

CS231n-Lecture11(Detection and Segmentation)
25 Aug 2020 | CS231n목차
- Introduction
- Semantic Segmentation
- Classification + Localization
- Object detection
- Instance Segmentation
저번 강의 때는 RNN모델에 대해서 학습했었다.

오늘은 CNN을 이용한 computer vison분야 중 하나인 segmentation, localization, detection에 대해서 배워보도록 하겠다.
Introduction
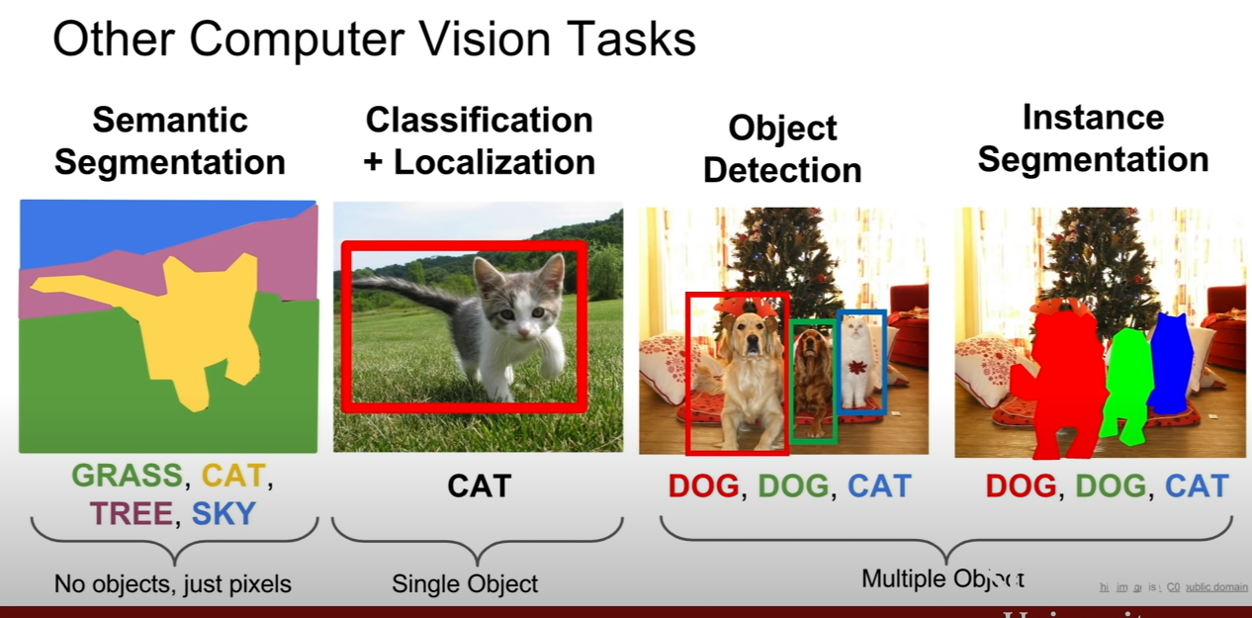
classification, localization, detection, segmentation간의 관계는 위 슬라이드와 같다.
의미론적 분할(semantic segmentation)은 이미지의 분할을 클래스에 따라서 수행하는 것이다. 즉, 어느 픽셀이 고양이 인지, 나무 인지, 하늘인지 구별하는 것이다.
슬라이드의 두 번째 사진은, 단일 물체에 대해서 분류 및 위치를 잡아주는 작업을 수행하는 것이다. 이게 다중 객체로 늘어나게 되면, 물체 탐지(object detection)이 된다. 그리고 localization과 contable object에 관한 semantic segmentation을 합하면 instance segmentation이 된다.
Semantic Segmentation
Fully convolution
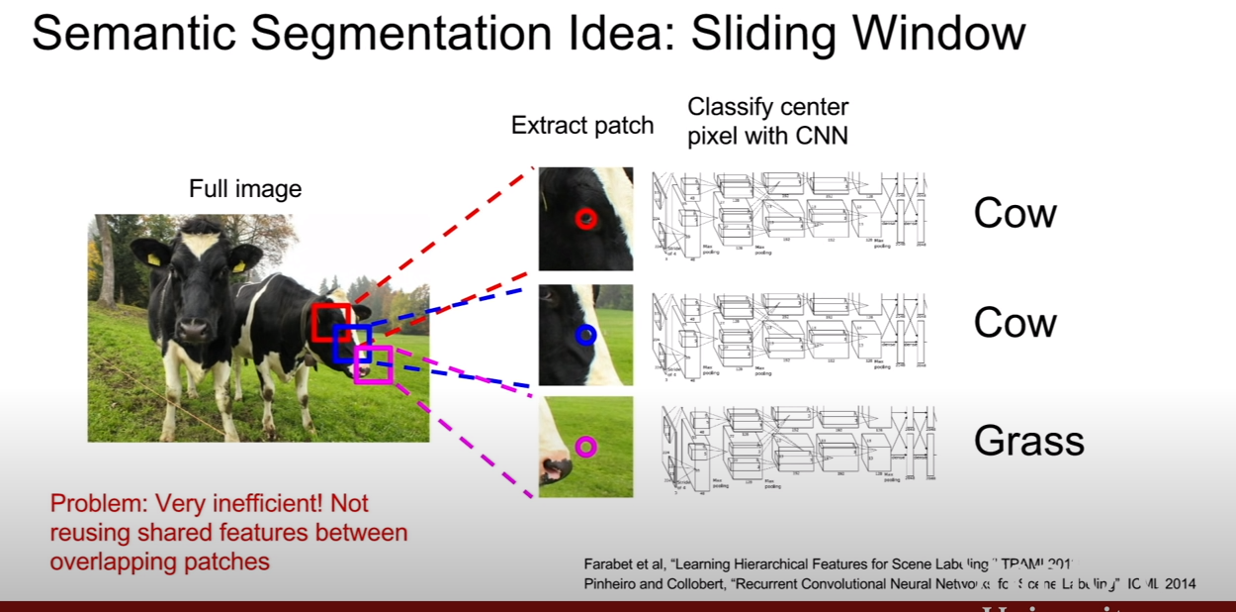
위 슬라이드와 같이 소 머리 주변에 패치들을 추출해서 semantic segmentation을 해본다고 하자. 왜냐하면 패치별로 겹치는 부분이 있으며, 이런방식으로 해서 모든 구역의 픽셀에 클래스 레이블링을 하려고 하면 매우 computationaly expensive일 것이다.
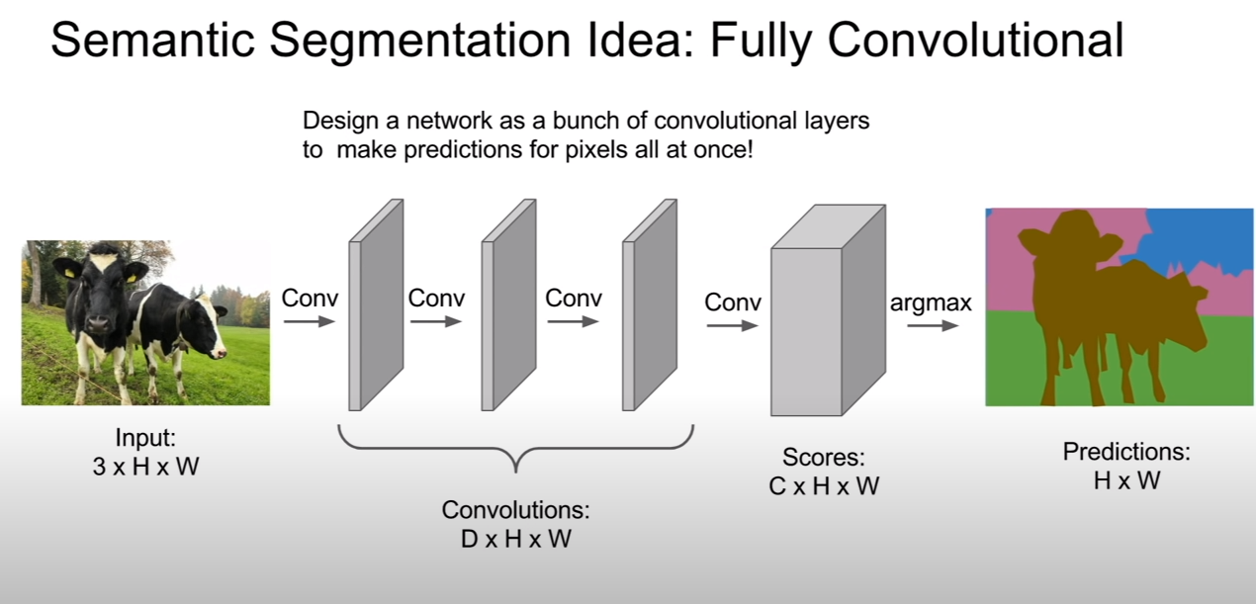
이것보다 좋은 방법으로 fully convolution이란 방법이 있다. 즉, 우리가 배웠었던 classification을 위한 네트워크에서는 마지막 부분이 FC layer로 구성되어 있었는데, segmentation을 위해서는 convolutional layer로 구성하는 것이다. 왜냐하면 이렇게 하는 데에는 이유가 있는데, 바로 local information을 잊지 않기 위해서이다. 위 슬라이드에서는 Channel의 개수 = class개수 라고 생각하면 된다. 즉 한 channel당 해당 위치의 픽셀이 한 클래스일 확률을 표시한다고 생각하면 된다.
로스를 구하는 과정도 픽셀단위의 분류이기 때문에, 픽셀 단위로 구해진다. 그렇기 때문에, classification에 비해서 computational cost가 더 많이 든다고 보면 된다.
이를 supervised learning을 위해서 역시 pixel 단위의 labeling이 필요한데 보통 사람들이 툴을 만들어서 많이 한다고 한다. 직접 하는 경우도 있다. 이 역시 아주아주 노동집약적이며, 비용이 많이든다.
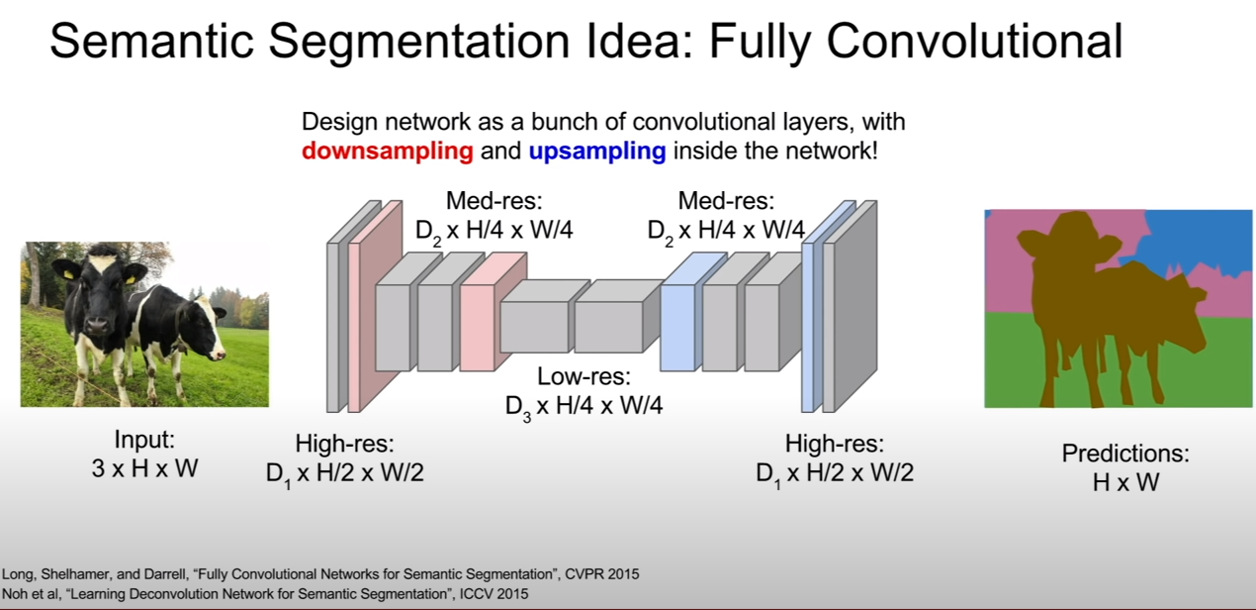
구조를 더 자세히 뜯어보면, 다음과 같이 생겼다. 앞단에서 convolution을 조금 한 후, 그 후부터 convolution, max pooling을 통하여 downsampling을 한 후, upsampling을 통하여 spatial resolution을 다시 키운다. 이렇게 하면 계산의 효율이 좋아지고, lower resolution을 처리할 수 있도록 네트워크를 더 깊게 만들 수도 있다.
