while steps_done < steps:
generator_output = next(output_generator)
if isinstance(generator_output, tuple):
# Compatibility with the generators
# used for training.
if len(generator_output) == 2:
x, _ = generator_output
elif len(generator_output) == 3:
x, _, _ = generator_output
else:
raise ValueError('Output of generator should be '
'a tuple `(x, y, sample_weight)` '
'or `(x, y)`. Found: ' +
str(generator_output))
else:
# Assumes a generator that only
# yields inputs (not targets and sample weights).
x = generator_output
outs = model.predict_on_batch(x)
outs = to_list(outs)
if not all_outs:
for out in outs:
all_outs.append([])
for i, out in enumerate(outs):
all_outs[i].append(out)
steps_done += 1
if verbose == 1:
progbar.update(steps_done)
finally:
if enqueuer is not None:
enqueuer.stop()
if len(all_outs) == 1:
if steps_done == 1:
return all_outs[0][0]
else:
return np.concatenate(all_outs[0])
if steps_done == 1:
return [out[0] for out in all_outs]
else:
return [np.concatenate(out) for out in all_outs]
논문을 보고 모델을 구현할 때 가장 시간이 많이 드는 것은 아무래도 레이어를 쌓아서 모델구조를 만드는것 보다 데이터를 로드하여 배치를 짜는 부분을 만들고, backward하는 부분과 evaluation하는 부분이라고 생각이 듭니다. 여태까지 이미지를 다룰 때 Numpy 라이브러리만을 이용해서 데이터를 다루었었는데요, Keras를 이용할 때, keras에 존재하는 기능을 이용하여 데이터 로드하는 부분을 구현하니 매우 간편한거 같습니다. 인터넷에서도 많은 분들이 다루어 주셨기 때문에 공부하는데 그 글들을 많이 참고하였습니다. 이번에는 제가 구현한 부분에 대해서 말씀 드리고자 합니다.
첫번째로 케라스의 keras.utils.Sequence 를 상속받아 generator를 구현하여 사용하는 방법입니다. 기본적으로 keras.utils.Seuence에 abtstractMethod로 구현되어 있는 부분을 구현하여 사용합니다. 구조는 아래와 같습니다.
class DataGenerator(keras.utils.Sequence): # 클래스 명은 꼭 DataGenerator가 아니여도 됨
def __init__(self, *args)
def on_epoch_end(self)
def __len__(self)
def __getitem__(self, index)
각 기능은 아래와 같습니다.
import os #for accessing the file system of the system
import random
from skimage import io
from skimage.transform import resize
import numpy as np
import keras
# data generator class
class DataGenerator(keras.utils.Sequence):
def __init__(self, ids, imgs_dir, masks_dir, batch_size=10, img_size=128, n_classes=1, n_channels=3, shuffle=True):
self.id_names = ids
self.indexes = np.arange(len(self.id_names))
self.imgs_dir = imgs_dir
self.masks_dir = masks_dir
self.batch_size = batch_size
self.img_size = img_size
self.n_classes = n_classes
self.n_channels = n_channels
self.shuffle = shuffle
self.on_epoch_end()
# for printing the statistics of the function
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.id_names))
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __data_generation__(self, id_name):
'Generates data containing batch_size samples'
# Initialization
img_path = os.path.join(self.imgs_dir, id_name) # 이미지 1개 경로
mask_path = os.path.join(self.masks_dir, id_name) # 마스크 1개 경로
img = io.imread(img_path)
mask = cv2.imread(mask_path)
# image normalization
image = image / 255.0
mask = mask / 255.0
return image, mask
def __len__(self):
"Denotes the number of batches per epoch"
# self.id_names: 존재하는 총 이미지 개수를 의미합니다.
# self.batch_size: 배치사이즈를 의미합니다.
return int(np.floor(len(self.id_names) / self.batch_size))
def __getitem__(self, index): # index : batch no.
# Generate indexes of the batch
indexes = self.indexes[index * self.batch_size:(index + 1) * self.batch_size]
batch_ids = [self.id_names[k] for k in indexes]
imgs = list()
masks = list()
for id_name in batch_ids:
img, mask = self.__data_generation__(id_name)
imgs.append(img)
masks.append(np.expand_dims(mask,-1))
imgs = np.array(imgs)
masks = np.array(masks)
return imgs, masks # return batch
구조를 간략하게 말씀드리자면 다음과 같습니다. 클래스를 생성할 때, init이 호출되어 클래스내의 멤버변수를 초기화 합니다. 그리고 len함수에 return되는 길이값을 보시면 이미지개수를 배치수로 나누어, 한 epoch내에 존재할 수 있는 배치수를 길이로 반환하게 됩니다. 그리고 최종적으로 getitem에서 배치를 반환하게 됩니다. 여기서 제가 수행하려는 작업은 image sgementation 작업이여서 이미지와 정답인 마스크를 불러와서 배치로 만드는 작업이 필요한데 해당작업을 data_generation함수에서 수행하였습니다.
getitem함수를 보시면, 함수 인자에 index가 있는 모습을 볼 수 있습니다 이 인덱스는 range(0, len) 사이의 인덱스가 차례대로 반환된 값입니다. 그래서 해당 인덱스를 참조하여, 해당 인덱스에 해당하는 이미지와 마스크를 배치사이즈 만큼 불러들여 배치를 생성하게 합니다.
