

CS231n-Lecture08(Deep Learning Software)
23 Aug 2020 | CS231n목차
저번 강의 때 배웠던 부분을 살펴보자.
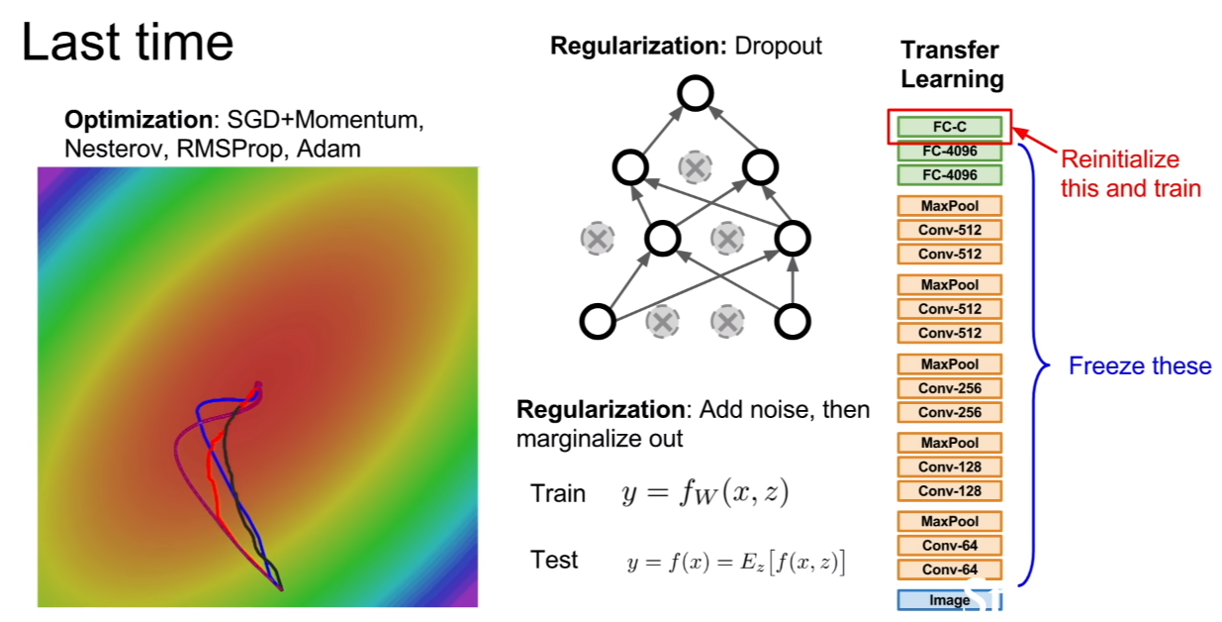
우리는 optimizer, regularization, transfer learning에 대하여 간락하게 배웠었다.

오늘은 딥러닝을 프로그램을 구축하기 위한 소프트웨어에 관하여 간략하게 배워보는 시간을 가질 것이다.
CPU vs GPU
먼저 cpu와 gpu의 차이에 대해서 살펴보자.

이번 강의를 진행해주시는 Justin Johnson(강의당시에는 박사, 현재는?)님의 컴퓨터 내부라고 한다. CPU의 자리는 그림에 나와있는것과 같은 자리이다.

GPU는 이에 반해서 크기가 더 큰 모습을 볼 수가 있다.

deep learning에서는 두 회사의 제품중 NVIDIA의 그래픽카드가 장착된다고 한다. 왜냐하면 NVIDIA의 GPU가 deep learning에 더 적합하게 설계가 되어있기 때문이다. (지금도 그런것 같다.)
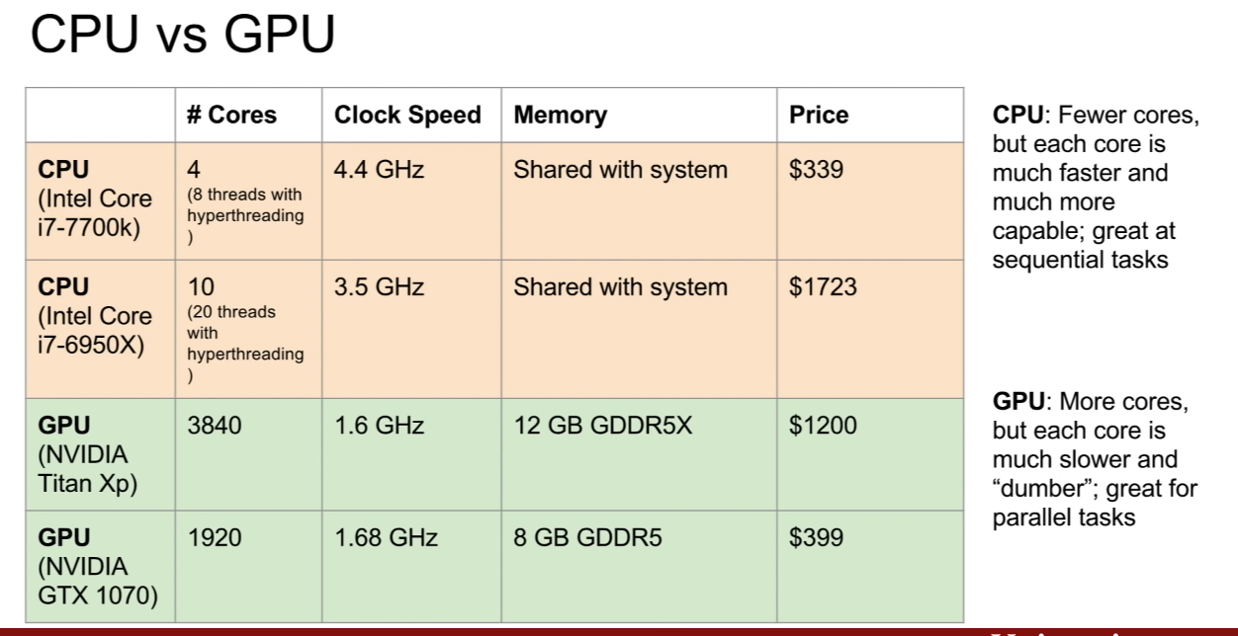
CPU와 GPU의 차이를 살펴보자. 우선 코어의 수 부터 엄청 차이가 난다. 하지만 그 코어가 처리하는 역할이 다르다고 볼 수 있다. CPU는 CPU의 메모리에 현재 실행되는 프로그램이 들어가 각 코어가 해당 프로그램이 잘 작동하도록 처리하는 역할을 하지만, GPU의 코어는 CPU에 비해 아주작은 단위 연산을 수행할 뿐이다.
각 코어는 독립적으로 연산을 수행할 수 있으므로, 단순 계산을 할 때에는 코어수가 많은 GPU가 당연히 좋을 것이다. 왜냐하면 3840개의 연산을 독립적으로 수행할 수 있기 때문이다. 하지만 위에서 말한 것 처럼, 각 코어의 속도는 당연히 CPU가 훨씬 빠르다. 즉, GPU의 코어는 단순연산에 맞추어져있다는 뜻이다.
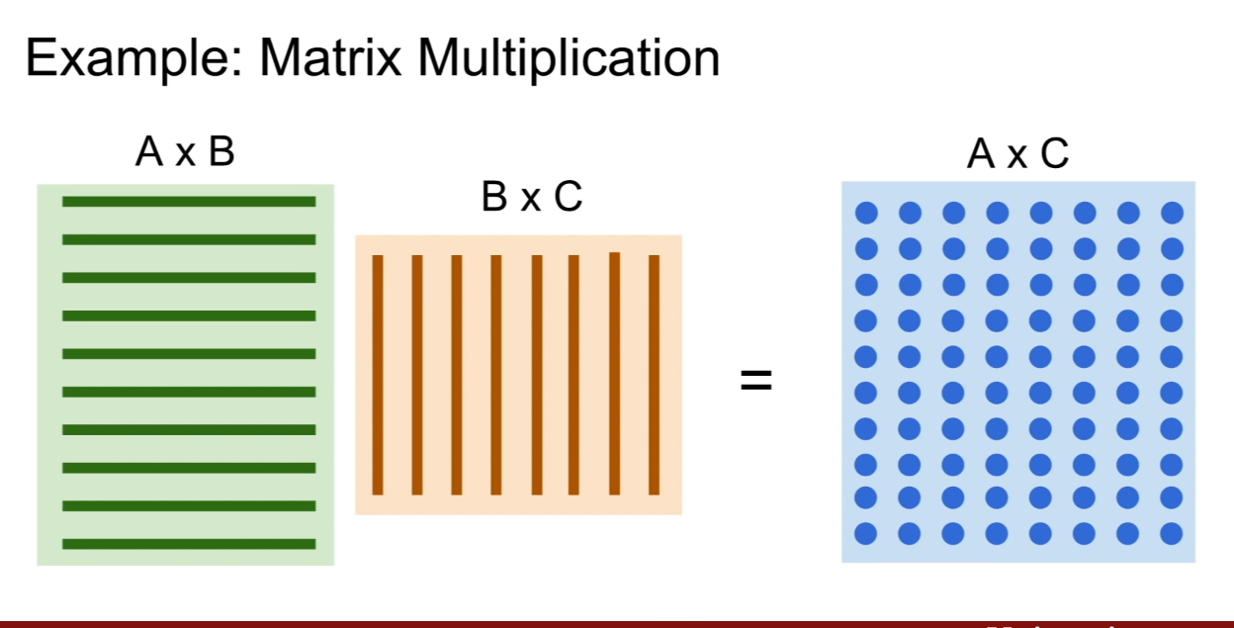
위와 같은 행렬 연산을 생각해보자. 행렬 연산은 결과값을 내는데 있어서 각 원소의 값이 모두 독립적으로 계산될 수 있다. 그런데 이것을 적은 수의 CPU로 sequential하게 일일히 계산하면 매우 느릴 것이다. 반면에 GPU는 코어수가 많으므로 이 행렬 계산을 한번에 수행해낼 수 있다. 즉, CPU는 AxC행렬의 원소를 하나씩 계산하는 반면, GPU는 AxC행렬의 원소를 각 코어가 하나씩 계산하여 동시에 딱! 내놓을 수 있는 것이다.