Upsampling
그렇다면 upsampling은 어떻게 진행될까? 그 방법들을 살펴보자
Nearest Neighbor & Bed of Nails
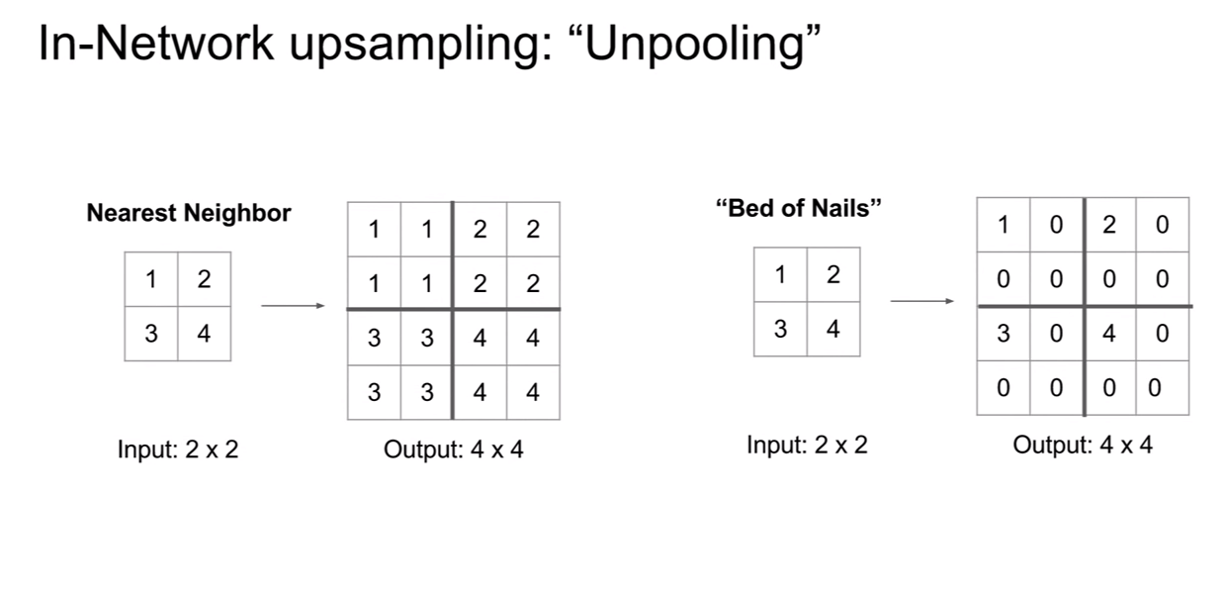
위 슬라이드에는 두 가지 방법이 제시되어있다. 우선 2x2 grid가 4x4 gride로 upsampling 된 것을 기억하자. 두 방법의 접근은 아주 간단하다. nearest neighbor는 해당하는 receiptive field에 그 값을 그대로 복사하고, bed of nails unpooling(upsampling)은 해당 하는 픽셀에만 값을 넣고 나머지는 0으로 만들어 버린다. bed of nails라고 불리는 이유는 zero region은 평평하고 non-zero region은 바늘처럼 값이 튀기 때문이라고 한다.
Max Unpooling(Bed of Nails for Maxpooling)
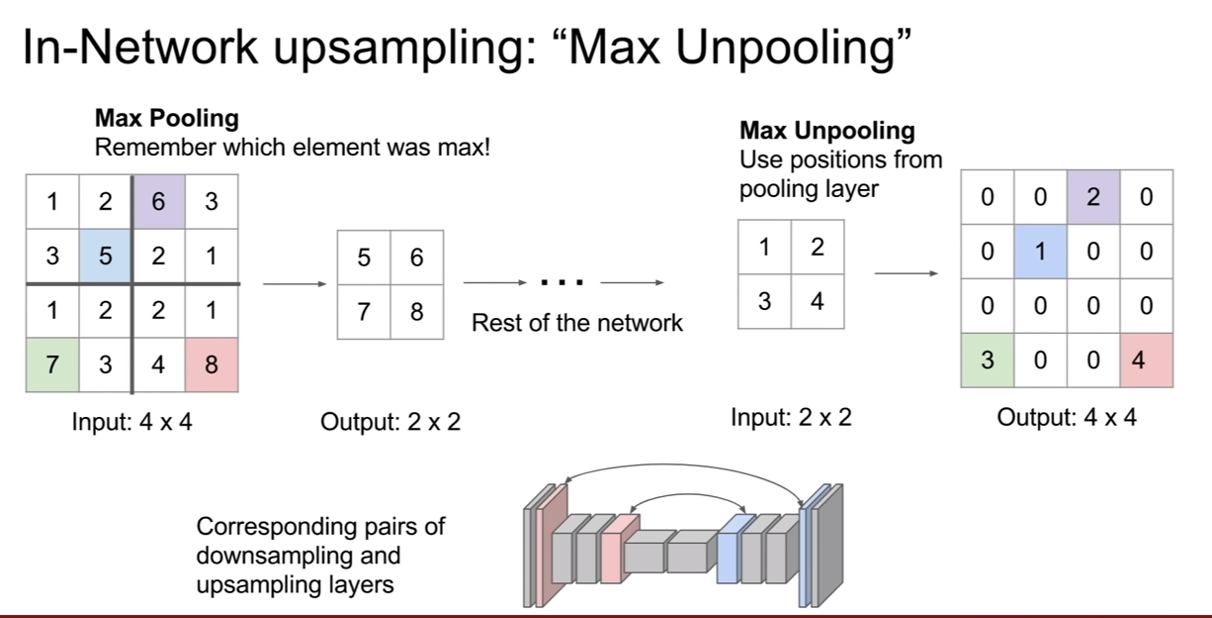
Maxpooling에 대해서 unpooling을 하는 방법이다. 기본적으로 위의 네트워크 구조는 대칭적인 구조이다. 즉, downsampling layer와 upsampling layer의 행렬의 크기가 웬만하면 동일하다는 뜻이다. 그래서 maxpooling시 선택되었던 위치를 기억하고 unpooling 때, 그 위치로 값을 복원시키는 것이다. 그리고 나머지 부분은 0으로 채운다.
이렇게 하는 이유는 해당 특징이 어느 위치로부터 왔는가를 알려주기 위해서이다. segmentaiton은 pixel단위의 분류로 매우 정교해야 한다. 즉 maxpooling시 잃어버린 공간정보를 어느정도 다시 복원해주는 효과를 띄게 된다.
Transpose convolution
우리가 convolution을 통해서 어떻게 downsampling하면 좋을지를 배웠듯이, upsampling에도 이에 대응하는 방법이 있으니 그 방법이 바로 transpose convolution 방법이다.

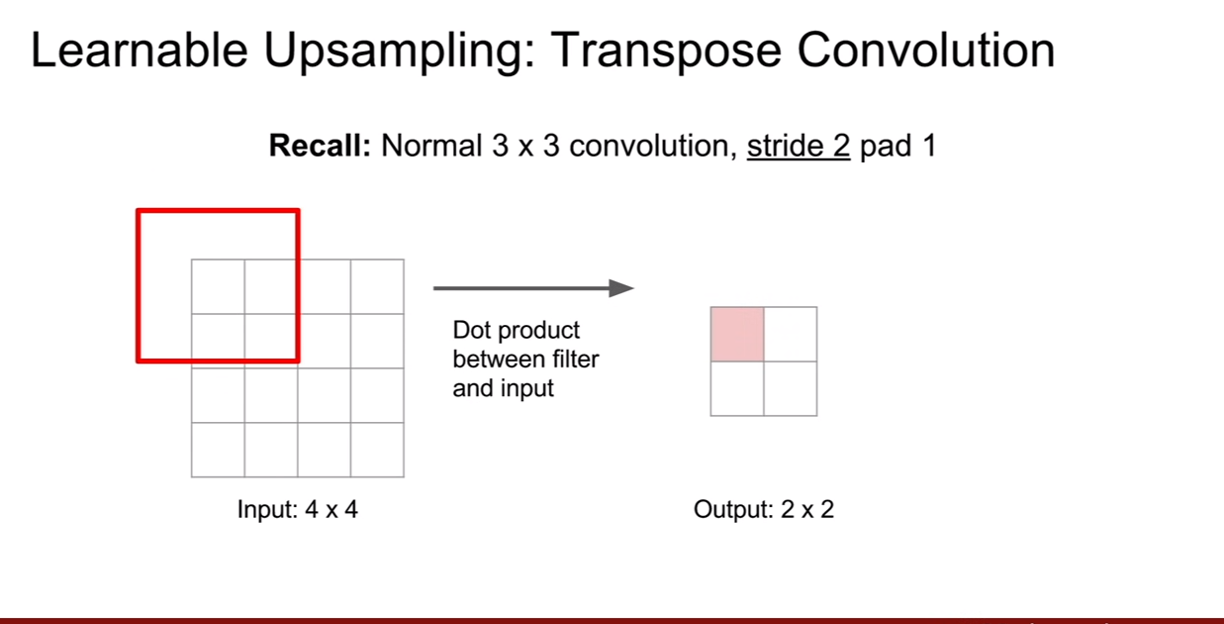
기존의 convolution 방법을 다시 살펴보면 위 슬라이드와 같다. 컨볼루션의 출력은 입력과 가중치 행렬의 행렬곱을 통하여 얻어졌다. 문헌에 따라서 부르는 방법이 아주 다양한데, 그 목록들은 왼쪽 상단에 나와있다. 다만 deconvolution은 신호처리에서 convolution의 역연산을 의마하는데 사실 transpose convolution은 convoluiton의 역연산이 아니기 때문에, 이런 네이밍은 좋지 않다. 하지만 많은 곳에서 보이기 때문에, deconvolution이란 용어는 주의해서 이해를 해야한다.
fractionally strided convolution이라 불리는 이유는, upconvolution을 stride 1/2 upconvolution이라 볼 수 있기 때문이다. 이렇기 이해하면 편하다. 일반적인 컨볼루션에서 stride=2이면 출력의 가로세로가 각각 2배씩 줄어 들었다. 반대로 2배씩 키우기 위해서는 stride=1/2가 되어야하는 것이다.
backward strided convolution이라 하는 이유는 transpose convolution의 forward pass가 일반적인 convolution의 backward pass와 수식이 동일하기 때문이다.