그러면 제가 작성한 train code를 첨가하여 최종적인 설명을 하도록 하겠습니다.
import os # for accessing the file system of the system
from keras import optimizers
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
import segmentation_models as sm
from segmentation_models.utils import set_trainable
from dataset import DataGenerator
if __name__ == '__main__':
# hyperparameter
image_size = 384
train_path = './data/train/imgs/' # 이미지 파일들의 경로
mask_path = './data/train/masks/' # 마스크 파일들의 경로
epochs = 50 # number of time we need to train dataset
lr = 1e-5
batch_size = 2 # tarining batch size
# train path
train_ids = os.listdir(train_path) #[1.jpg, 2.jpg .....]
# Validation Data Size
val_data_size = 69 # size of set of images used for the validation
valid_ids = train_ids[:val_data_size] #[1.jpg, 2.jpg, ... 69.jpg]
train_ids = train_ids[val_data_size:] #[70.jpg, 71.jpg, ... n.jpg]
# train, validation Datagenerator 클래스를 각각 생성합니다.
train_gen = DataGenerator(train_ids, train_path, mask_path, img_size=image_size, batch_size=batch_size)
valid_gen = DataGenerator(valid_ids, train_path, mask_path, img_size=image_size, batch_size=batch_size)
# 여기서 ids, train_path, mask_path는 os.path.join(id, train_path)이런 식으로 경로로 결합하여, 최종적인 이미지의 경로가 됩니다. 이 경로는 앞서 구현한 DataGenerator클래스에서 이미지와 마스크를 불러들이는데 사용됩니다.
print("total training batches: ", len(train_gen))
print("total validaton batches: ", len(valid_gen))
train_steps = len(train_ids) // batch_size
valid_steps = len(valid_ids) // batch_size
BACKBONE = 'resnet34'
#preprocess_input = sm.get_preprocessing(BACKBONE)
# define model
model = sm.Unet(BACKBONE, encoder_weights='imagenet')
optimizer = optimizers.Adam(lr=lr, decay=1e-5)
model.compile(
optimizer=optimizer,
loss=sm.losses.bce_dice_loss,
metrics=[sm.metrics.iou_score],
)
# fit model
set_trainable(model)
model.fit_generator(generator=train_gen, validation_data=valid_gen,
steps_per_epoch=train_steps, validation_steps=valid_steps,
epochs=epochs)
코드는 위와 같습니다. 즉, train하는 부분에서 image와 label의 경로들의 리스트를 만들어 주고 그 값을 Datagernator의 인자로 넣어서, Datagernator에서는 그 경로를 참조하여 이미지와 레이블을 불러온 후, 배치로 반환하는 역할을 하게 코드를 작성합니다. 그리고 그 DataGenerator 객테를 fit_generator 함수에 인자로 넣으면 훈련이 진행되게 됩니다.
layout: post title: Keras-Batch생성하기1-(Sequence & fit_generator) author: Sunwoo Kim categories: Frameworks tags: [Keras]
논문을 보고 모델을 구현할 때 가장 시간이 많이 드는 것은 아무래도 레이어를 쌓아서 모델구조를 만드는것 보다 데이터를 로드하여 배치를 짜는 부분을 만들고, backward하는 부분과 evaluation하는 부분이라고 생각이 듭니다. 여태까지 이미지를 다룰 때 Numpy 라이브러리만을 이용해서 데이터를 다루었었는데요, Keras를 이용할 때, keras에 존재하는 기능을 이용하여 데이터 로드하는 부분을 구현하니 매우 간편한거 같습니다. 인터넷에서도 많은 분들이 다루어 주셨기 때문에 공부하는데 그 글들을 많이 참고하였습니다. 이번에는 제가 구현한 부분에 대해서 말씀 드리고자 합니다.
첫번째로 케라스의 keras.utils.Sequence 를 상속받아 generator를 구현하여 사용하는 방법입니다. 기본적으로 keras.utils.Seuence에 abtstractMethod로 구현되어 있는 부분을 구현하여 사용합니다. 구조는 아래와 같습니다.
class DataGenerator(keras.utils.Sequence): # 클래스 명은 꼭 DataGenerator가 아니여도 됨
def __init__(self, *args)
def on_epoch_end(self)
def __len__(self)
def __getitem__(self, index)
각 기능은 아래와 같습니다.