GPU 프로그래밍을 위한 소프트웨어가 있다. 딥러닝에 주료 사용되는 CUDA가 대표적인 예이며, CUDA를 편하게 사용하기 위한 higher level API인 cuBLAS, cuFFT, cuDNN등이 존재한다.
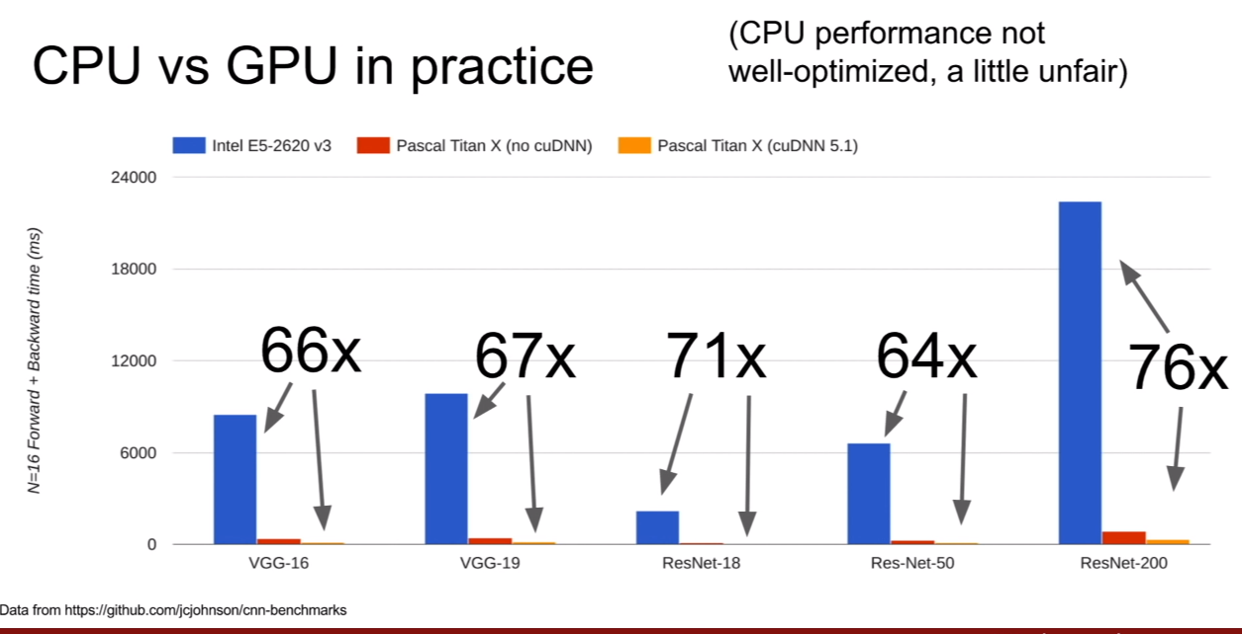
그림은 CPU와 GPU로 훈련을 시킬 때 시간 차이를 나타낸다. 그냥 비교도 안될만큼 GPU가 빠르다…

훈련시 가장 중요하게 생각해야할 부분 중 하나가 바로 data transfer의 병목현상(bottleneck)이다. 어떤 뜻이냐 하면, GPU에 처리해야할 데이터가 올라가야 한다. 그런데 우리가 훈련시킬 데이터가 100GB인데 이게 한 번에 다 올라가서 처리가 될 수가 없다고 하자. 그러면, 우리는 나머지 데이터는 다른데 저장해놓고, 필요할 때마다 GPU로 불러와 연산을 해야하는 것이다.
그런데 이 때 데이터가 전부 HDD에 저장되있다면, GPU가 다음 데이터를 가져오는데 시간이 너무 오래걸려 GPU가 아무리 좋아도, 훈련 시간이 더 오래 걸릴 것이다. 이를 위한 방법은, HDD를 SSD로 바꾸어 RAM으로 전송속도를 빠르게 하고, RAM의 용량을 늘려, GPU로 전송할 수 있는 대기 데이터의 양이 많아지게 하는 것이다. (SSD->RAM->GPU)
deep learning 프로그래밍을 위한 프레임워크는 Caffe2, Pytorch, Tensorflow가 많이쓰인다고 한다. 주변에는 대부분 pytorch, tensorflow를 사용한다. 나머지는 거의 못봤다.
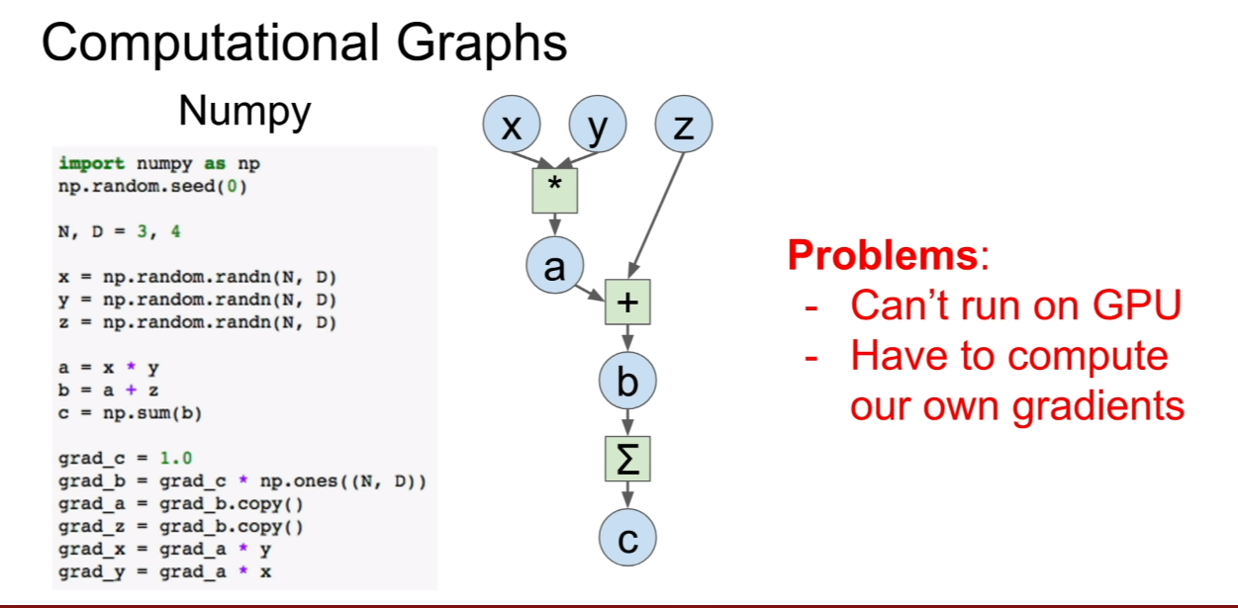
넘파이를 이용하여 딥러닝을 위한 그래프를 작성하려면 우리가 일일히 그라디언트를 작성해줘야하는 문제점이 존재하고, GPU에서 작동시키지 못하기 때문에 문제가 생긴다.

그에 반해 tensorflow는 위 슬라이드의 문장을 통해서 CPU에서 동작할지, GPU에서 동작할지 설정을 해줄 수 가 있다. (cpu:0 은 첫번 째 cpu를 의미한다. 첫 번째 gpu는 gpu:0으로 고치면된다.)

그 후, 간단한 문장을 통하여 그라디언트를 계산할 수 있다.

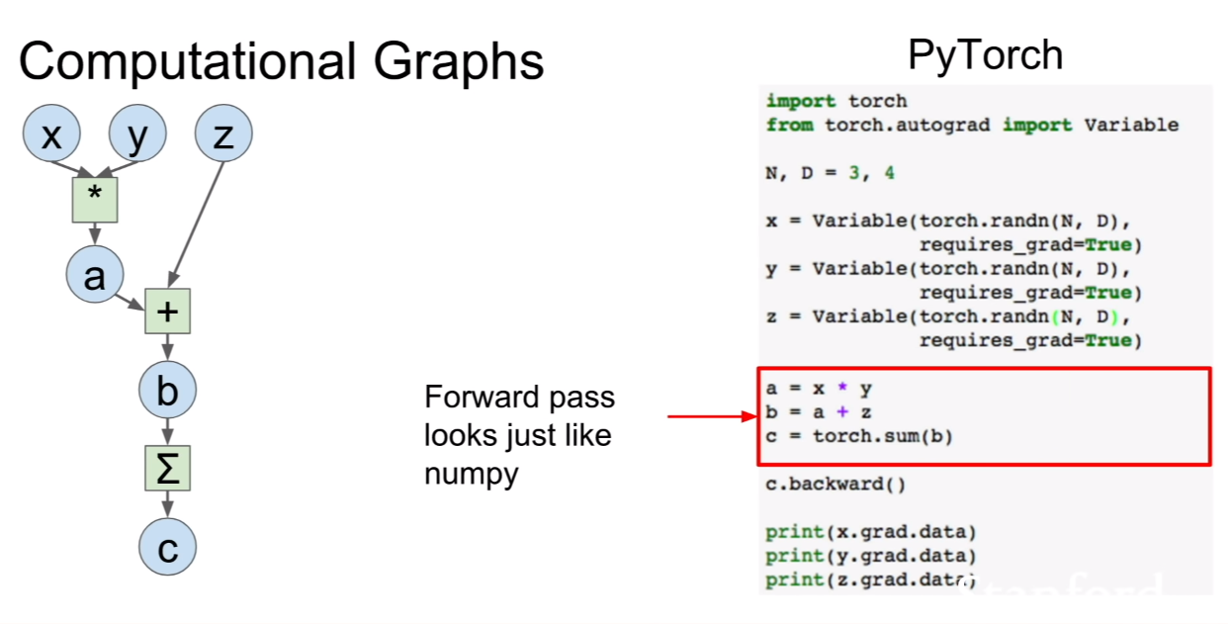

pytorch도 간단하다. 변수를 선언하고, 포워드를 한 후 백워드를 하면 훈련이 진행된다.

변수 뒤에 .cuda라는 것을 붙혀, gpu에서 연산을 하도록 바꾸어 줄 수 있다.