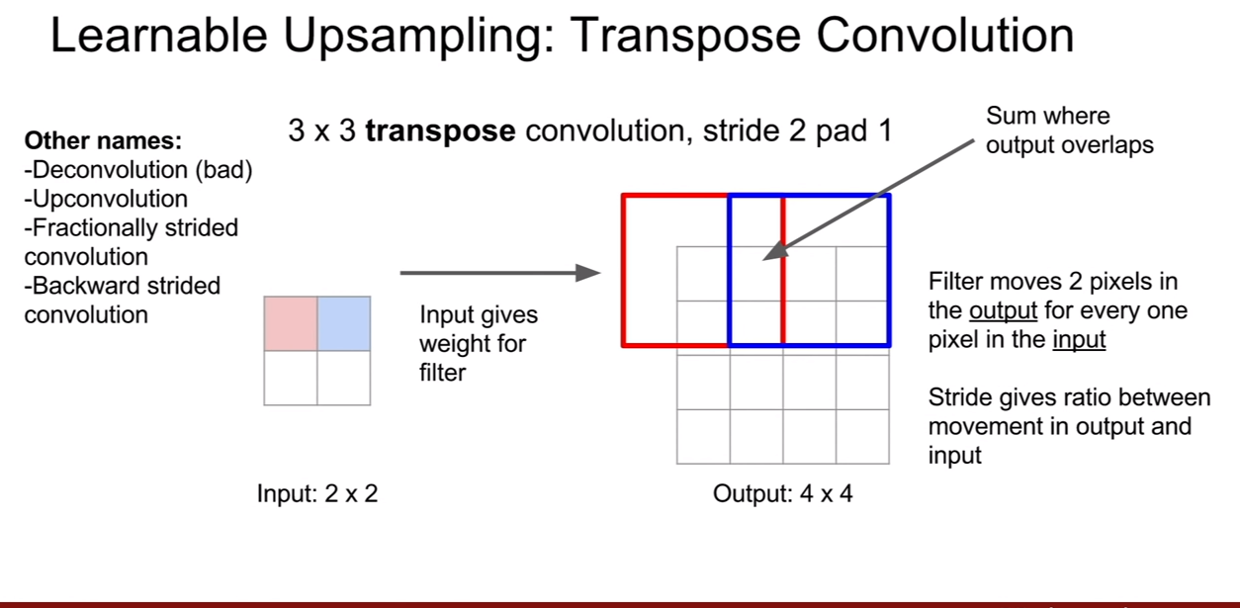
이제 transpose convolution을 살펴보자. 위 슬라이드를 보면 확실히 그냥 똑같이 반대로 확대하는것 같다. 겹쳐진 부분은 서로 더해준다.
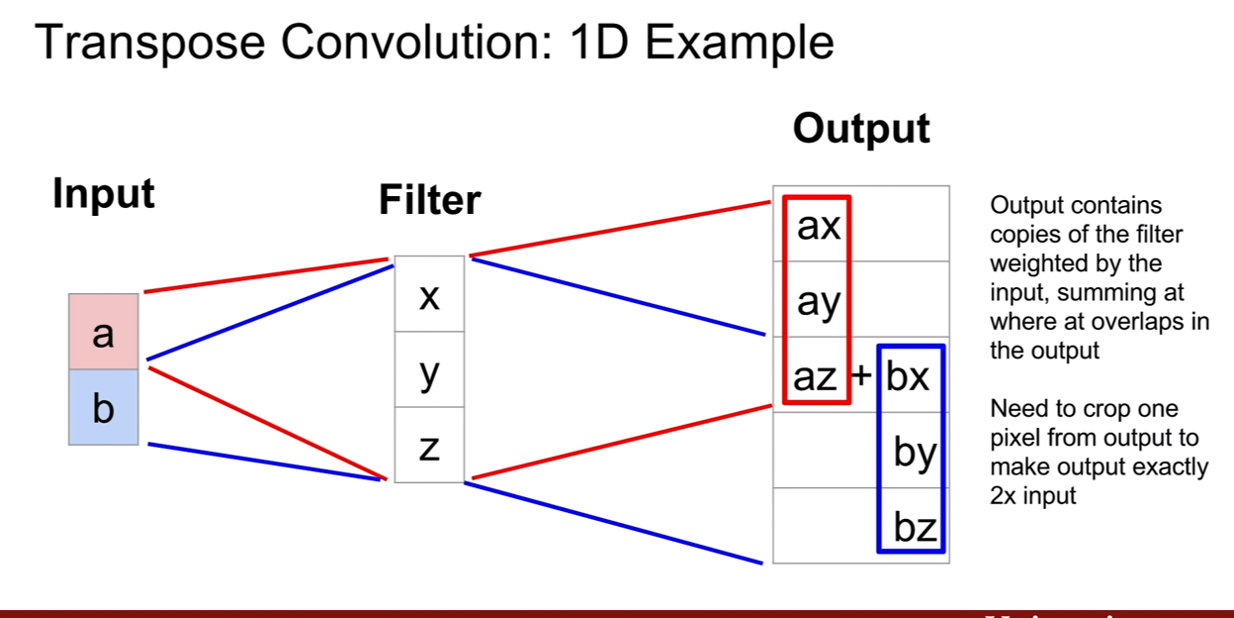
1dimension에서 살펴보자. matrix 연산이아니고, 입력이 가중치로써 곱해지는 모습을 볼 수 있다.
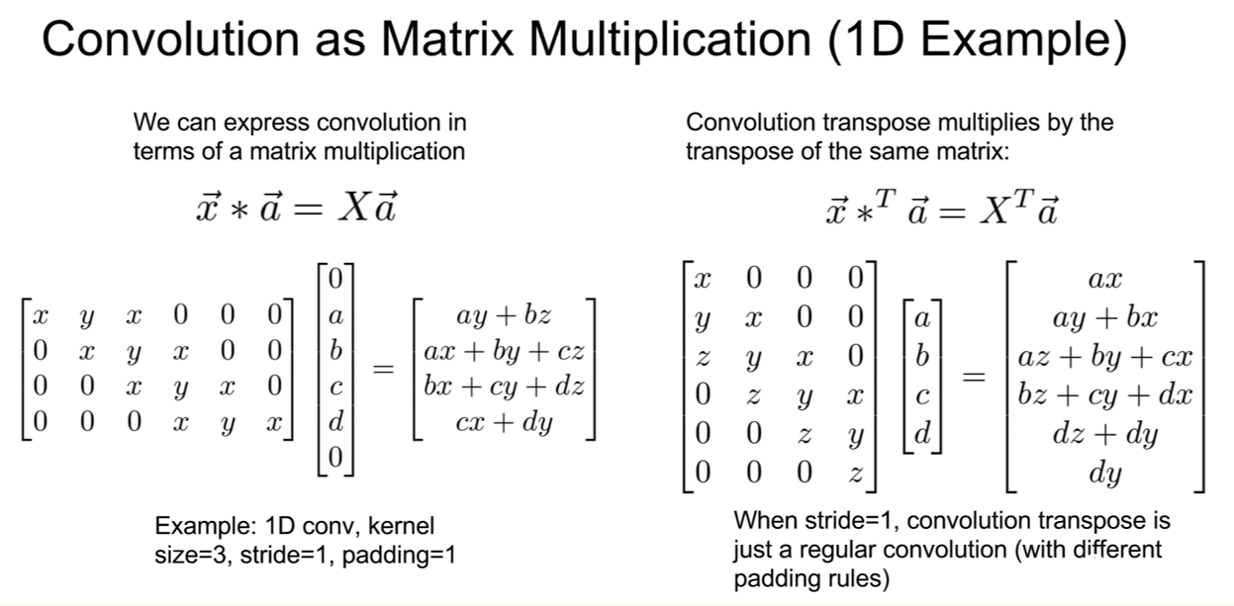
그렇다면 조금 더 일반적인 형태를 살펴보자. 위 슬라이드의 왼쪽은 1-D convolution, 오른쪽은 1-D upconvolution이다. 수식의 형태라 약간 적응이 안될 수 있는데, 행렬 연산을 해보면 이게 컨볼루션 연산과 동일하다는 것을 알 수 있을 것이다. [0,a,b,c,d,0]라는 입력을 [x, y, x]라는 필터로 컨볼루션을 진행한 것이다. 0은 패딩이다.
이 때, upconvolution이 어떻게 진행되는지 살펴보자. 앞서 컨볼루션 때 사용한 행렬을 전치시켜서 input에 곱해주면 된다. 이것이 stride=1 일때 transpose convolution이다.
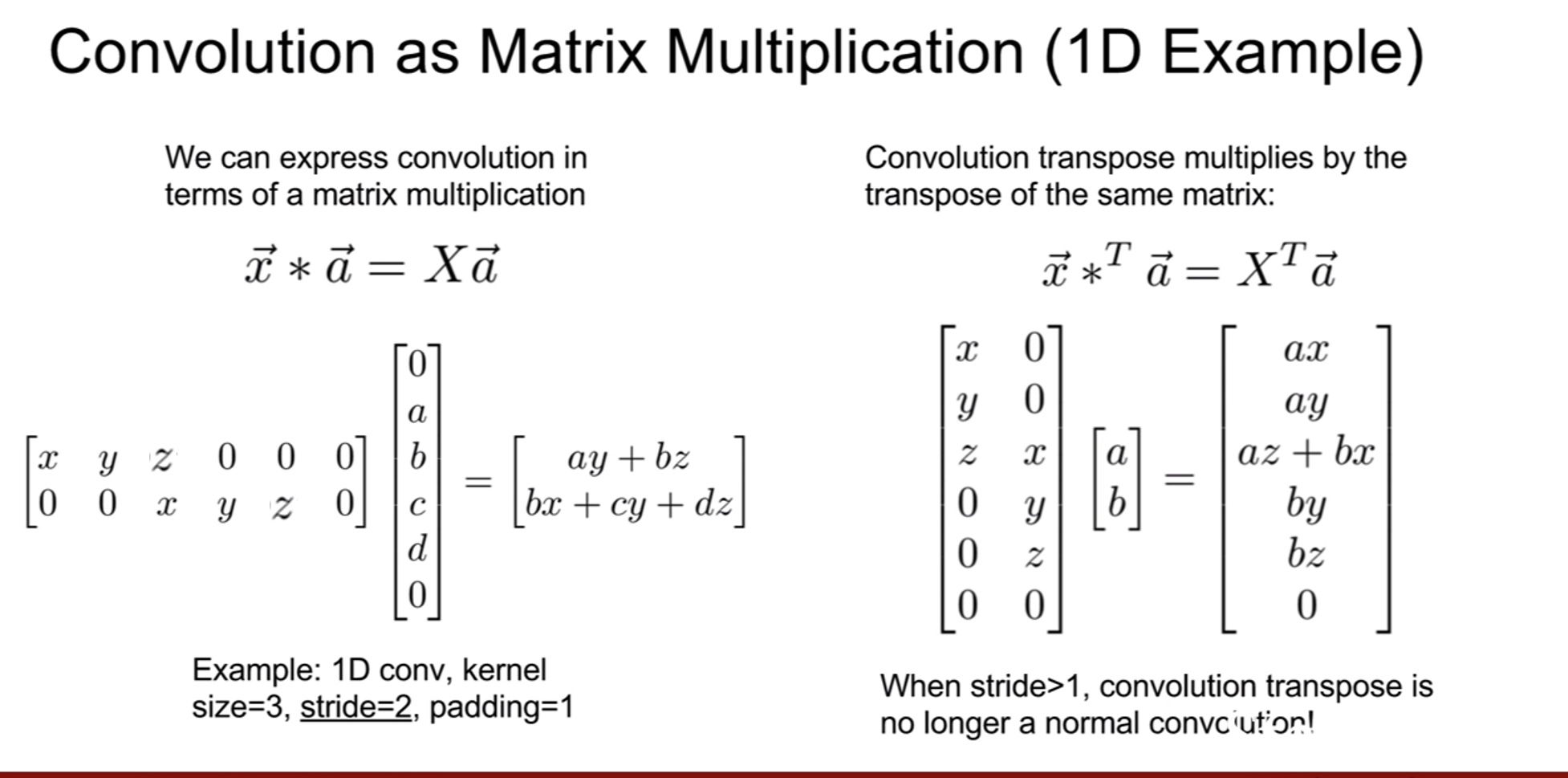
stride=2 일때 transpose convolution의 결과는 위와 같다.