import os #for accessing the file system of the system
import random
from skimage import io
from skimage.transform import resize
import numpy as np
import keras
# data generator class
class DataGenerator(keras.utils.Sequence):
def __init__(self, ids, imgs_dir, masks_dir, batch_size=10, img_size=128, n_classes=1, n_channels=3, shuffle=True):
self.id_names = ids
self.indexes = np.arange(len(self.id_names))
self.imgs_dir = imgs_dir
self.masks_dir = masks_dir
self.batch_size = batch_size
self.img_size = img_size
self.n_classes = n_classes
self.n_channels = n_channels
self.shuffle = shuffle
self.on_epoch_end()
# for printing the statistics of the function
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.id_names))
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __data_generation__(self, id_name):
'Generates data containing batch_size samples'
# Initialization
img_path = os.path.join(self.imgs_dir, id_name) # 이미지 1개 경로
mask_path = os.path.join(self.masks_dir, id_name) # 마스크 1개 경로
img = io.imread(img_path)
mask = cv2.imread(mask_path)
# image normalization
image = image / 255.0
mask = mask / 255.0
return image, mask
def __len__(self):
"Denotes the number of batches per epoch"
# self.id_names: 존재하는 총 이미지 개수를 의미합니다.
# self.batch_size: 배치사이즈를 의미합니다.
return int(np.floor(len(self.id_names) / self.batch_size))
def __getitem__(self, index): # index : batch no.
# Generate indexes of the batch
indexes = self.indexes[index * self.batch_size:(index + 1) * self.batch_size]
batch_ids = [self.id_names[k] for k in indexes]
imgs = list()
masks = list()
for id_name in batch_ids:
img, mask = self.__data_generation__(id_name)
imgs.append(img)
masks.append(np.expand_dims(mask,-1))
imgs = np.array(imgs)
masks = np.array(masks)
return imgs, masks # return batch
구조를 간략하게 말씀드리자면 다음과 같습니다. 클래스를 생성할 때, init이 호출되어 클래스내의 멤버변수를 초기화 합니다. 그리고 len함수에 return되는 길이값을 보시면 이미지개수를 배치수로 나누어, 한 epoch내에 존재할 수 있는 배치수를 길이로 반환하게 됩니다. 그리고 최종적으로 getitem에서 배치를 반환하게 됩니다. 여기서 제가 수행하려는 작업은 image sgementation 작업이여서 이미지와 정답인 마스크를 불러와서 배치로 만드는 작업이 필요한데 해당작업을 data_generation함수에서 수행하였습니다.
getitem함수를 보시면, 함수 인자에 index가 있는 모습을 볼 수 있습니다 이 인덱스는 range(0, len) 사이의 인덱스가 차례대로 반환된 값입니다. 그래서 해당 인덱스를 참조하여, 해당 인덱스에 해당하는 이미지와 마스크를 배치사이즈 만큼 불러들여 배치를 생성하게 합니다.
그러면 제가 작성한 train code를 첨가하여 최종적인 설명을 하도록 하겠습니다.
import os # for accessing the file system of the system
from keras import optimizers
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
import segmentation_models as sm
from segmentation_models.utils import set_trainable
from dataset import DataGenerator
if __name__ == '__main__':
# hyperparameter
image_size = 384
train_path = './data/train/imgs/' # 이미지 파일들의 경로
mask_path = './data/train/masks/' # 마스크 파일들의 경로
epochs = 50 # number of time we need to train dataset
lr = 1e-5
batch_size = 2 # tarining batch size
# train path
train_ids = os.listdir(train_path) #[1.jpg, 2.jpg .....]
# Validation Data Size
val_data_size = 69 # size of set of images used for the validation
valid_ids = train_ids[:val_data_size] #[1.jpg, 2.jpg, ... 69.jpg]
train_ids = train_ids[val_data_size:] #[70.jpg, 71.jpg, ... n.jpg]
# train, validation Datagenerator 클래스를 각각 생성합니다.
train_gen = DataGenerator(train_ids, train_path, mask_path, img_size=image_size, batch_size=batch_size)
valid_gen = DataGenerator(valid_ids, train_path, mask_path, img_size=image_size, batch_size=batch_size)
# 여기서 ids, train_path, mask_path는 os.path.join(id, train_path)이런 식으로 경로로 결합하여, 최종적인 이미지의 경로가 됩니다. 이 경로는 앞서 구현한 DataGenerator클래스에서 이미지와 마스크를 불러들이는데 사용됩니다.
print("total training batches: ", len(train_gen))
print("total validaton batches: ", len(valid_gen))
train_steps = len(train_ids) // batch_size
valid_steps = len(valid_ids) // batch_size
BACKBONE = 'resnet34'
#preprocess_input = sm.get_preprocessing(BACKBONE)
# define model
model = sm.Unet(BACKBONE, encoder_weights='imagenet')
optimizer = optimizers.Adam(lr=lr, decay=1e-5)
model.compile(
optimizer=optimizer,
loss=sm.losses.bce_dice_loss,
metrics=[sm.metrics.iou_score],
)
# fit model
set_trainable(model)
model.fit_generator(generator=train_gen, validation_data=valid_gen,
steps_per_epoch=train_steps, validation_steps=valid_steps,
epochs=epochs)
코드는 위와 같습니다. 즉, train하는 부분에서 image와 label의 경로들의 리스트를 만들어 주고 그 값을 Datagernator의 인자로 넣어서, Datagernator에서는 그 경로를 참조하여 이미지와 레이블을 불러온 후, 배치로 반환하는 역할을 하게 코드를 작성합니다. 그리고 그 DataGenerator 객테를 fit_generator 함수에 인자로 넣으면 훈련이 진행되게 됩니다.