Differential Operators
22 Mar 2020 | Mathematics이미지 처리 분야, 딥러닝분야 등을 공부하다 보면 미분연산자에 관한 내용이 많이 나오는것 같습니다. 그래서 오늘은 그에 관한 내용을 참고용으로 간단하게 정리하고자 합니다. 위키피디아와 다른 분들이 써두신 글을 많이 참고하였습니다.
Gradient
Gradient 저는 그라디언트 혹은 그레디언트라고 읽습니다. 그라디언트는 스칼라장의 편도함수벡터 로써, 벡터의 일종입니다. 그라디언트는 다음과 같이 정의됩니다.
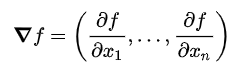
그라디언트는 한 점에서 어느 방향으로 함수가 가장 급격하게 값이 변하는지 나타내어주는 벡터입니다. 단, 그 방향으로 함수의 값이 줄어들고 있는 방향이라면 그라디언트는 180도 회전한 방향을 가리킨다.
스칼라장과 벡터장(Scalar field & Vector field)
스칼라장과 벡터장을 간단하게 이렇게 생각하면 좋을것 같습니다. 우리가 초,중,고등학교 때 배워온 모든 함수는 스칼라장입니다. 즉, f(x,y)에 f(x=3,y=2) = 5 와 같이 x,y,z 등 의 변수에 값을 대입하면, 상수가 나오는 형태입니다.이러한 크기값을 나타내는 값을 스칼라라고 하며, 스칼라장인 이유는 스칼라값들이 퍼져있기 때문입니다. 게임에서 골렘만 나오는 맵이 있으면, 골렘맵, 골렘필드 라고 하는것과 똑같을 까요??
벡터장은 스칼라장과는 다르게, x,y,z등의 변수에 값을 대입하면 벡터가 나오는 형태입니다. 위의 <그림1>을 예시로 들어보면, 스칼라장인 함수를 각각의 변수로 편미분한 값을 각 좌표의 값으로 결과를 내놓는 모습을 볼 수 있습니다. 위에서 얘기한 것과 같이, 스칼라 함수는 값을 대입하면 값이 나오고, 벡터함수는 값을 대입하면 벡터가 나오는데, 이것은 벡터가 나오는 형태입니다. 그러므로 모든 점에 대한 그레디언트를 모아두면 벡터장이라고 할 수 있습니다. 그래서 그라디언트를 웹상에 검색하면, 좌표평면에 화살표들이 있는 그림들을 나타낸 것을 볼 수 있는데, 이것이 벡터장을 표현한 겁니다.
Jacobian
자코비언이라 읽기도하고, 야코비언이라 읽기도 합니다. 그라디언트가 스칼라장의 편도함수 벡터라면, 자코비언은 다변수 벡터함수의 편도함수 행렬 입니다. 정의는 밑에 그림과 같습니다.
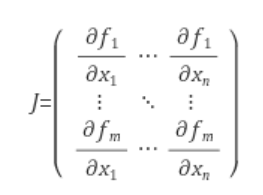
벡터함수는 위에 나왔던 그라디언트가 벡터함수의 일종이라고 할 수 있습니다. 간단한 예로 스칼라함수와 벡터함수를 예를 들어보겠습니다.
- 스칼라함수: $ f(x,y) = x^2 + y^2$
- 벡터함수: $ f(x,y) = <xy^2, cosx siny >$
즉 자코비언은 이러한 벡터함수에 대해서 각 축에 대응하는 함수를, 다른 변수들에 대한 편도함수에 대한 행렬이라고 볼 수 있습니다. 그러므로, 위 <그림2>에서 $f_1$은 $xy^2$이 되고, $x, y$각각에 대해서 편미분한 값이 첫번째 행에 들어가게 됩니다.
Laplacian
라플라시안이라고 읽습니다. 라플라시안은 Divergence of Gradient(그라디언트의 발산)입니다. 그러므로, 스칼라장의 일종입니다. 밑에 그림은 라플라시안의 정의입니다.
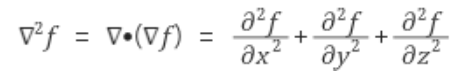
즉, 스칼라함수 f에 대한 이계편도함수들의 합으로 나타내어 집니다. 그런데, 위에서 라플라시안은 그라디언트의 발산이라고 하였습니다. 그라디언트에 대해서는 위에서 말했었습니다. 그렇다면 발산(Divergence)에 대해서도 무엇인지 알아봐야 하겠습니다.
divergence(발산)
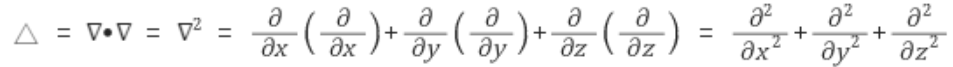
발산은 단위면적으로부터 벡터의 유입정도와 유출정도의 양을 나타내어주는 지표입니다. 그래서 divergence가 0이면 유출정도와 유입정도가 동일하다는 뜻이므로, 그라디언트의 변화가 없는것을 뜻합니다. 그리고 0보다 크다면 유출량이 더 많은 발산, 0보다 작으면 유입량이 더 많은 수렴을 의미하게 됩니다.
예를들어 일차미분 값이 속도라면 divergence는 해당 지점에서 가속도를 의미하게 됩니다. 왜냐하면 유입량은 이전 속도, 유출량은 이후 속도라고 하면, 속도의 변화 즉 가속도이기 때문입니다.
이미지에서는 이미지 픽셀 강도(intensity)의 차이가 위 설명의 그라디언트에 해당하고, divergence는 그라디언트의 차이를 의미하므로, 픽셀 강도차이의 변화라고 할 수 있습니다. 그러므로 단순하게 강도의 차이만 가지고 엣지여부를 판단하는 1차미분 필터들보다. 엣지에 덜 민감하며 더 얇은 엣지를 검출하게 됩니다.
Hessian
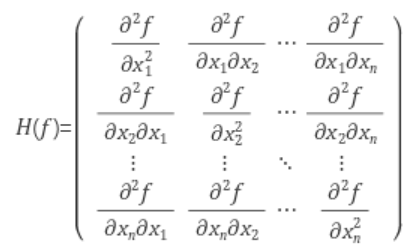
저는 헤이시안 이라고 읽습니다. 헤이시안은 자코비언과 형태가 비슷한데 다른점은, 자코비언이 일차미분값이라면 헤이시안은 이차미분 값입니다. 헤이시안은 많은 부분에서 이용되기 때문에 알아두면 좋습니다.
기본적으로 헤이시안과 자코비언은 대칭행렬(Symmetric matrix)이기 때문에, 행렬연산에서 대칭행렬의 성질을 이용하게 됩니다.
- $A^T = A$
- $A=S\Lambda S^-1$ 이때, S는 고유벡터의 행렬, $\Lambda$는 고유값의 대각행렬이다. 그럴 때, 행렬 A가 대칭행렬이라면, 대칭행렬의 서로다른 고유벡터는 서로 직교 하므로, 직교행렬의 성질 $Q^T = Q^-1$을 이용하자. S는 직교행렬 이므로, 최종적으로 $A = S\Lambda S^T$라고 할 수 있다.
Hessian은 이차미분의 행렬이므로 계산량이 많아서 되도록 다른 방법이 있다면 다른 방법이 많이 이용된다고 한다.
References
- wikipedia