그런데 강의에서 다음 질문이 나왔다. 겹쳐지는 영역을 평균을 내지 않고, 그냥 더하기만 하는 이유는 무엇인가? 이다. transpose convolution을 처음에 이렇게 구성했기 때문이라고 말하는데, 사실 이게 문제가 될 수 있다고 한다. receptive field의 크기에 따라서 크기(magnitudes)가 달라진다. 실제로, 3x3 stride 2 transpose convolution을 사용하면 checkboard artifact가 발생되기도 한다고 한다. 그래서 4x4 stride 2 혹은 2x2 stride 2를 하면 조금 완화가 된다고 한다.
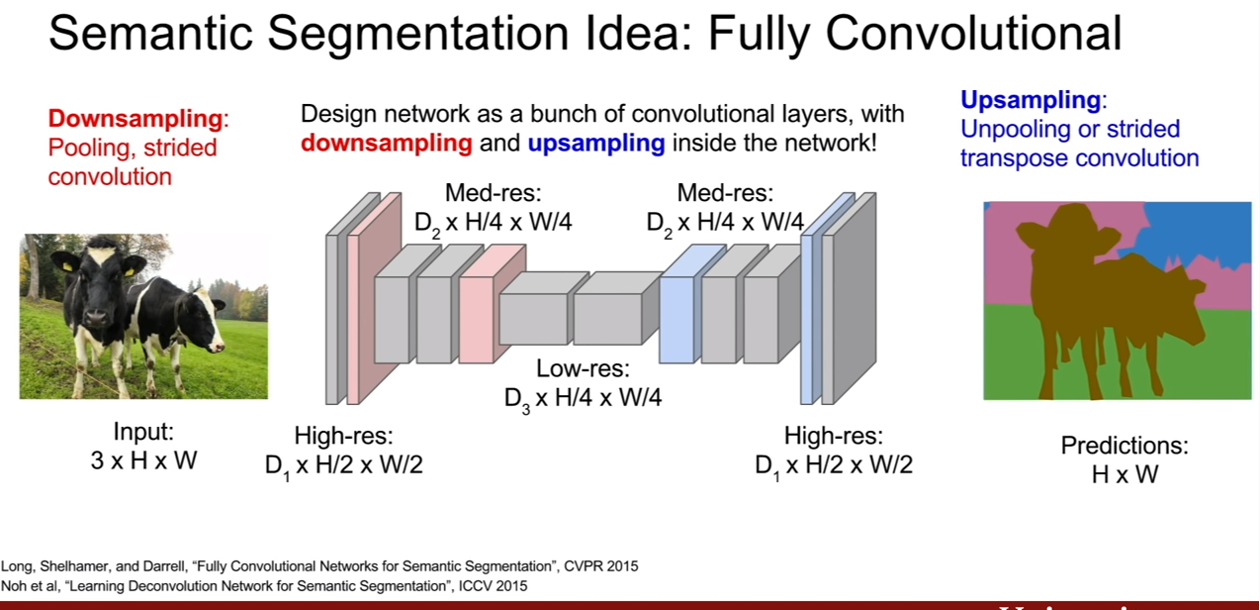
위 구조는 매우 일반적인 구조라 한다. 모든 픽셀에 대한 cross-entropy를 계산하면 네트워크 전체를 end-to-end로 학습시킬 수 있다.
Classification + Localization
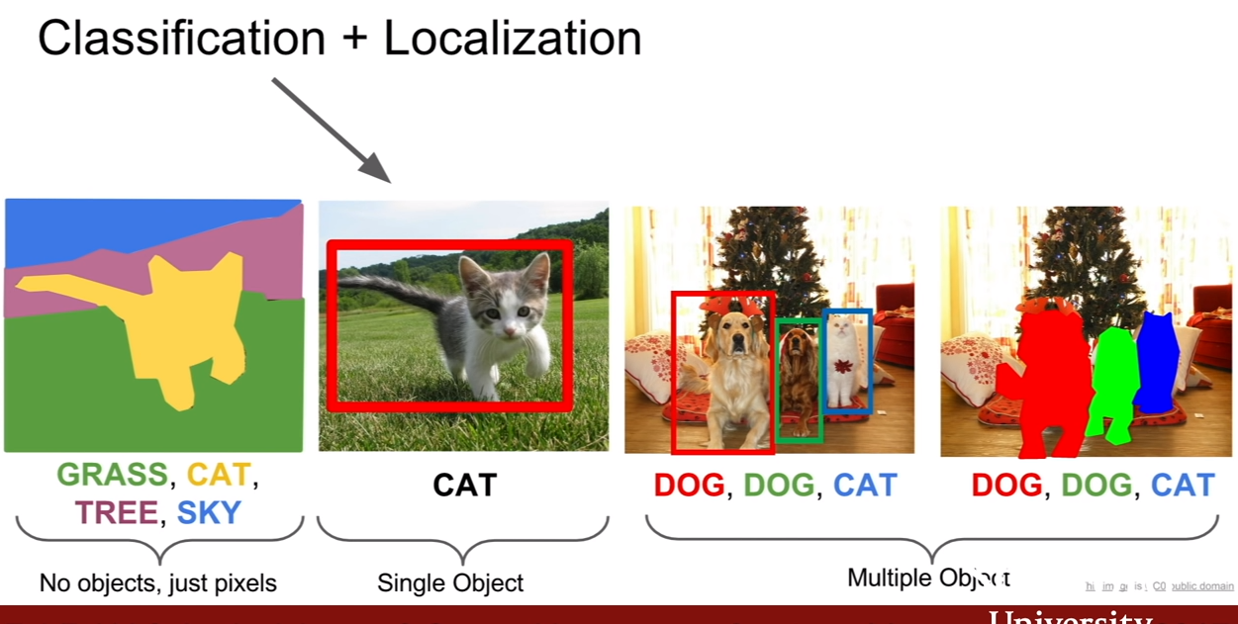
이번에는 Classification + Localization에 대해서 다루도록 하겠다. 앞서서 classification에 대한건 꽤 많이 다루었다. 그런데 우리는 cat이라고 분류할 뿐 아니라, cat이 어느 위치에 있는지 까지 알고 싶을 수 있다. 이 문제와 object detection문제는 상당히 유사한것 같지만 구별되는 문제이다. 왜냐하면 localization문제에서는 이미지 내에서 내가 관심있는 객체는 단 하나라고 가정되어있기 때문이다. 즉, 이미지에서 객체 하나를 찾고, 거기에 레이블을 매기게 된다. 이 작업이 바로 classification + localization이다.
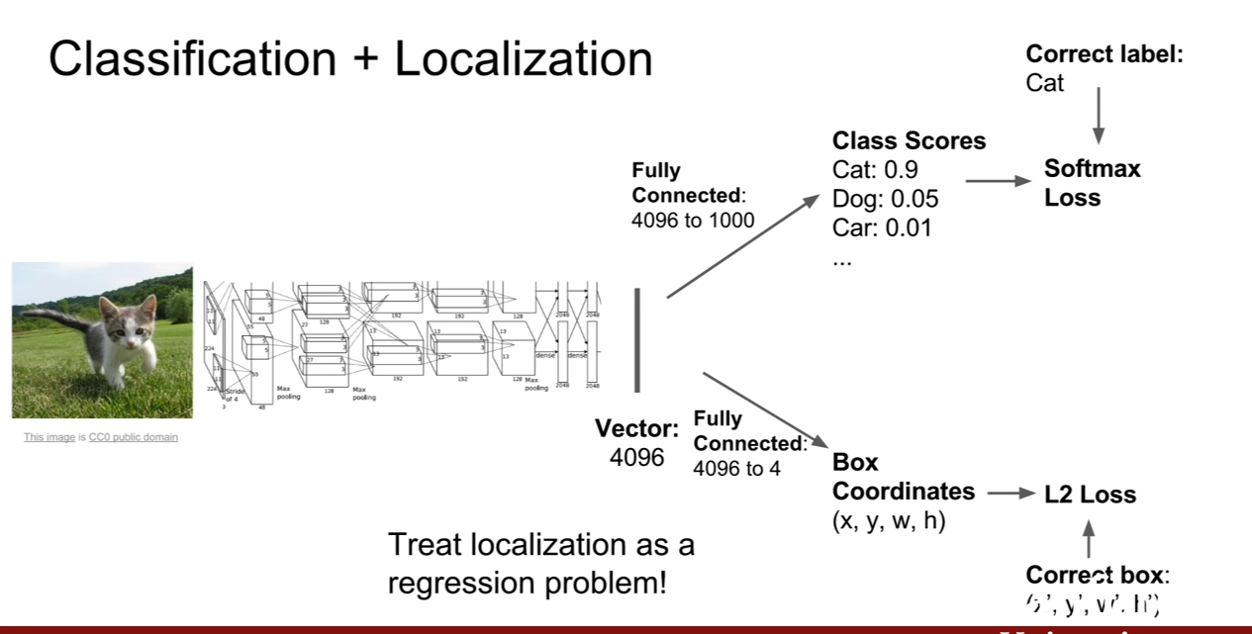
위 슬라이드를 보면 알 수 있듯이, 기존 classifcation과는 다르게 2개의 FC layer가 존재한다. 한 개는 classification을 위한 용도이고 다른 한 개는 localization을 위한 용도로 (x,y,w,h)=(중심,너비,높이)를 표시하기 위한 용도로 존재한다. 그렇기 때문에, loss function도 두 가지가 존재한다. 그리고 이 문제는 fully supervised setting을 가정한다. 그러므로 class label + bounding box ground truth를 동시에 가지고 있어야 한다.
두 가지 로스가 존재하는데, classification loss는 우리가 익히 알던 softmax loss로 구성이 된다. 그런데 bounding box를 위한 L2 loss가 제시되어 있다. 이 loss로 가장 쉽게 BBox(bounding box) loss를 가장 쉽게 구성할 수 있다고 한다. L1 이나 smooth L1을 사용해도 된다고 하면 약간은 달라지겠지만 기본적인 아이디어는 동일하다 한다. 이 loss들은 예측완bbox 와 GT bbox좌표 간의 regression loss이다.
여기서 질문이 나왔다. classification 과 localization을 동시에 학습해도 문제가 되지 않는지? 에 대한 질문이다. 일반적으로 문제가되지 않는다고 한다. 하지만 mis-classification에 대해서는 까다롭다고 한다. 이 문제를 해결하기 위한 방법중 하나는 bbox를 하나만 예측하는 것이 아니고 bbox를 클래스마다 하나 씩 예측하는 것이다. 그러고나서 GT의 클래스를 맞춘 bbox에 대해서만 loss를 계산한다고 한다.
이 슬라이드에서도 질문이 나왔다. 첫 번째 질문은 두 loss의 단위가 다른데 gradient계산에 문제가 되지 않을지에 대한 질문이다. 두 가지 loss를 합한 loss를 multi-task loss라고 한다. loss가 두개 이므로 두 가지 경로에서 미분값을 두 개를 구해야 하고, 각각의 loss를 모두 최소화 시켜야 한다. 위에서 말한 스케일 문제를 해주며, 두 loss의 반영비율을 결정해주는 스케일러(scaler)가 실제로 곱해진다고 한다. ($\alpha, 1-\alpha$와 같은 방식으로.) 하지만 이런 파라미터를 찾는 것은 매우 어렵다고 한다. 왜냐하면 손실함수의 값 자체를 바꿔버리고 loss자체의 속성이 변하기 때문이다.