넘파이, 텐서플로우, 파이토치간의 코드를 비교하면 위 슬라이드와 같다.
Deep learning framework
Tensorflow


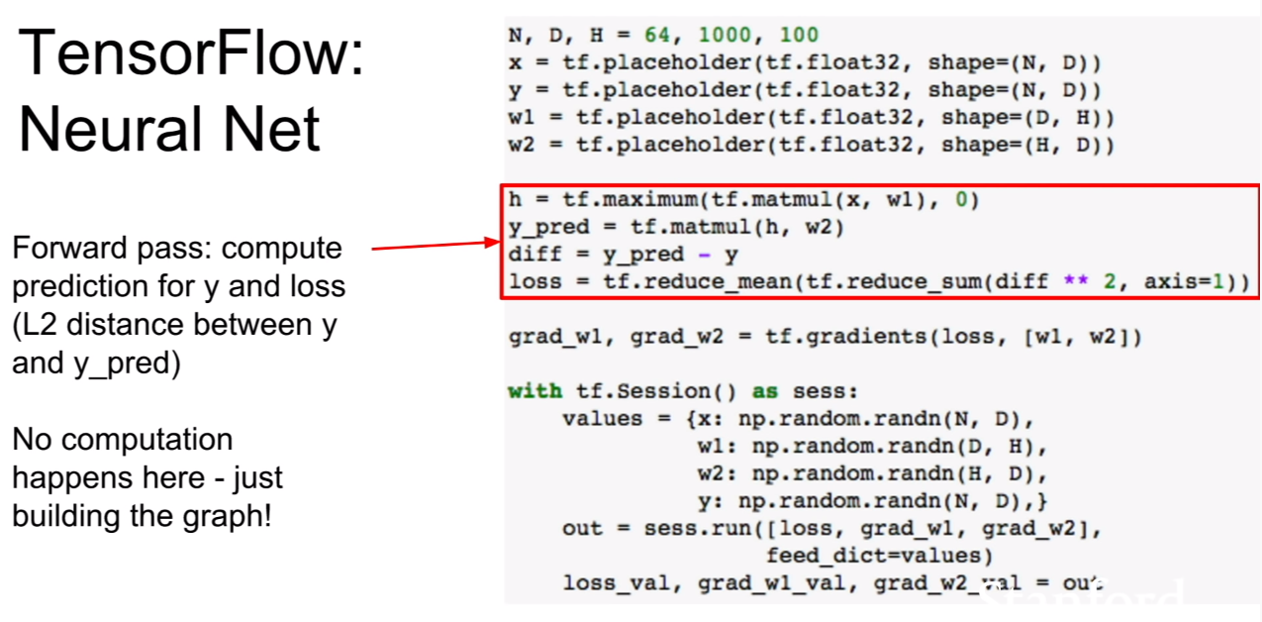




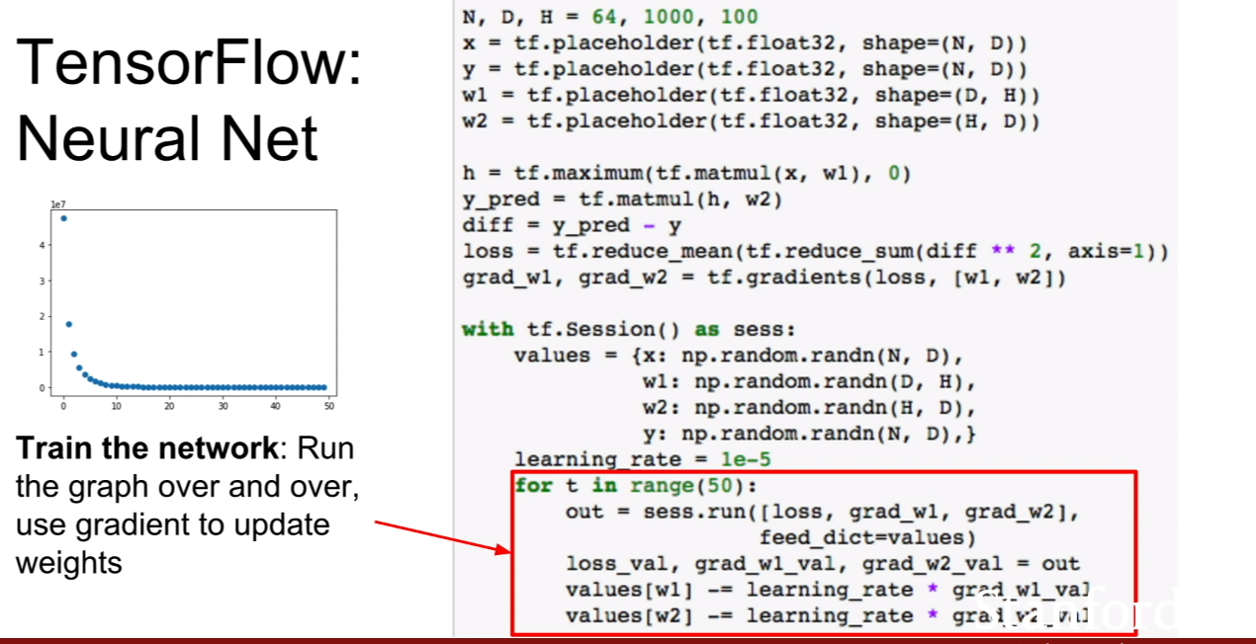
텐서플로우의 기본 흐름은 위와 같다.
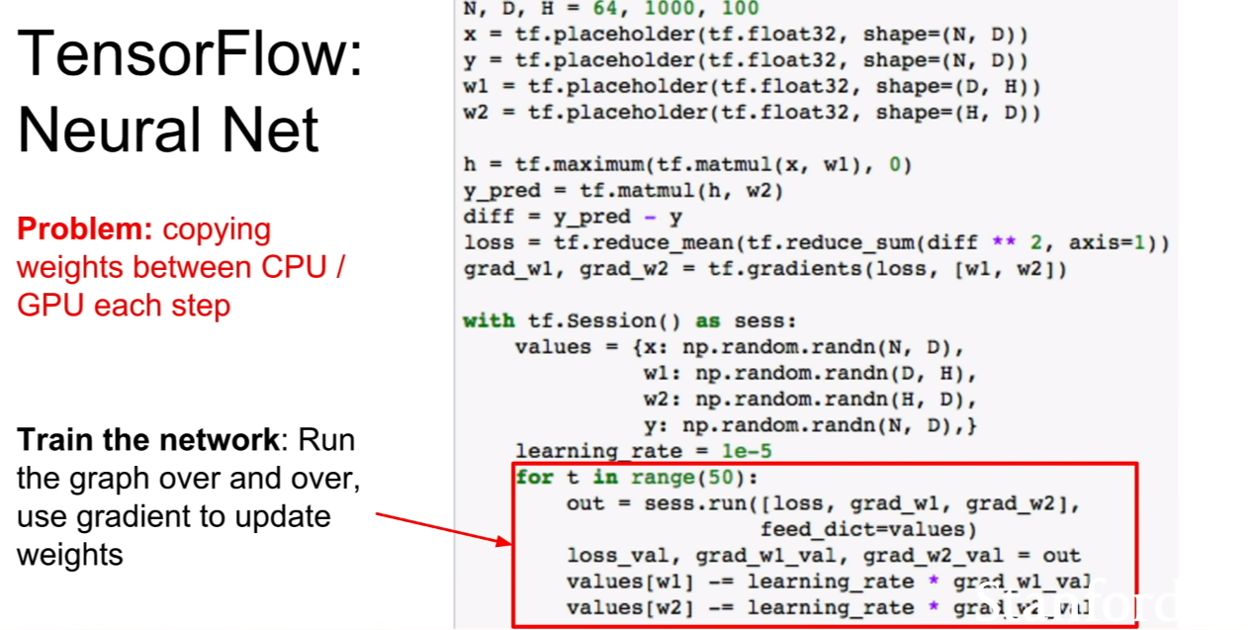
하지만 위와같이 코드를 작성하면 문제가 생기는데, 바로 CPU에서 GPU로, GPU에서 CPU로 데이터의 복사가 일어난다는 점이다. 두 장치간 복사는 매우 비용이 큰 연산이다. 그렇다면 어떤 부분에서 복사가 일어난다는 것일까?
바로 placeholder에 sees.run에서 feed_dict를 통해 값을 넣어주는 과정이다. values는 CPU, placeholder는 GPU에 있다고 해보자. 그러면 feed_dict에서 데이터는 매번 저장장치에서 가져오므로 복사가 되는것은 어쩔 수 없는 일이다. 하지만 저장된 가중치는 매번 CPU에 있을 필요가 없다. GPU에 존재하여 업데이트를 계속 진행하면 되는데, GPU에서 연산을하고 values라는 CPU에 존재하는 변수에 저장하고, 다시 feed_dict를 통해 GPU에 올려 업데이트를 진행하니 아주 비효율적인 코드가 되는 것이다.
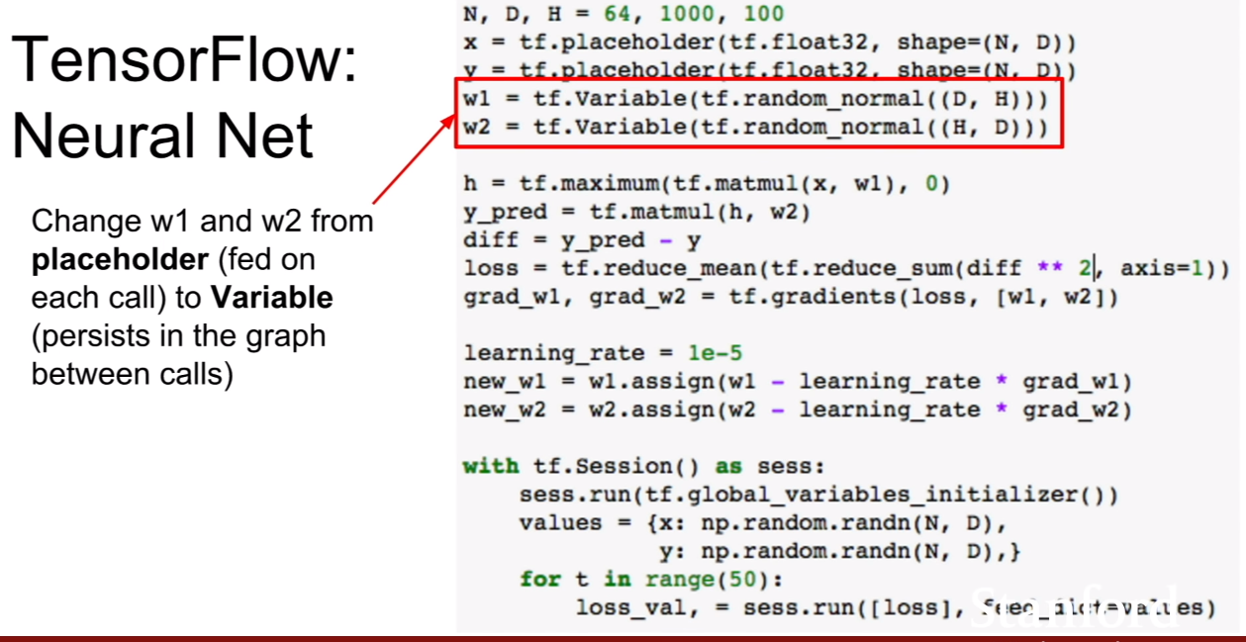
이와 같은 문제점을 막기 위하여 가중치를 placeholder로 사용하는것이 아닌 tf.Variable로 사용해주는 것이 아주 바람직하다.
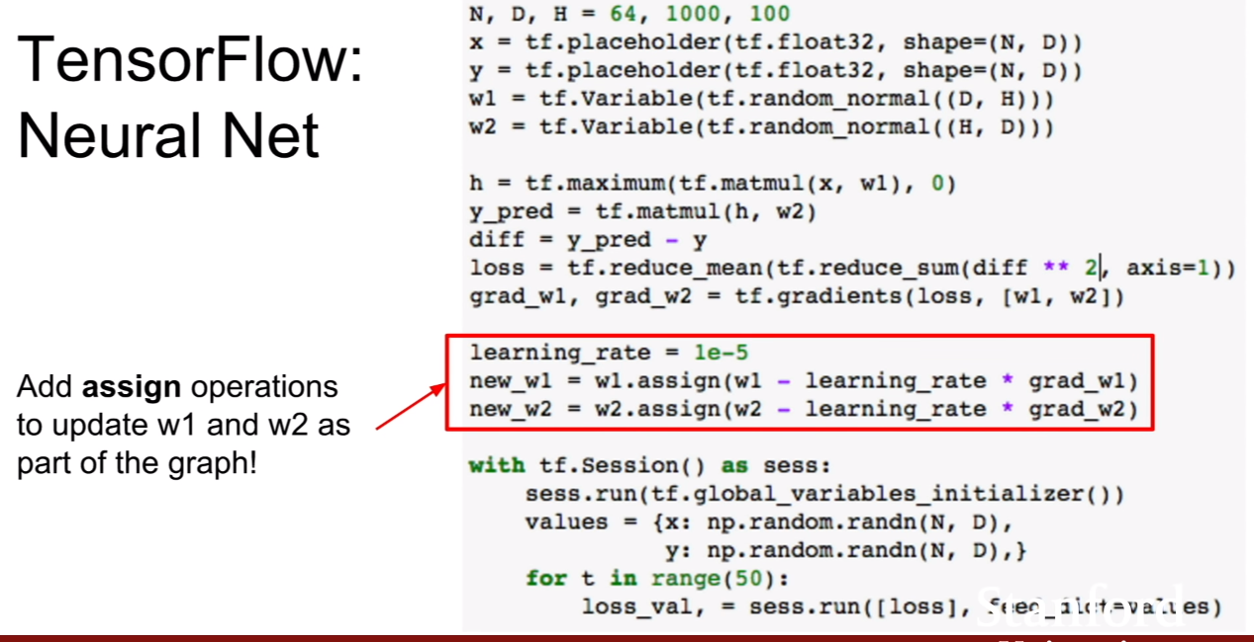
그 후, assign함수를 통하여 variable이 그래프의 일부가 될 수 있도록 업데이트 해준다.
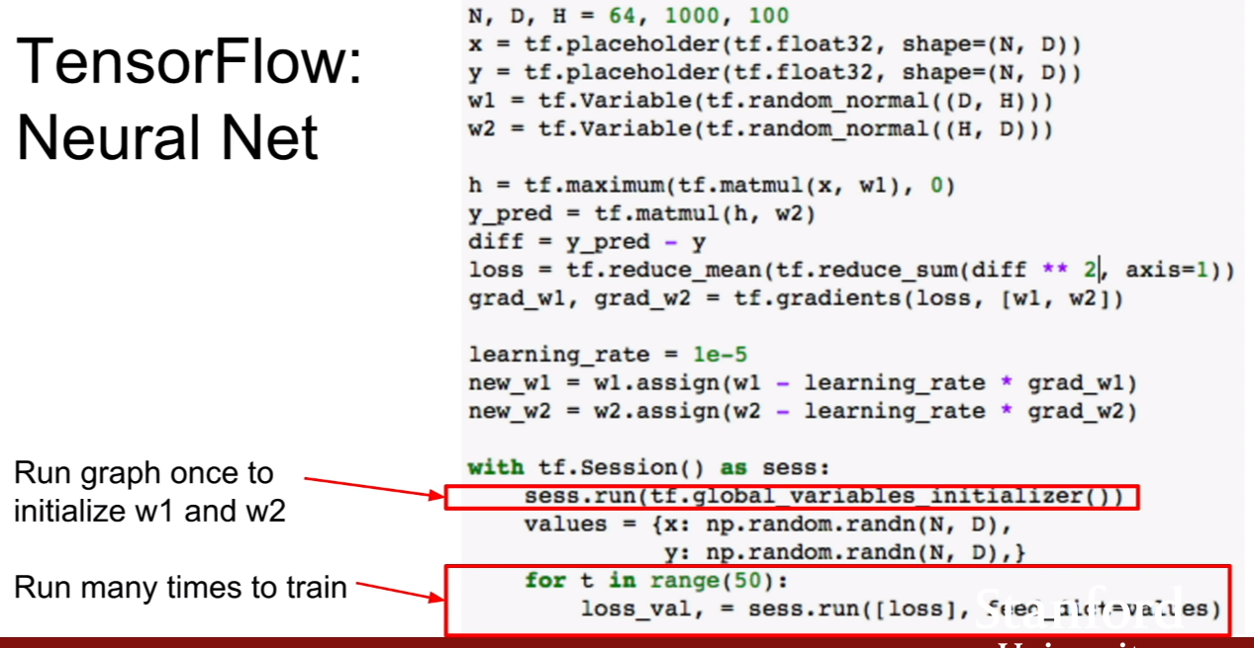