하지만 이런 loss가 낮아지는지 높아지는지보다 중요한 것은 다른 성능지표로 판단하는 것이라고 한다. 즉, 모델의 성능지표, detection의 경우 MAP같은 것들을 보아야한다고 한다.
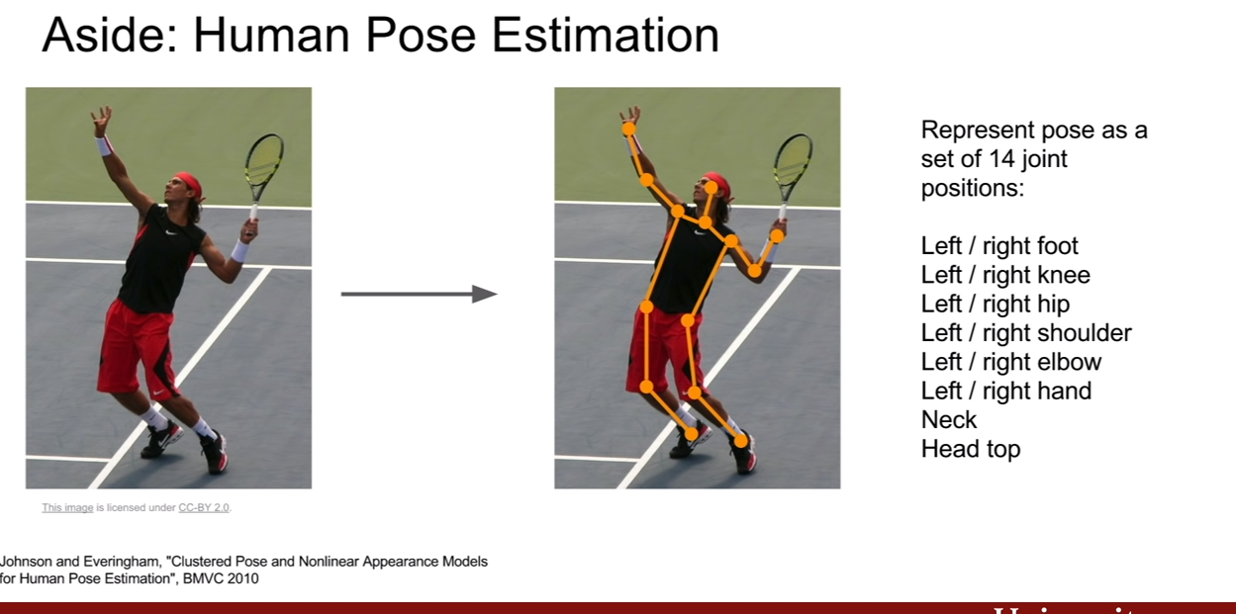
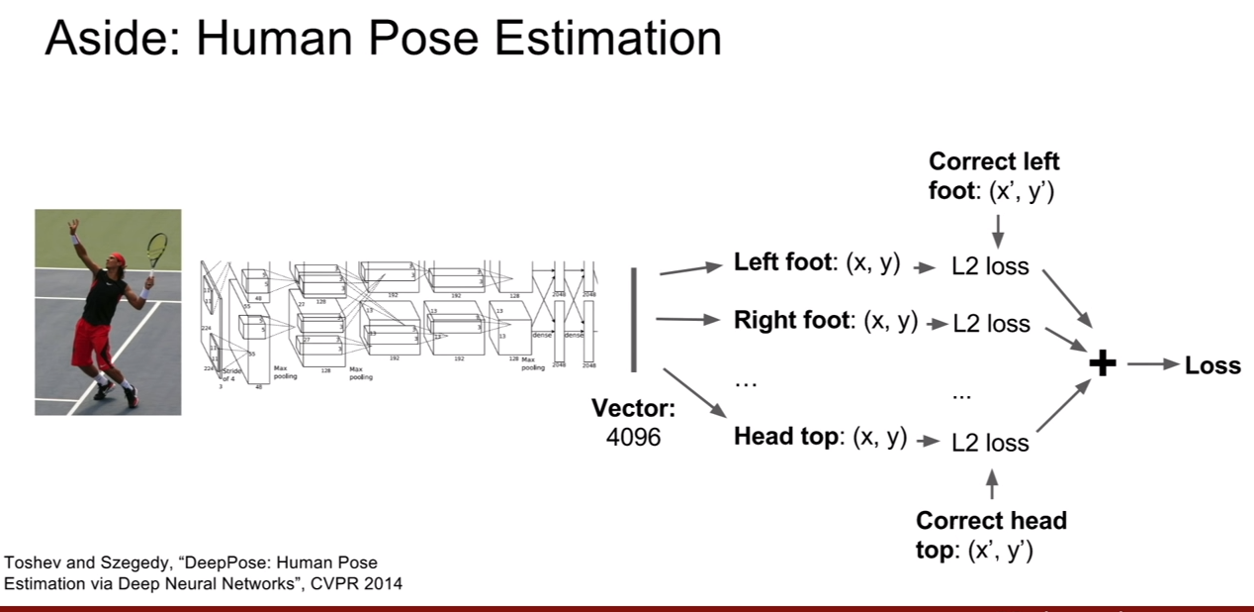
이 네트워크는 classification + localization 뿐 아니라 human pose estimation에도 적용시켜 볼 수 있다고 한다. 이것은 즉, bounding box의 좌표가 사람 관절의 좌표로 바뀌는 것이다. 14개의 사람 관절 좌표만 얻으면 되기 때문에, FC layer가 따로 두 개가 존재하여 loss가 두개일 필요가 없다.
Regression loss가 무엇인지에 대한 질문이 있었다. 질문에 대한 답은 다음과 같다. cross-entropy, softmax loss말고 L1, L2 loss같은 loss를 regression loss라 칭한다 한다. classifcation과 regression의 일반적인 차이는 결과가 categorical 인지 continuous이다. 즉, 고정된 클래스 개수가 있고, 네트워크가 이를 결정하기 위하여 클래스의 점수를 출력하는 경우면 cross entropy, sofrmax, SVM marginloss같은 것들을 사용가능하고, 출력이 연속적인 값(continuous)라면 pose estimation같이, 이런 경우에는 다른 종류의 loss를 사용해야 한다. (쉽게 생각하면 이렇게 생각해볼 수 있을것 같다. 개, 고양이, 소를 구분한다고 할 떄, 개의 확률이 1이면 나머지는 0이고, 소의 확률이 1이면 나머지가 0이다 즉, 한 클래스의 값이 다른 클래스에 영향을 준다. 하지만, pose estimation같은 경우, 각 클래스가 독립적이다. left foot의 위치가 (10,10)->(20,20)으로 변했다고 해서 right foot의 위치가 그 수만큼 감소하거나 증가해야 하는것이 아니다.)
Object detection
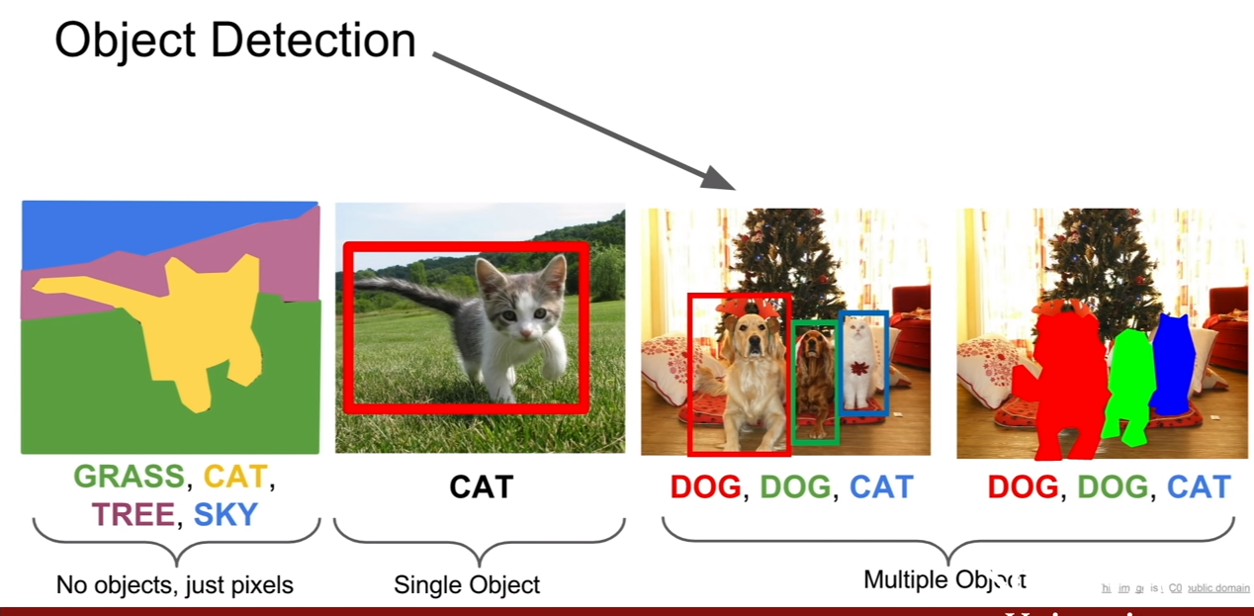
다음으로 object detection에 대해서 살펴볼 것이다. object detection에 대해서는 한 클래스를 모두 object detection으로만 진행할 수 있을 정도로 방대하다고 한다. 이번 강의에서는 deep learning에 관련되어 설명한다고 한다.
object detection은 classification + localization(C+L)과 차이가 있는데, 그 중 하나는 C+L은 이미지에 단 하나의 객체, 하나의 클래스를 추론하는 것을 알고 있다는 점이며, object detection은 이미지에 따라서, 예측해야 하는 bbox의 숫자가 달라진다. 각 이미지마다 존재하는 객체의 수가 다르기 때문에 더 어려운 문제이다.
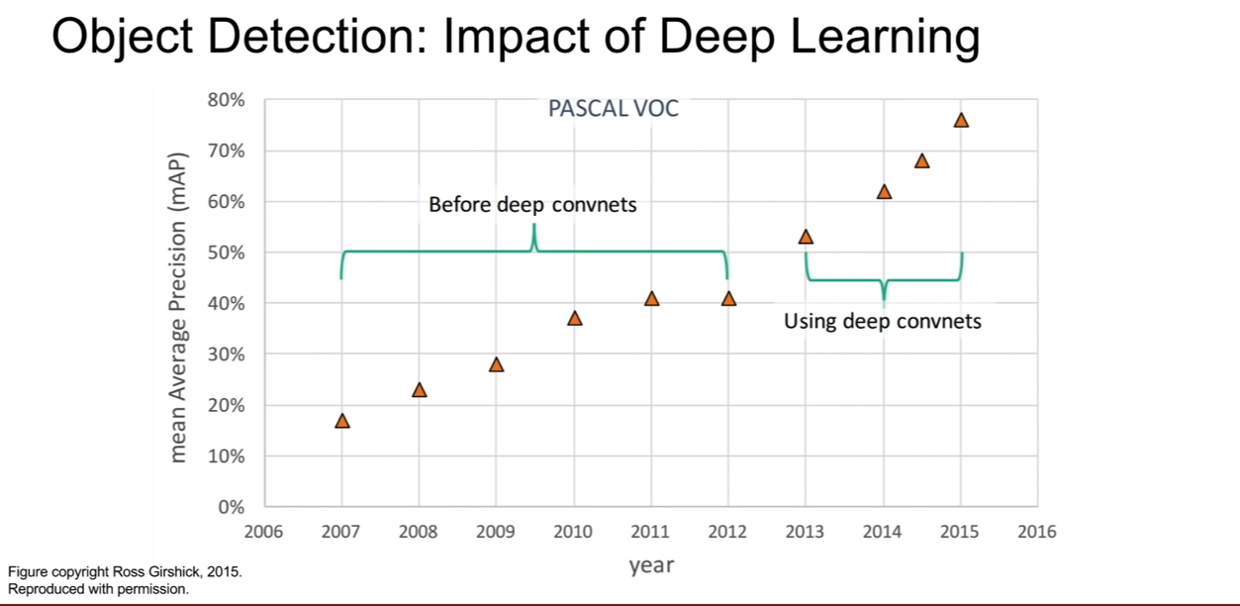
이 그래프는 object detection 분야의 대가인 Ross Girshick의 슬라이드에서 가져왔다. PASCAL VOC데이터셋이 아주 오래되었다… 성능의 상승이 저하되었다가, deep learning의 등장 이후 성능의 향상이 비약적으로 높아졌다.
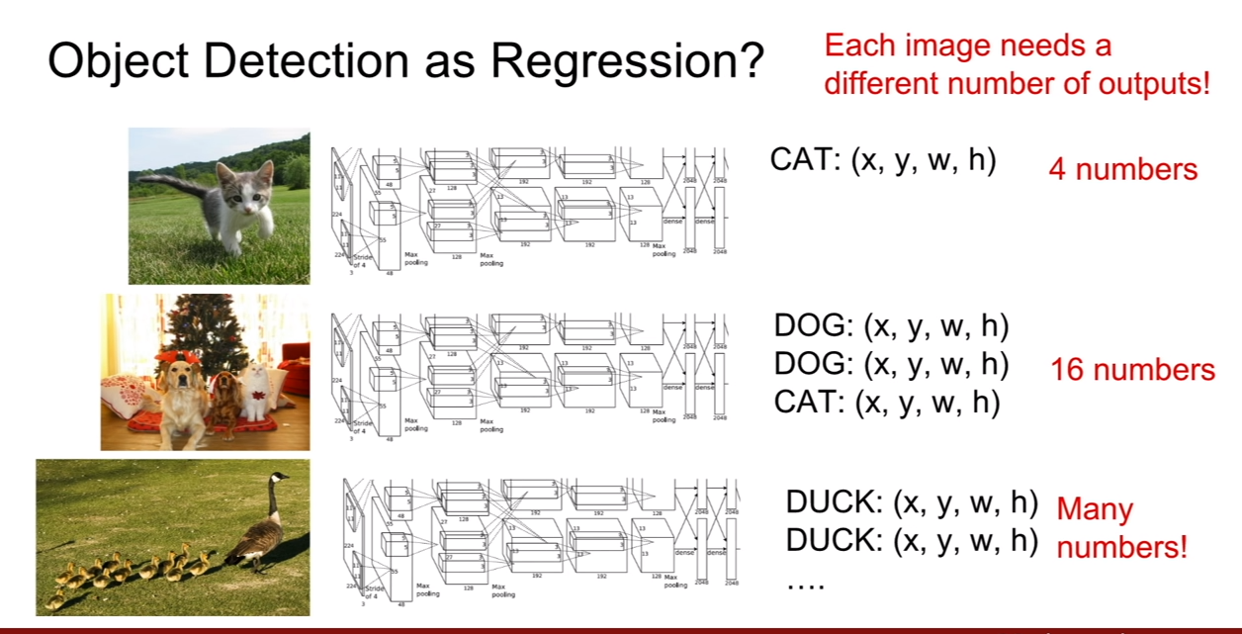
만약에 C+L 방식으로 object detection을 하려면 물체의 bbox를 나타내기 위하여 FC layer가 필요하므로 이미지에 등장하는 수많은 객체의 후보를 표현하기 위하여 수 많은 FC layer가 필요할 것이다. 그러므로 이는 다른 패러다임으로 해결이 되야 한다.

semantic segmentation에서 안좋은 방법으로 소개되었던 작은 패치로 쪼갰던 아이디어와 비슷한 방식이 사용된다. sliding window 방식을 이용하려면 입력 이미지에서 다양한 영역을 나누어서 처리해야 한다. 만약에 위 이미지에서 왼쪽 하단에 있는 작은 패치를 크롭하여 CNN에 집어넣으면 아무것도 없다는 output을 내놓을텐데 그러기 위해서는 배경(background)클래스를 추가해야 한다.
그러면 위 슬라이드에서 3가지 영역에 대해서 살펴보자. 각기 다른 결과를 내놓아야 할 것이다. 그런데 이 방식의 문제점이 무엇일까? 어떻게 영역을 추출할 지가 어렵다는 것이다. 이미지에 object가 몇 개 존재하는지, 어디에 존재하는지, 크기는 어떨지 알 수가 없다. 따라서 이런 brute force 방식은 sliding window 의 경우의수가 셀 수 없이 많다는 것이다. 이것 대신에 Region proposal이라는 방법이 존재한다. 사실 region proposal 방식은 딥러닝을 사용하지 않는다고 한다.
Region proposal
Region proposal network는 전통적인 신호처리 방식을 이용한다고 한다. region proposal은 객체가 있을법한 1000개 가량의 bbox를 제공해 준다. 후보 지역을 찾기 위하여 edge, texture등 다양한 방법을 이용할 수 있겠지만, blobby한 곳들을 찾음으로써 제공한다.
이러한 region proposal(후보 지역) 을 만들어낼 수 있는 방법에는 selective search방법이 있다. selective search는 이 두 배인 2000개 가량의 후보 지역을 추출해낼 수 있다고 한다. 다만 이 방법은 노이즈가 매우 심하다고 한다. 다만 recall이 높기 때문에, 객체가 존재한다면 region proposal 안에 존재할 확률이 높다고 할 수 있다. (너무 bbox를 많이 생성하는게 문제.)
Deep learning approach for object detection
이제 무식하게 이미지 내의 모든 위치와 스케일을 고려하는 방법이 아닌 다른 방법을 살펴보도록 하자.
- R- CNN
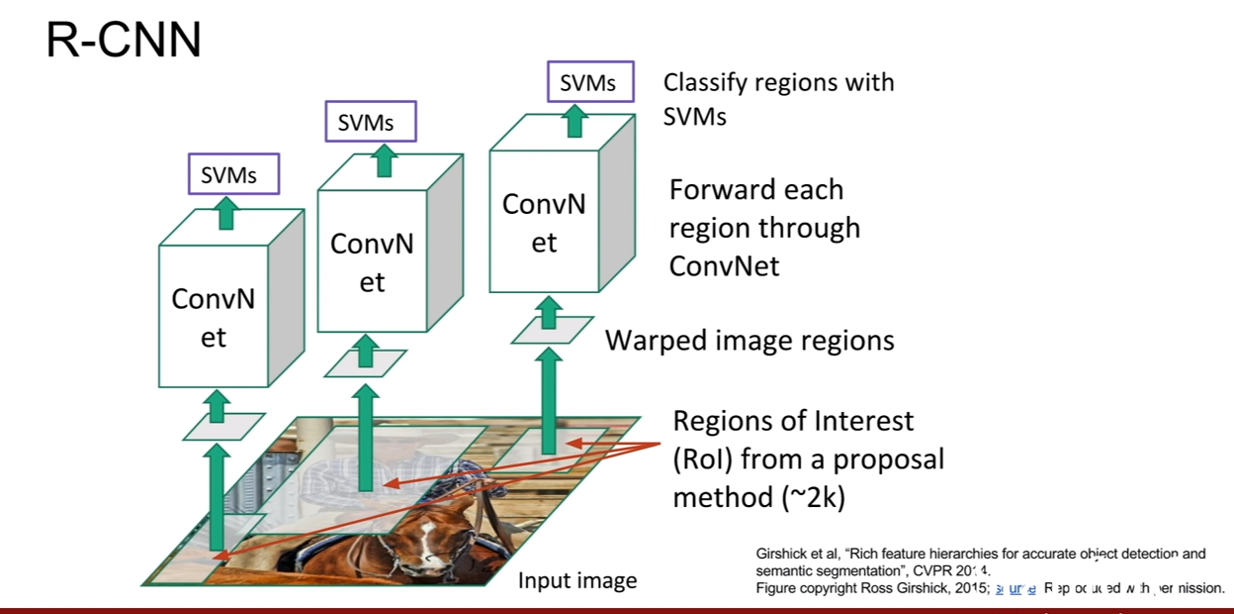
첫 번째 방법은 R-CNN이다. selective search를 통하여 region proposal을 우선적으로 얻어낸다. 그 후보 지역이 바로 CNN의 입력이 되는 것이다. region proposal은 region of interest(ROI)라고도 한다.
하지만 여기서 생기는 문제점은 ROI의 사이즈가 다 제각각이라는 것이다. 즉, CNN의 입력은 항상 동일한 입력을 받기 때문에 문제가 생기는 것이다. 그러므로 ROI를 추출하고 나면 고정된 사이즈로 크기를 바꾸어 준다. 그리고 최종적으로 SVM을 이용하여 classification을 진행한다.

RCNN에는 많은 문제점 들이 있는데 그 중하나가 바로 ROI 2000개가 독립적으로 각각 1개씩 CNN의 입력으로 들어간다는 것이다. 그 말은 이미지 한 개에 대해서 object detection을 수행하기 위해서는 2000번이나 iteration을 해야한다는 것이다. 논문에서는 학습시간이 81시간이나 걸리고, test하는데도 한 장당 30초나 걸린다는 것이다. 또한 R-CNN의 원본 구현체를 보면 CNN의 feature를 디스크에 저장해놓기 때문에 용량이 어마어마 하다는 것이다.