Variable을 사용할 경우에는 위 슬라이드와 같이 golbal-variables_initializer를 실행시켜주어야 하고, sees.run은 똑같이 실행시켜주면 된다.
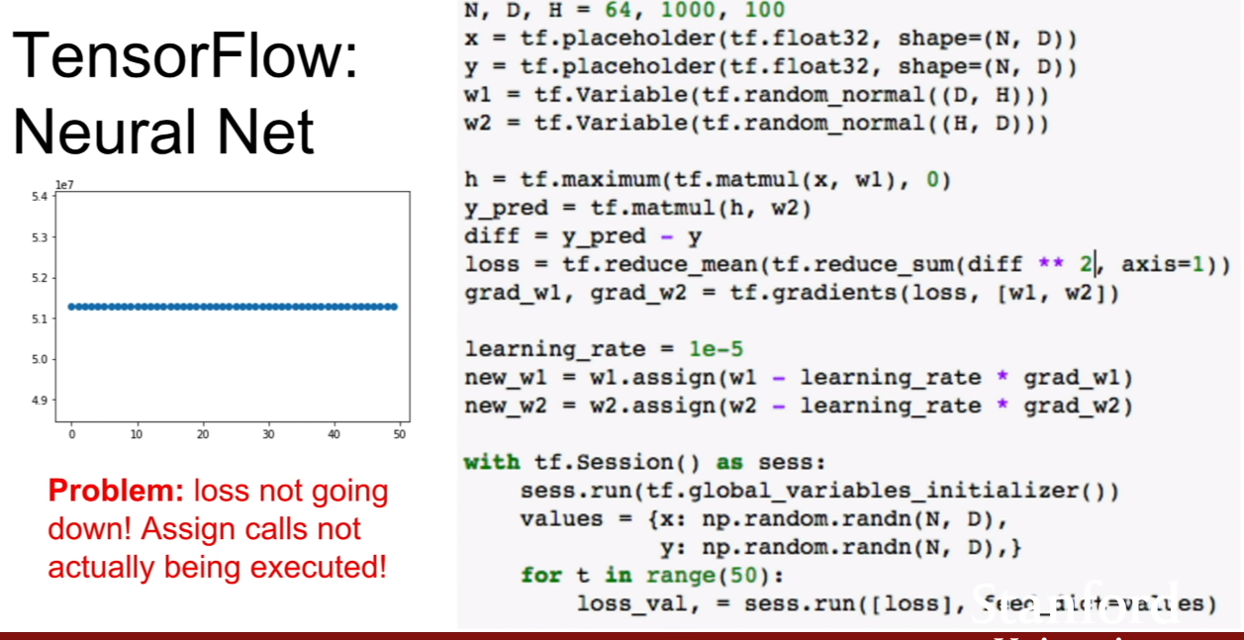
그런데 이상하다? loss가 업데이트가 되지 않는다. 왜 업데이트가 되지 않는걸까? 그 이유는 바로 sess.run에 new_w1과 new_w2를 넣어주지 않아서 그렇다. 즉, sess.run([loss, new_w1, new_w2])가 되어야 한다. **여기서 알아야할 점은, new_w1.new_w2는 출력값이다. 즉, w1.assign(a)라고 하면 w1=a가 되고, w1의 값을 내뱉는 것이므로. w1은 이미 값이 바뀌어져 있다. **
이것이 어떤 말이냐 하면, tensorflow는 computational graph방식으로 구성되어있다. 즉 sess.run([loss])를 하게 되면 loss를 계산해주는 forward pass까지밖에 진행이 안된다는 것이다. grad_w1즉, 그라디언트를 계산하는것, 가중치를 업데이트 하는 연산등 그래프에는 정의되어 있지만, 해당 노드를 계산하도록 run을 안해주었기 때문에 계산이 안되는 것이다.
그렇다면 모든 노드를 일일히 넣어줘야되는가? loss만 넣어준 모습을 보면 아니라는 것을 알 수 있다. computational graph의 계산의 끝에 존재하는 노드만 넣어준다면 이전까지 정의된 그래프의 연산이 모두 실행된다. 그 후 최종적인 노드만 출력하는 것이다.
그러므로 backward시에는 backward의 최종노드인 new_w1과 neww_2를 넣어주면 되는것이다. 하지만 이렇게 두 개 다 쓰면 가독성이 떨어지므로, 위 슬라이드에서는 updates라는 더미노드로 묶어 해당 노드를 sess.run에 넣어준 모습을 볼 수 있다.