- Fast R-CNN
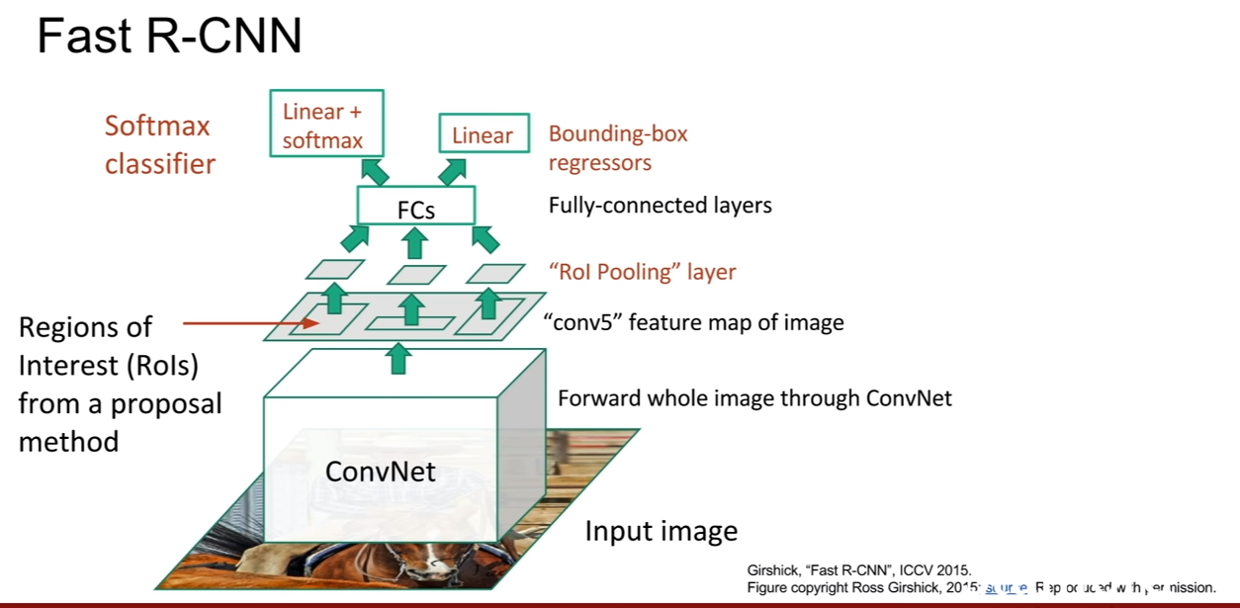
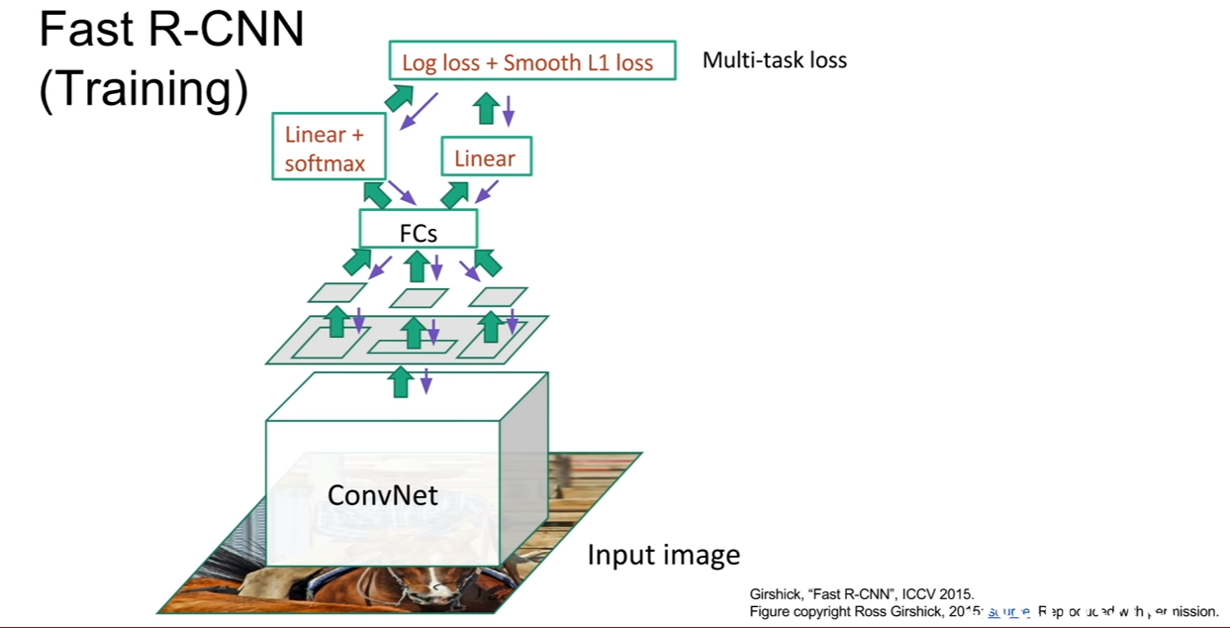
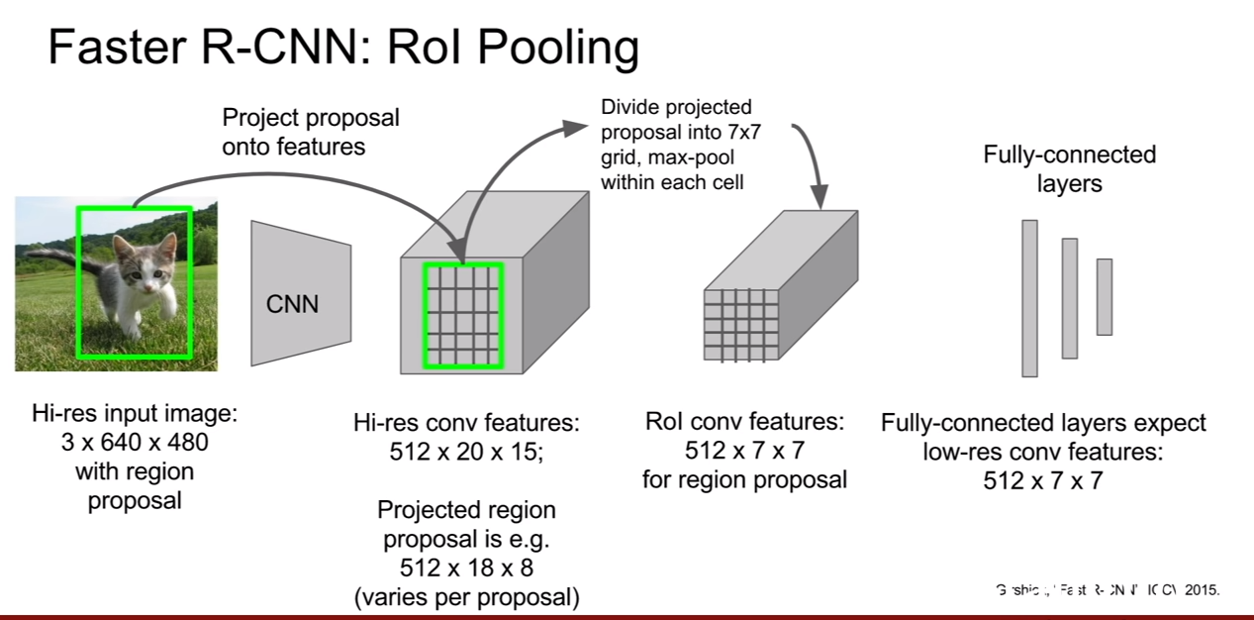
하지만 이러한 단점의 상당부분은 Fast R-CNN에서 상당부분 해결되었다. RCNN과 ROI를 추출하는 과정은 똑같지만, 각 ROI들에 대해서 CNN을 개별적으로 통과시키지 않는다. 즉, 전체 이미지를 CNN에 집어 넣는다.
우리는 CNN의 구조를 생각해보면 해당 Feature map이 원본 이미지의 어느 지역을 거쳐 왔는지 알 수 있다. (3x3 filter를 사용했다면, convolution 출력의 한 픽셀은 이전 피쳐맵의 3x3지역으로 부터 온게 된다. 그렇게 쭉쭉 거슬러 올라가보자.) 그렇기 때문에 ROI를 전체 이미지를 컨볼루션한 출력에 투영(projection)시킬 수 있게된다. 물론 이 ROI는 다음 연산이 수행될 수 있도록, 크기를 동일하게 바꾸어 주어야 한다. 그 후, loss를 계산하는 과정은 동일하며, classification 부분이 softmax classification으로 바뀐것을 확인할 수 있다.
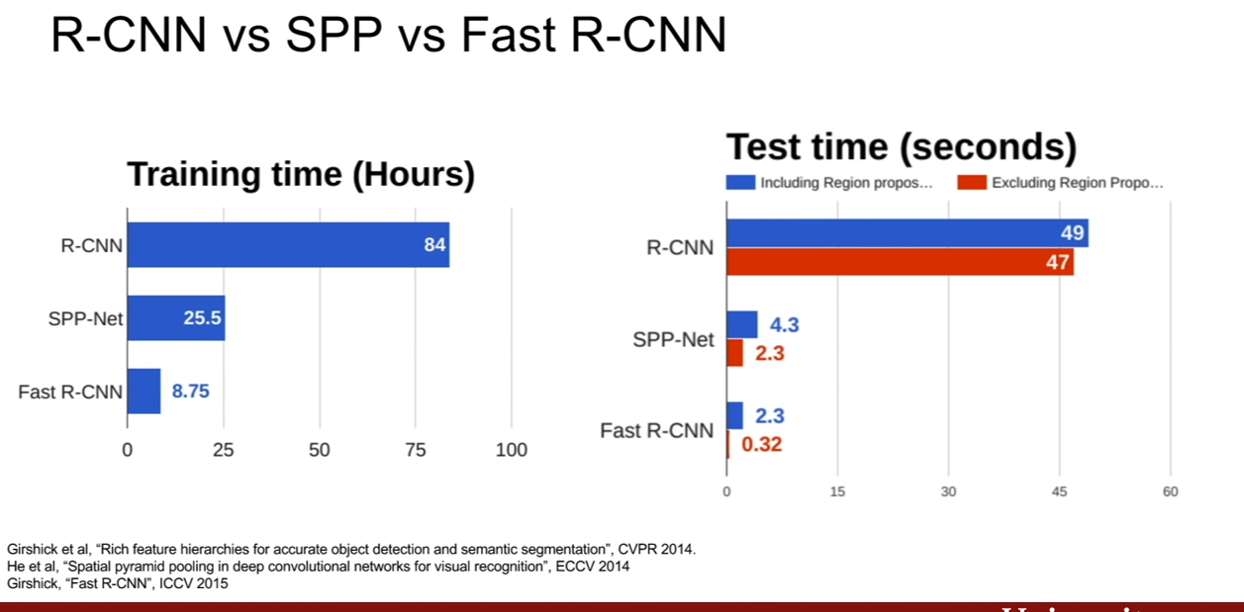
다른 object detection network인 SPPNet과 비교해보자. training 시간이 매우 줄어든 것을 확인할 수 있다. 테스트 시에도 Fast RCNN이 무척 빠른 모습을 확인할 수 있다. 왜냐하면 모든 region proposal이 CNN feature를 공유하기 때문이다. 즉, Fast R-CNN에서 속도향상에 병목을 일으키는 것은 ROI를 뽑아내는 시간이다.
- Faster R-CNN
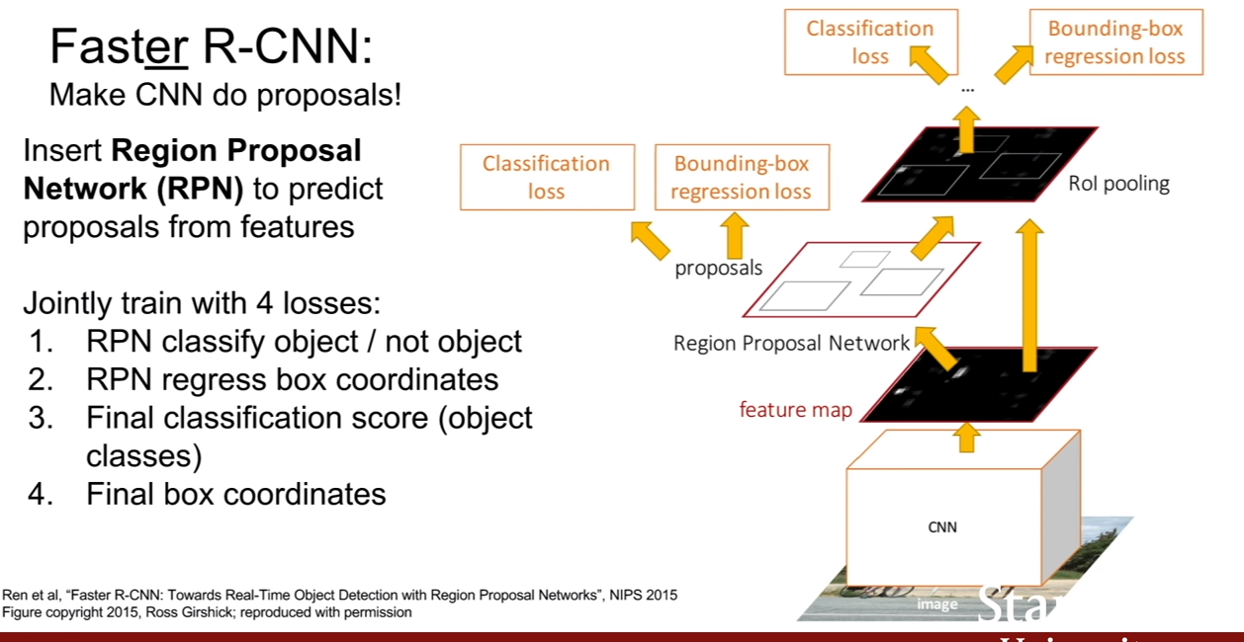
Faster R-CNN은 ROI를 직접 만들어낼 수 있다. Faster R-CNN은 ROI를 만들어내는 별도의 Region proposal network(RPN)이 존재하여, 입력 이미지로부터 뽑아낸 피쳐 맵을 가지고 ROI를 만들어낸다. 그 후 동작은 Fast R-CNN과 동일하다.