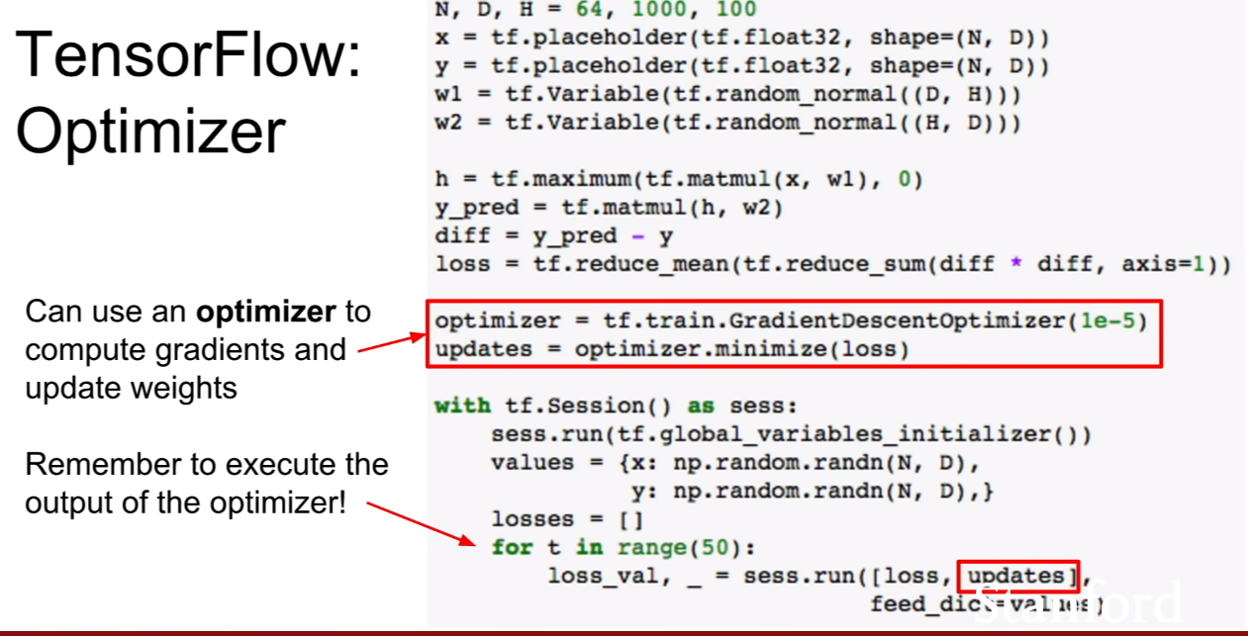
하지만 이 강의를 듣지않고, 그냥 텐서플로우 실습만 해보았다면, 어 이런? assign함수는 써본적이 없는것 같은데? 라고 생각하는 사람들이 많을것이다. 그 이유느 바로 optimizer함수를 사용해왔기 때문이다. 이 함수 안에서 해당 과정을 모두 처리해주고 있는 것이다. 그렇기 때문에 코드가 훨씬 간단해지는 모습을 볼 수 있다.
우리는 가중치를 변수로 선언할 때, 곱해져야할 matrix multiplication의 차원을 고려하여 설정해 주어야한다. 그런 부분까지 해결해주는게 tf.layers.dense라는 함수이다.



tensorflow의 wrapper인 keras를 강의에서 소개해준다. 이게 의마하는것은 안에는 텐서플로우로 동작하는데 더 사용하기 편하기 쉽게 감싸놓은 프레임워크인 것이다.

이와 같은 wrapper의 종류는 위 슬라이드에 나와있다. 아마 더 존재하지 않을까 싶다.

강의에서 텐서보드에 대해서 간략하게 언급하고 있다. 우리가 설계한 computational graph, loss, 등을 가시화해서 보여주는 아주 고마운 도구이다.
Pytorch

이번에는 pytorch에 대해서 살펴볼 것이다. 조금더 pytorch가 tensorflow에 비해서 단순화 되있는 느낌을 받을 수 있다.
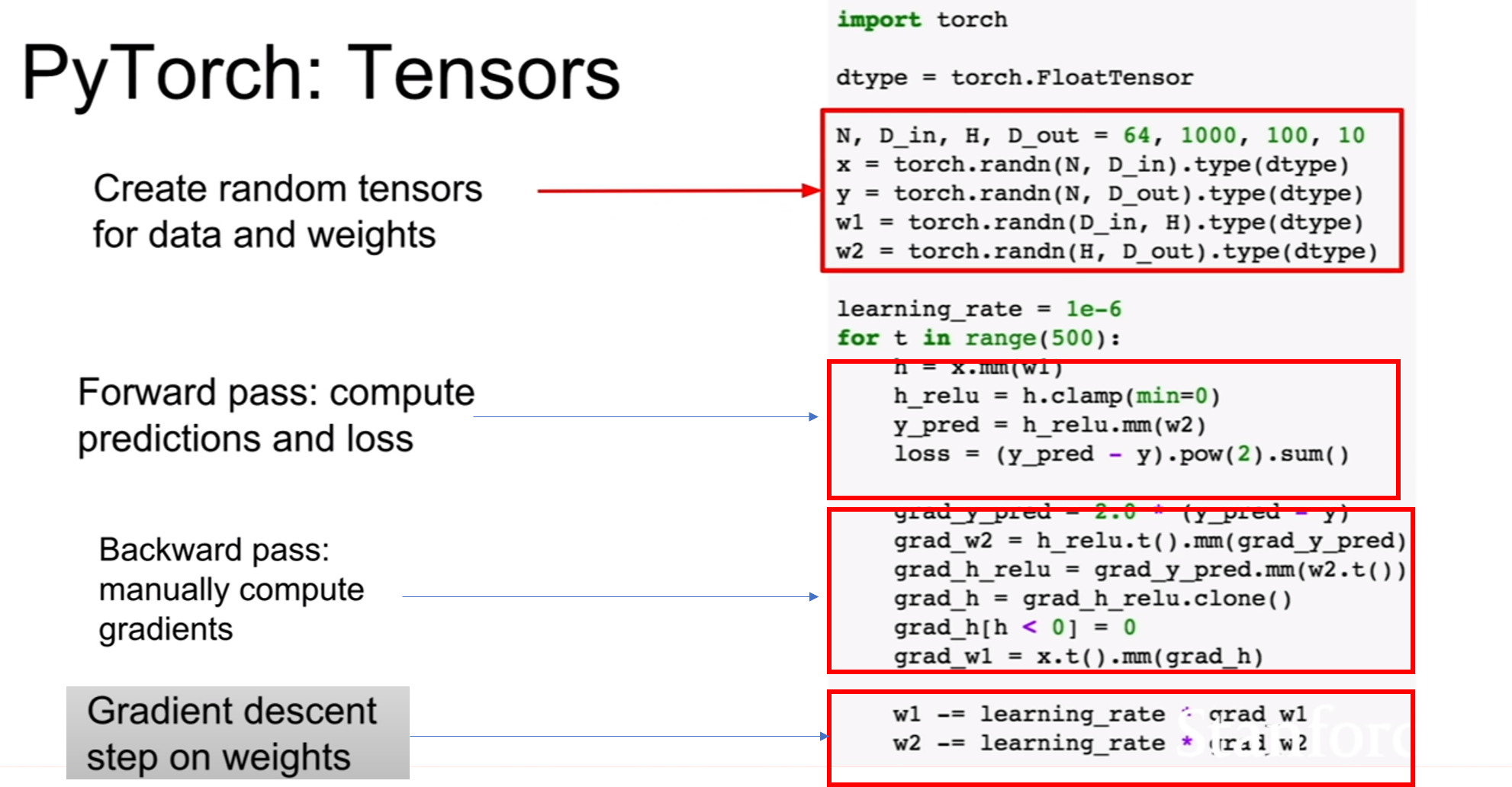
random tensor를 생성하고, forward와 backward가 있으며 gradient를 update하는 과정이 존재한다. tensorflow의 큰 흐름과 다르지 않은 모습을 볼 수 있다. 하지만 세부적으로 봤을 때, tensorflow는 computational graph를 그려 계산한다는 느낌을 받는다면, pytorch는 computational graph보다 sequential한 프로그래밍 코드를 짜는 느낌에 가깝다. 즉 우리가 평소에 프로그래밍 하는 방법과 비슷하다는 것이다.
그 예로, tensorflow는 sess.run을 통하여 graph의 operation을 직접 실행시켜주어야 하지만, pytorch는 코드를 쓰기만 하면 해당 연산이 진행되는 모습을 볼 수 있다.

파이토치의 텐서는 넘파이+GPU라고 생각하면 된다고 한다. 즉 numpy를 감싸 GPU에서 연산할 준비를 마친게 텐서라고 생각하면 된다. 크게 특별할 것 없이 gpu 자료형을 정의해 준 후, torch.tensor.type(dtype)과 같이 사용해주면 된다고 한다.
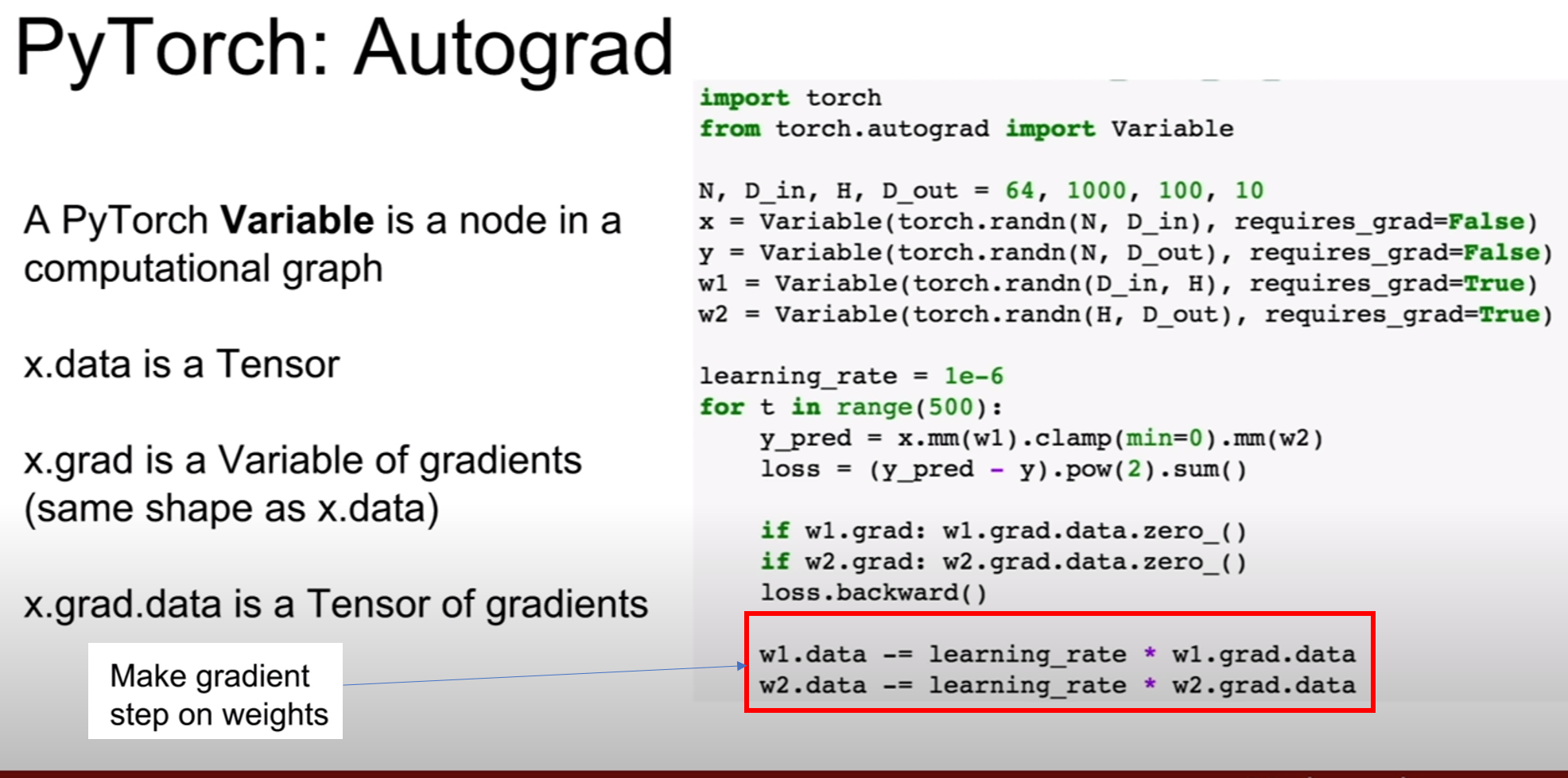
파이토치의 텐서를 Variable로 감싸면 그제서야 텐서프로우와 같이 computational graph에 들어갈 준비를 마치게 된다. 그 말은 즉슨, 텐서플로우에서 gradient를 계산해주거나, optimizer을 이용하여 그라디언트를 계산하고 역전파를 해주었듯이, 파이토치에서도 해당 연산이 가능해졌다는 점이다. 텐서만을 이용해서 학습하려고 했을 때는 우리가 직접 그라디언트를 계산하고 업데이트까지 해주었지만, 위 슬라이드를 보면 loss.backward()를 통하여 그라디언트 계산및 역전파 까지 해준 모습을 볼 수 있다.
그라디언트 업데이트는 직접 코드 작성을 하여야한다.
p.s 파이토치의 텐서와 variable은 같은 API를 사용하기 때문에, 텐서에서 가능한 연산은 variable에서 거의 다 가능하며, 그 역도 마찬가지이다.

그렇다면 나만의 Autograd를 만들어보자(Autograd DIY라 할 수 있겠다.) 이 때, torch.autograd.Function클래스를 상속받는 것 부터 출발한다. forward부분에는 입력을 받고 ReLU함수의 기능대로 출력값을 내보내주면 된다. backward에서는 함수의 파라미터로 grad_y를 갖는다. grad_y는 backpropagation 될 때, 이전 까지 역전파 되어온 미분 값이라 생각하면 된다.
backward함수를 보니, autograd.Function에는 saved_tensors라고 forward때 입력받았던 텐서를 저장해두는 변수가 있는것 같다.
사실 Autograd를 우리가 만든다는 것은 그 함수의 미분값을 직접 구해줘야 한다는 것이다. 그 부분을 수행하는 것이 grad_input[x<0], return grad_input인 부분이다. 만약에 입력값이 0보다 작았다면 ReLU에 의해 기울기가 0 이므로 역전파의 값은 0이 될것이고, 0초과라면, 기울기가 1이되어, 여태까지 받았던 역전파값에x1이 됨으로, grad_input을 그대로 return한 것이다.

이렇게 만든 ReLU클래스는 상속받은 클래스에 미리 정의해놓은 함수 때문에, 일반 함수들 처럼 사용하면 된다.
p.s pytorch의 Autograd에 대하여 다음 유튜브 영상이 자세히 설명해주고 있다. requires_grad의 설정에따라 forward와 backward관계의 변화에 따른 cyclie graph의 변화와, backward가 어떻게 진행되는지 설명해주고 있다. 이 동영상에서 주의깊게 볼것은 grad_fn이라는 속성이다. grad_fn은 사용자가 직접 만든 텐서에는 grad_fn=None으로 초기화된다. 즉, 곱, 합, 차 등의 연산으로 나온 텐서에는 grad_fn에 해당 연산이 입력되게 된다. 이 속성을 이용하여 backward함수를 출력시 함수 체인을 통하여 모든 연산에 관한 backward가 차례대로 불려지면서 미분값이 전달되는 것이다. YangSpace블로그의 pytorch의 AUtograd를 제대로 이해하기글을 참고해봐도 좋을것 같다.

pytorch의 nn module을 이용하여 keras와 비슷하게 동작시킬 수 있다.

텐서플로우에 옵티마이저가 있다면, 당연히 파이토치에도 옵티마이저가 존재한다. 가중치 업데이트룰을 optmizer로 설정해주는걸로 바꾸고, 가중치를 수동으로 업데이트 하는 구문을 써줬던 것을 optimizer.step()으로 바꾸어주면 된다.

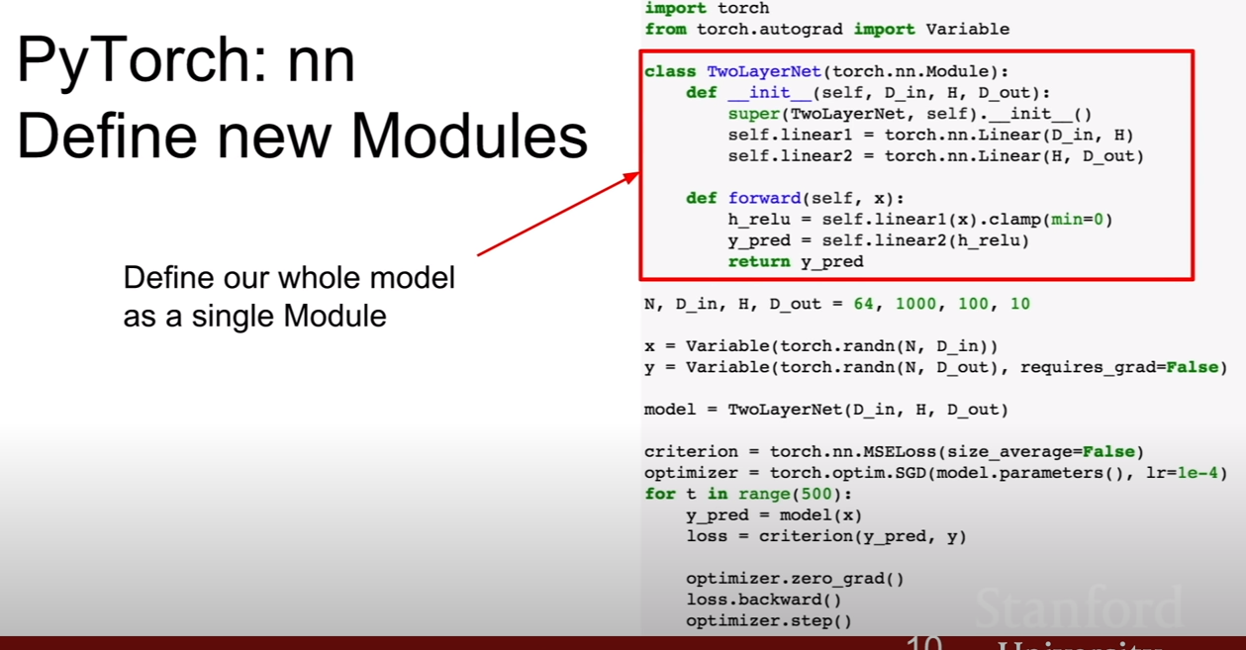


우리만의 Autograd를 만든것 처럼, 우리만의 nn module을 만들 수 있다. autograd 방식과 비슷하게, torch.nn.Module클래스를 상속받는다. init에 우리가 필요한 레이어를 정의한다. 그 후, forward부분에 우리가 정의한 레이어를거쳐 어떻게 연산이 될지를 정의하고, 결과값을 반환한다.
위 예제처럼 전체 레이어를 담는 모듈을 만들어 아예 모델을 만들어버릴 수 있으며, 특정 기능만을 수행(attention, residual connection 등)하는 모듈을 만들어낼 수 있다. 사용법은 nn module을 사용하는것과 동일하다.

다음에 살펴볼 것은 파이토치의 DataLoader이다.데이터로더는 데이터셋을 감싸서(wrapping) 미니배치, 셔플링, 멀티스레딩등을 더 쉽게 제공해주는 파이토치의 도구이다.
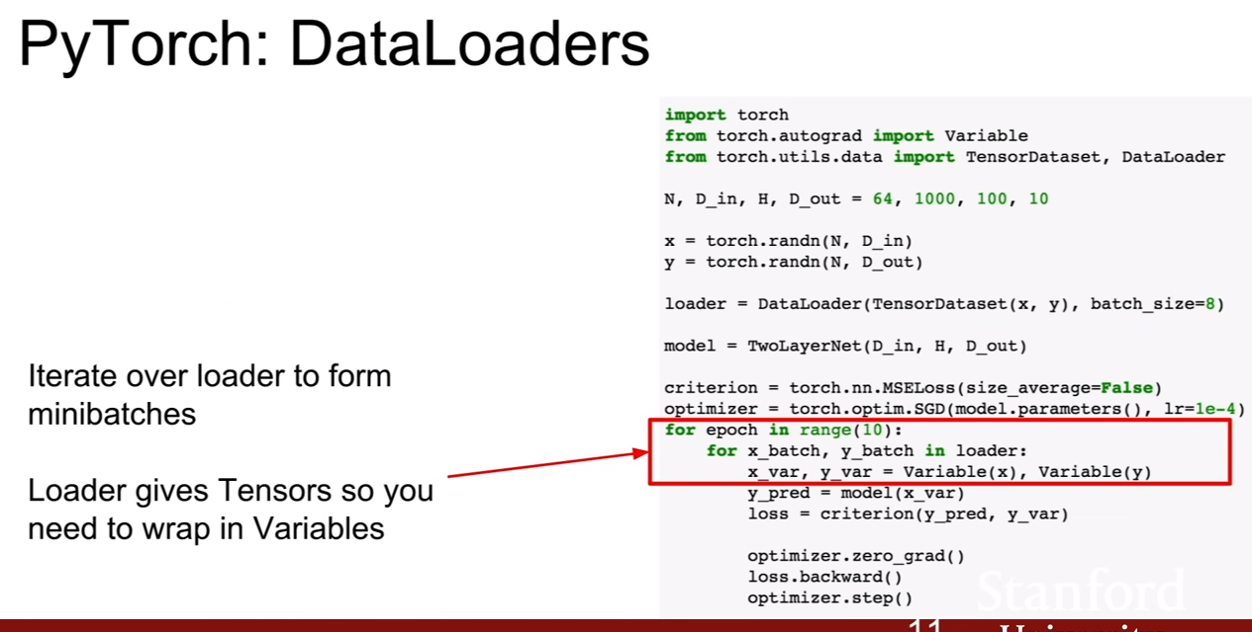
이터레이터는 데이터로더에서 미니배치를 주기 때문에, 그것을 받아 Variable로 감싸기만 하면 computational graph를 완성시킬 수 있다.