여러가지 질문이 있었지만 그 중 흥미로웠던 질문은 RPN의 GT가 없는데 어떻게 학습되냐는 것이었다. 즉, 학습할 수록 bbox를 더 잘 추출해야만 할 것이다. 그런데 이게 GT의 개수보다 많은 ROI를 처음에 만들어낼수도 있고 더 적은 ROI를 만들어 낼 수도 있을 것이다. 여기서 답변이 GT 의 bbox와 조금 겹치는 ROI는 negative, 많이 겹치면 postive라는 식으로 학습하는데 이 사이에 여기선 설명하기 복잡한 하이퍼파라미터가 많아 설명을 하지 않는다고 했다. 나중에 찾아봐야겠다.
그리고 또한 RPN은 binary classification을 수행한다고 한다. 즉 region에 물체가 있는지 없는지를 판단한다. 그러므로 loss는 binary classification loss이다.
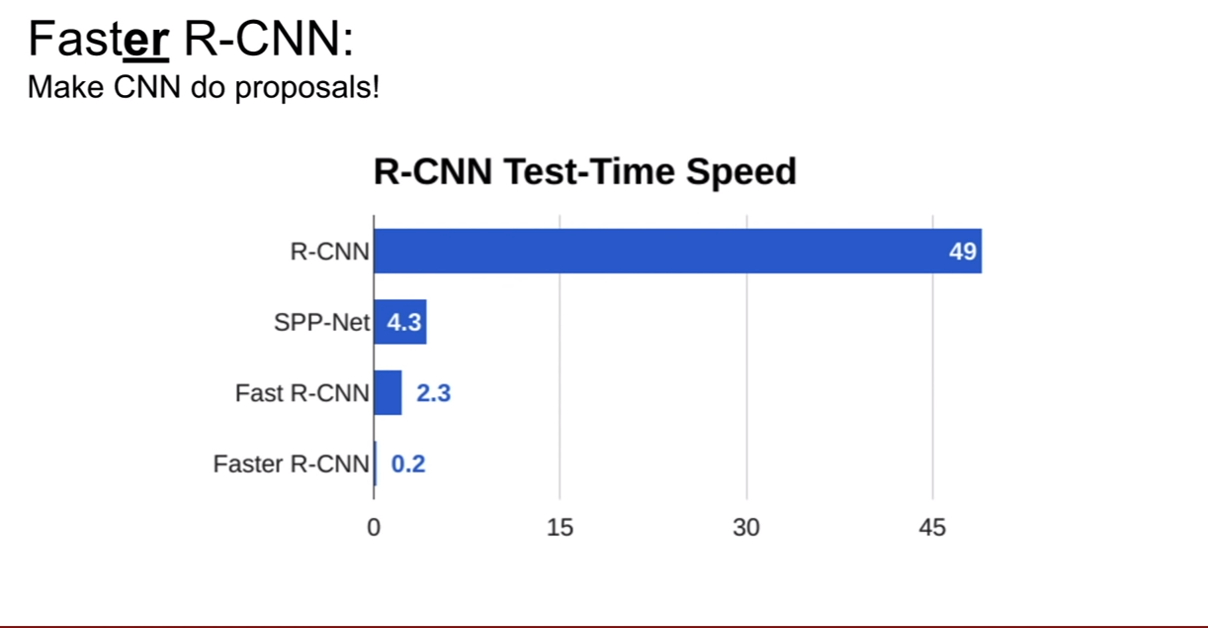
위 그래프를 보면 faster-RCNN이 정말 빠른 모습을 볼 수 있다.
여태까지 살펴본 네트워크들은 R-CNN계열 네트워크로써 region-based method라고 불린다. 이런 R-CNN 계열 말고도 다른 방법들이 존재한다.

YOLO와 SSD라는 네트워크가 존재한다. 이 두 네트워크의 주요 아이디어는 각 task를 따로 계산하지말고 하나의 regression problem으로 간주하자는 것이다. 이 방법들은 둘 다 single shot method이다.

다양한 네트워크들이 존재한다. 기본 구조에서 base network를 바꿔볼 수도 있고, R-CNN의 계열 방법과 sigle shot 방법들을 섞어볼 수도 있을 것이다.

최근에 보았던 흥미로운 논문이 있는데 바로, detection과 captioning을 동시에 수행하는 논문을 보았다고 한다. 이것을 보여준 이유는 다양한 문제를 서로 묶어서 해결할 수 있다는 것을 보여주기 위하여 추가하였다고 한다.
Instance Segmentation
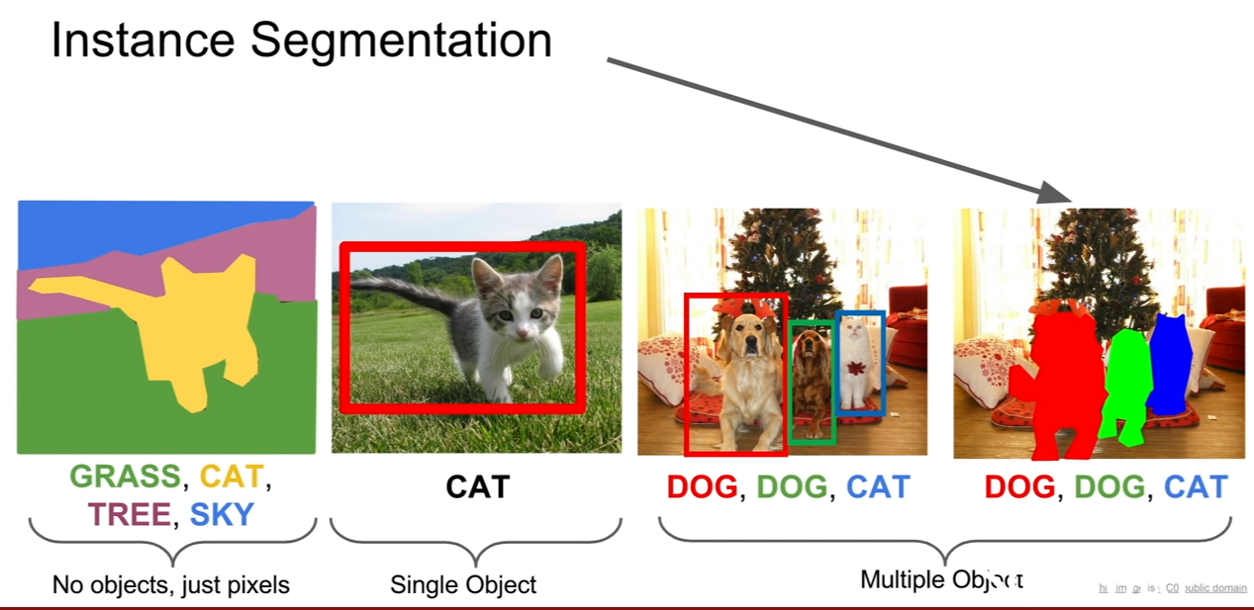
마지막으로 instance segmentation에 대해서 살펴볼 것이다. instance segmentation은 지금까지 배운 것들의 종합 선물 세트이다.
위 슬라이드에 나와있는 것 처럼, 입력 이미지가 주어지면 객체별로 위치를 알아내야 한다. 하지만 bbox를 예측하는것이 아니로 객체별로 segmentation mask를 예측해야 한다는 점이 다르다. 즉, semantic segmentation + object detection 문제이다.
슬라이드의 그림 처럼 이미지 내에 개 두라미가 있으면 instance segmentation은 개1, 개2와 같은 식으로 구분을 해야한다. 이는 2017년에 나온 Mask R-CNN에서 다루고 있다.
Mask R-CNN은 faster R-CNN과 비슷하다. 이미지가 CNN과 RPN을 거치는 부분은 faster R-CNN과 똑같다. 그리고 ROI를 projection시켜 해당 영역에 해당하는 feature map을 convolution layer를 통과시켜 각 bbox 마다 segmentation mask를 예측하도록 한다.
첫 번째 갈래에서는 각 ROI가 어떤 클래스에 속하는지 계산하고, ROI의 좌표를 보정해주는 bbox regression도 추가된다.
두 번째 갈래에서는 semantic segmentation을 수행한다.
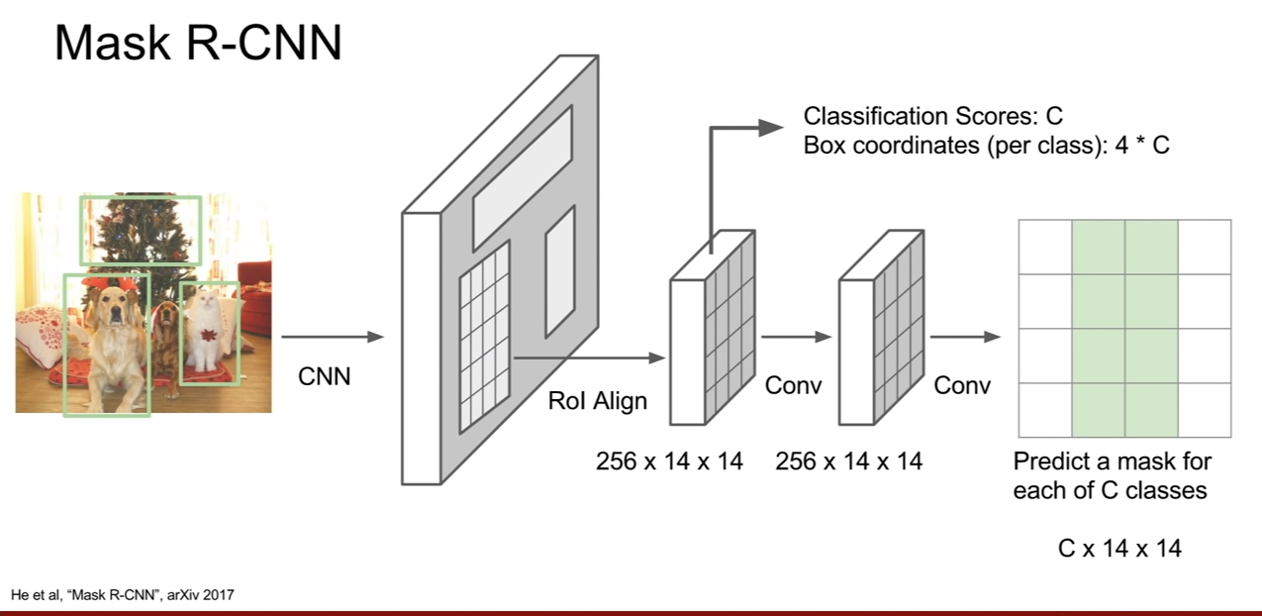
이 방식은 잘 작동하여 GT와 구분이 안갈정도로 매우 자세한 모습을 보여준다.

또한, pose estimation에도 이용이될 수 있다. 즉, bbox 갈래, segmentation갈래만 있었다면, pose estimation갈래를 하나 추가하여 추가적인 작업을 수행해주면 된다.