pytorch에서 pretrained model을 제공하니, 이것을 사용하여 실습을 해보는 것도 좋을것 같다.
텐서플로우에 텐서보드가 있다면, 파이토치에는 비즈덤(visdom)이 존재한다. 이것 또한 시각화 도구이다.
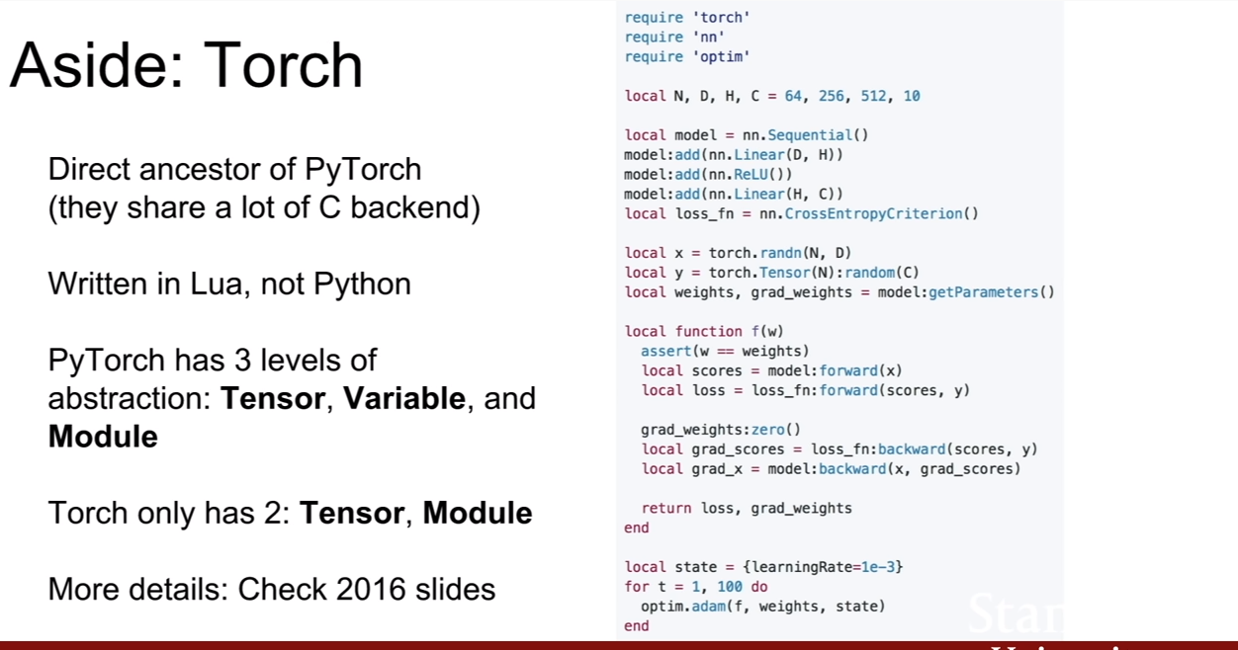
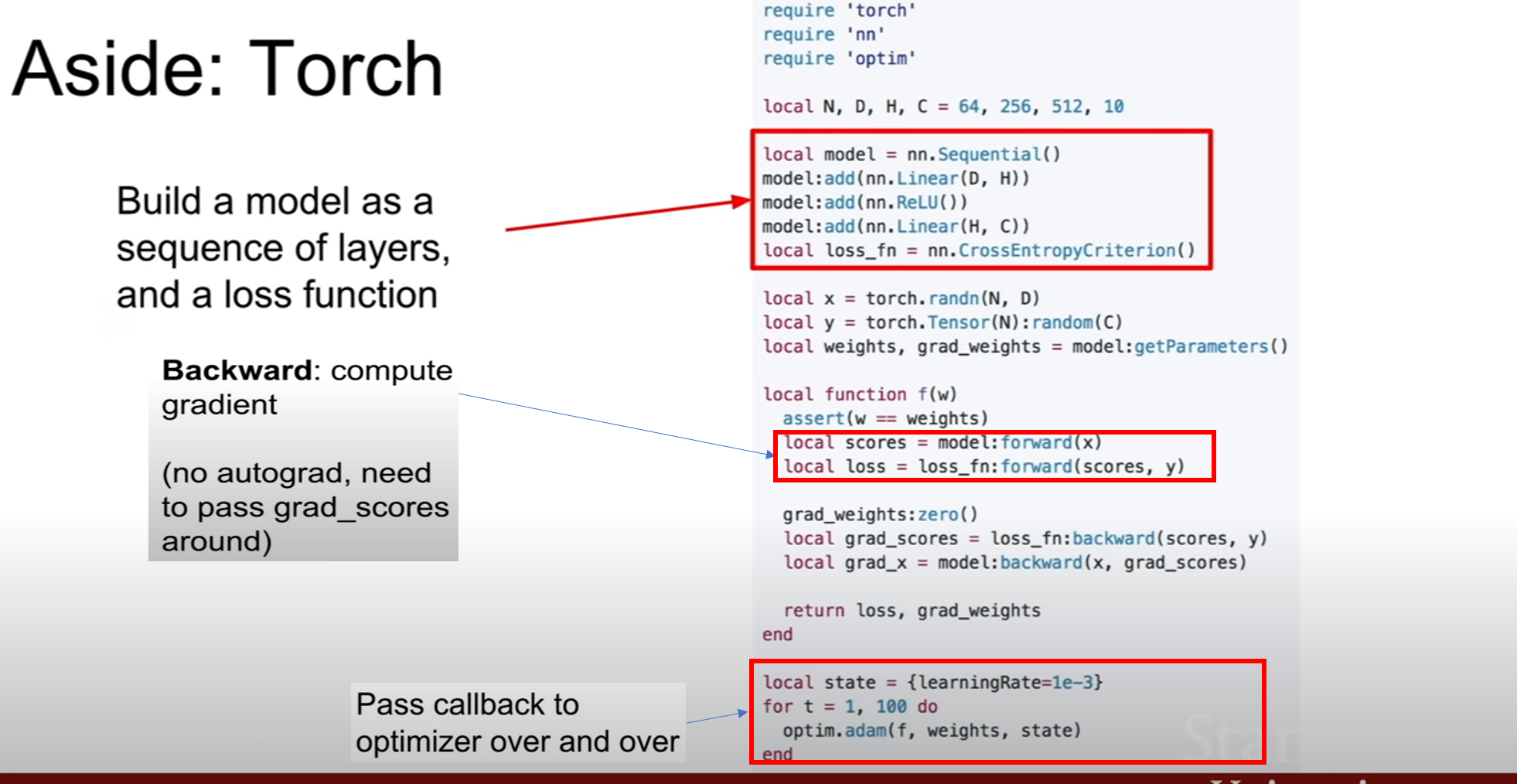

강의에서 루아(Lua)로 쓰여진 토치(Torch)가 있다는 것만 간략히 설명하고 넘어갔다.
TF vs PT (static vs dynamic graphs)

텐서플로우는 그래프를 정적으로 만드는 반면, 파이토치는 그래프를 동적으로 만든다. 정적으로 만든다는 것은 한번 그래프의 빌드가 끝나면 그래프의 구조는 변하지 않는다는 것이다. 반면 파이토치는 반복문을 반복할 때 매번 새로운 그래프를 만들어낸다. 심지어 똑같은 그래프라도 말이다.
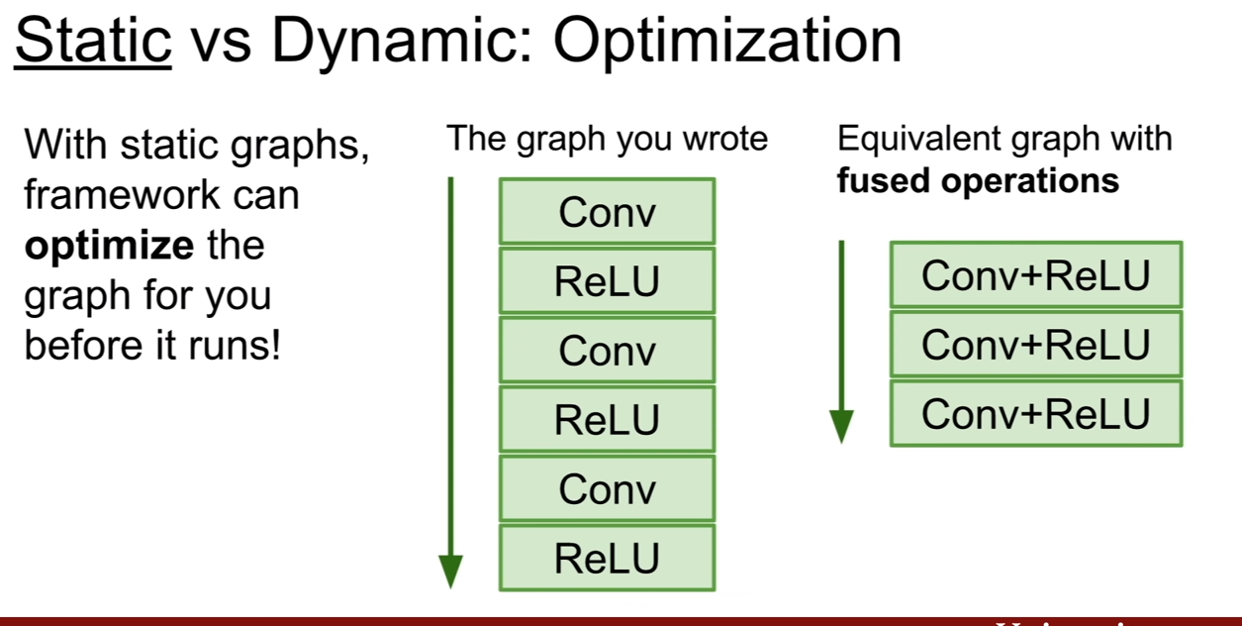
정적인 그래프는 최적화에 아주 용이하다. 위 슬라이드를 보자. Convolution 다음 ReLU를 거친다고 할 때, 이것을 두 개의 레이어로 표현하는것 보다. 하나로 합쳐 표현할 수 있다면, 함수를 참조하는 시간이 줄어들게 된다. 정적인 그래프에서는 모든 연산의 위치, 값, 관계등을 다 파악하고 있기 때문에, 이상이 없는 한에서 이런 최적화를 진행할 수 있는 것이다.

또한, 정적인 그래프의 장점은 직렬화(serialize)시킬 수 있고, 코드없이 빌드한 그래프를 실행시킬 수 있다는 것이다. 왜냐하면 바뀔 것이 없기 때문이다. 하지만 동적그래프는 다르다. 그래프가 빌드되었지만 상황에 따라서 그래프의 구조가 바뀔수 있기 때문에 주변에 항상 코드가 옆에 같이 존재해야 한다.

이런 성질은 분기만에서 더욱 두드러 진다. 파이토치는 일반적으로 프로그래밍하듯이 그래프를 작성하면 되지만, 텐서플로우는 tf.cond라는 분기문을 작성해주어야 한다. 조금 더 복잡한 gate가 추가되는 셈이다.
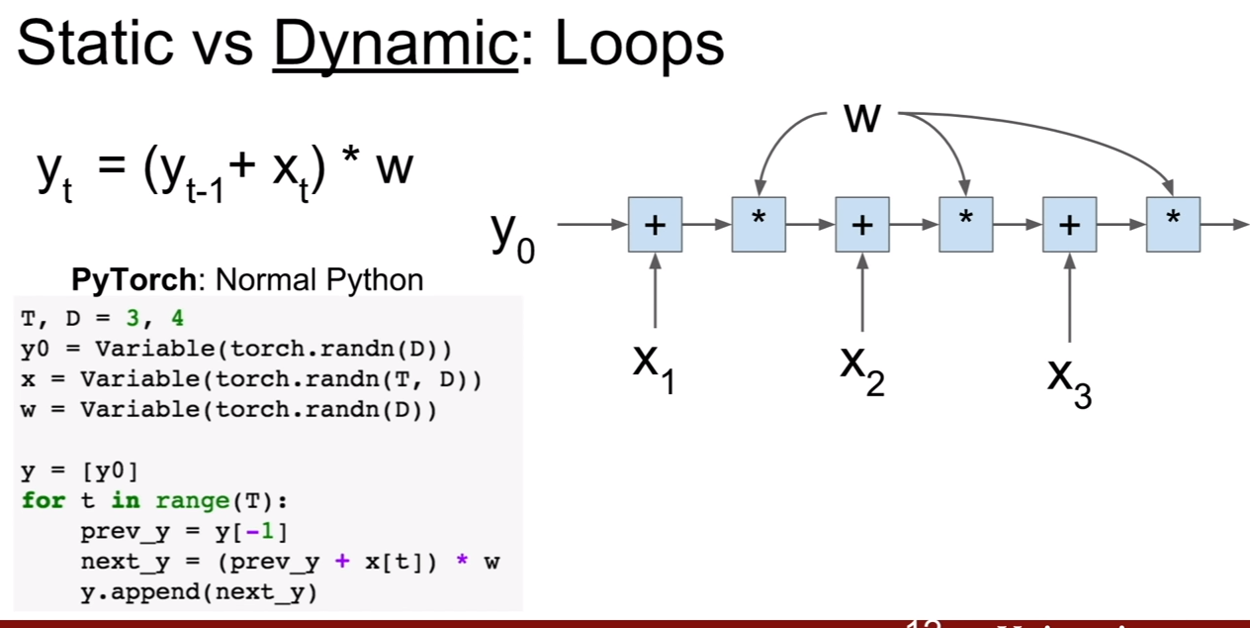


입력의 크기가 매번 달리질 수 있는 반복문을 생각해보자. 파이토치의 경우 그냥 파이썬의 반복문을 작성하듯이 작성하면 끝이난다. 하지만 텐서플로우에서는 그렇지 않다. 왜냐하면 일정 크기로 고정이 되야 하는데 계속 변하기 때문이다. 이 때, tf.foldl라는 구문을 넣음으로써 해결을 할 수 있다. 텐서플로우는 이렇게 명시적으로 표시를 해주어야한다. 이런 텐서플로우의 폴드(fold)는 dynamic batching을 통하여 동적 그래프를 더 쉽게 만들게 해주는 장치이다. (차라리 그냥 파이토치를 쓰는게 편할지도..)
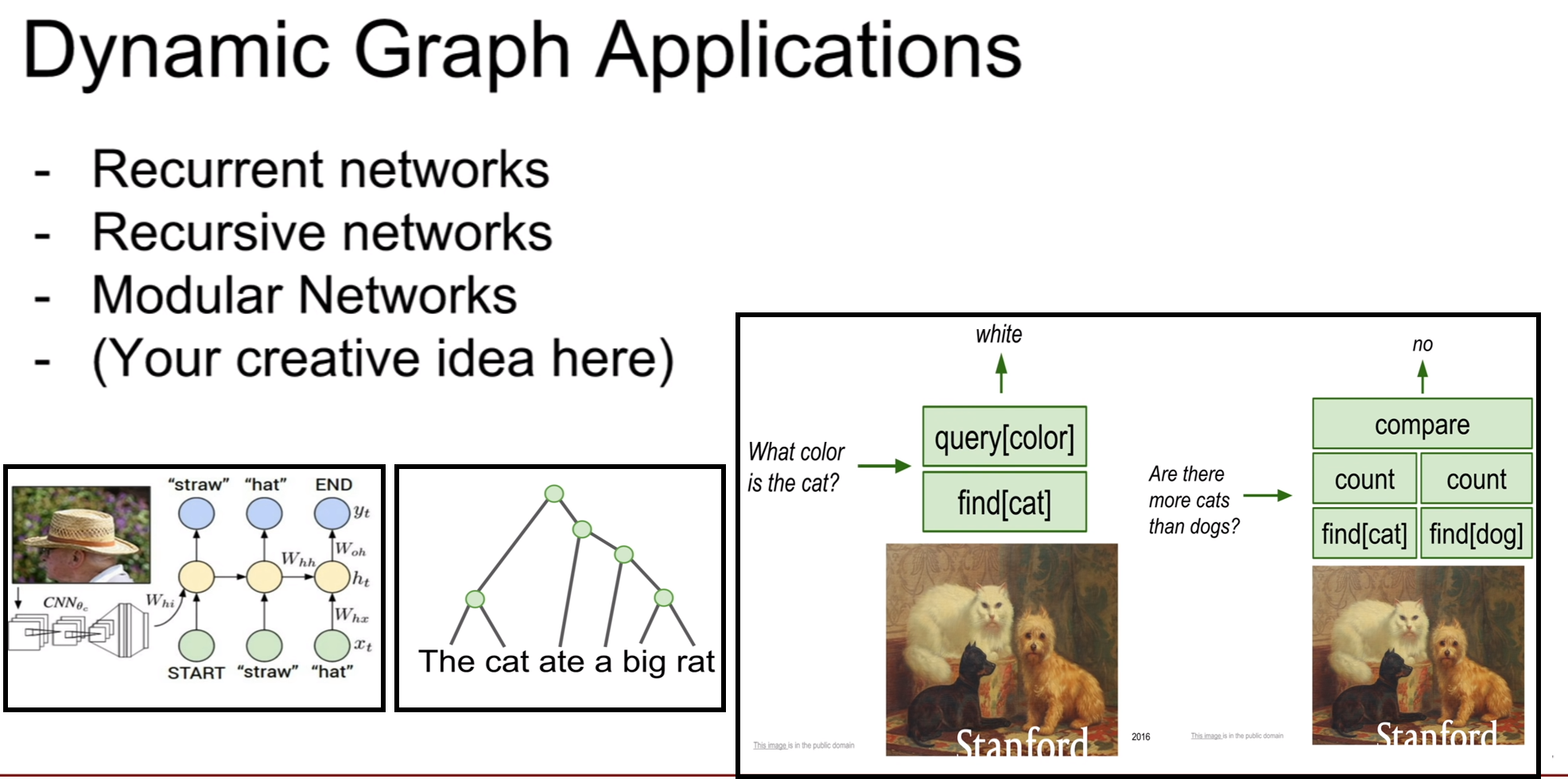
동적 그래프가 중요한 분야는 위와 같다. 아까 설명한 loop가 주를 이루는 알고리즘 인것 같다.
Caffe







강의에서는 Caffe 에서도 약간 다루고 있다.
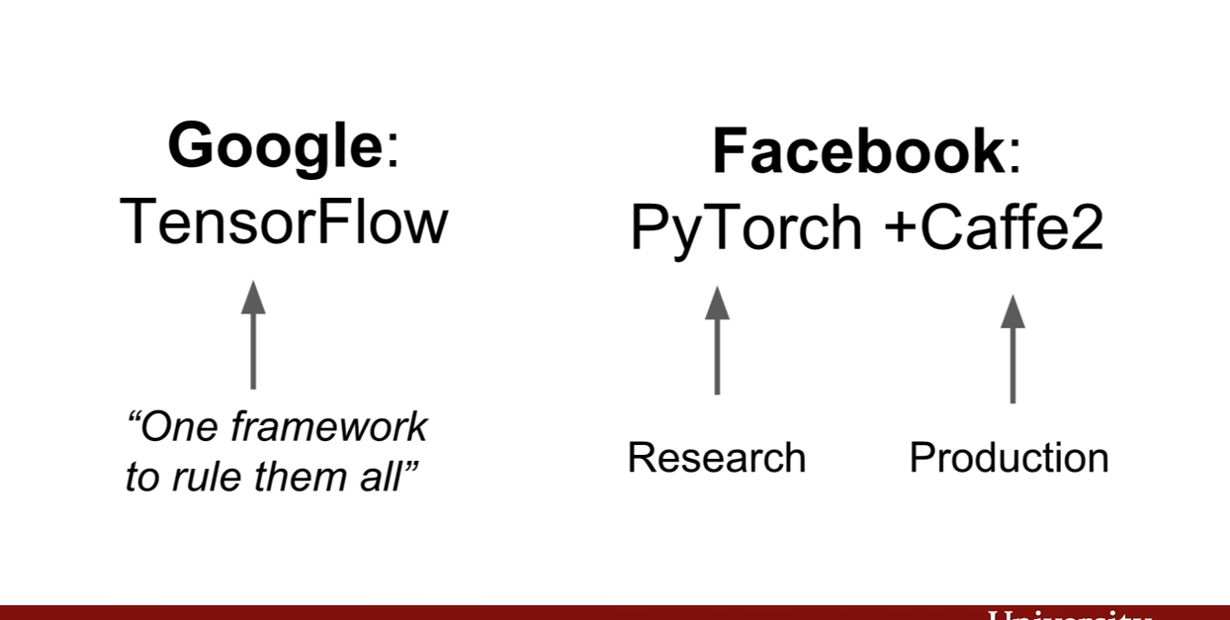

구글의 텐서플로우는 한 프레임워크안에서 모든걸 처리하려는 반면, 페이스북에서는 파이토치와 카페를 나눔으로써, 연구와 실제 응용분야에서 쓰이는 생산에 유리한 Caffe2로 나눈것 같다고 강의에서는 설명한다.