CS231n-Lecture05(convolution network)
20 Aug 2020 | CS231n목차
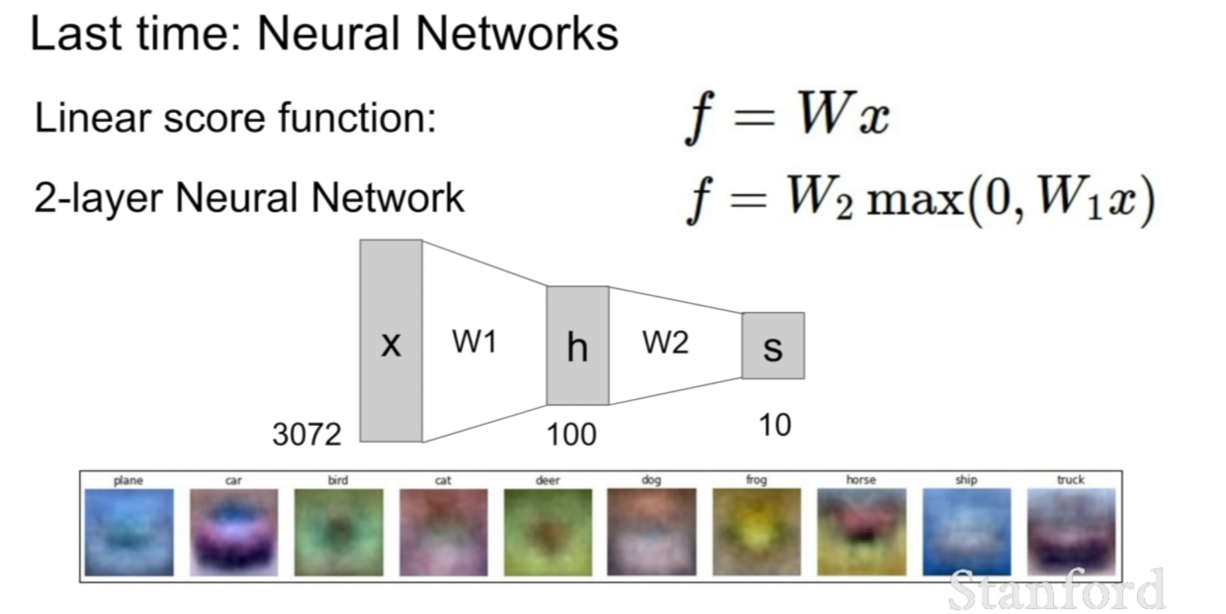
저번 시간에는 선형 분류기에서 어떻게 가중치가 곱해지고 역전파가 되며, 최적화가 되는지 살펴보았다.
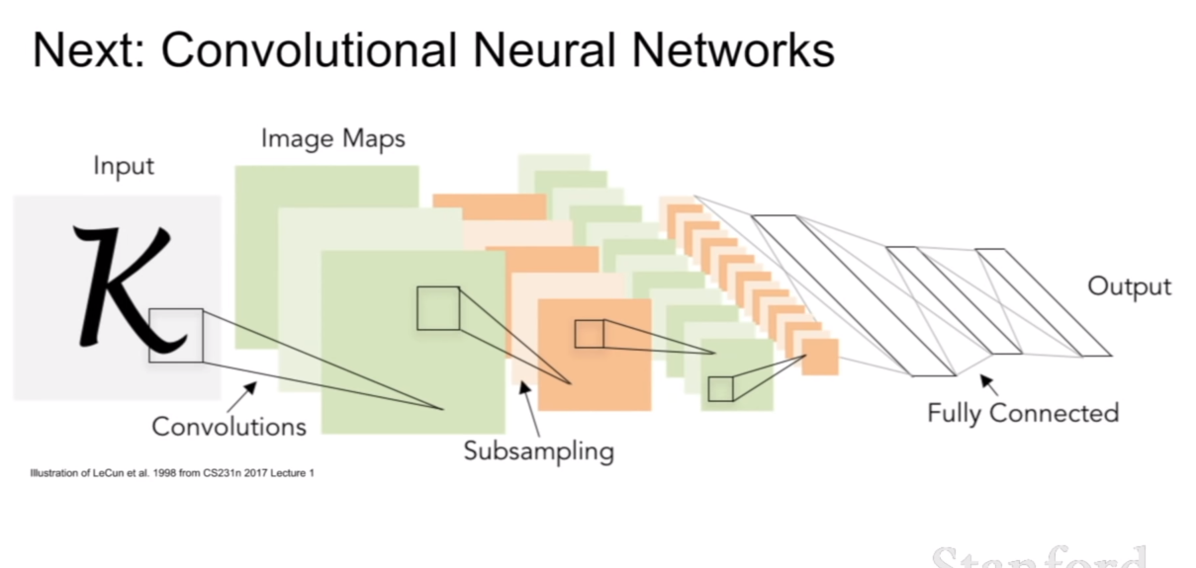
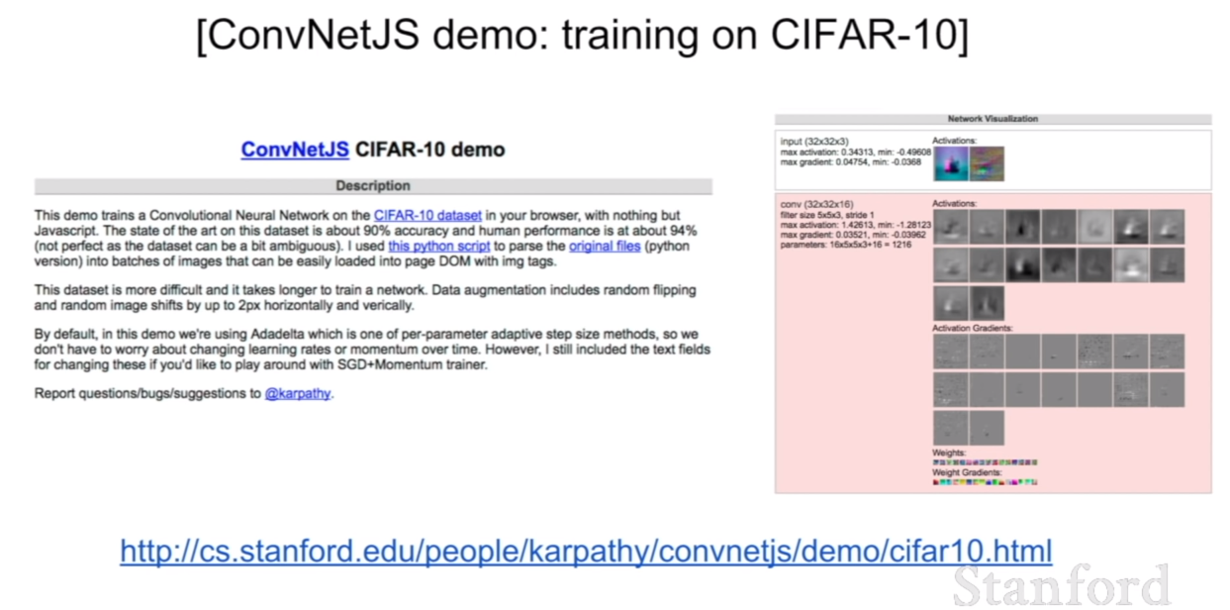
이번 시간에는 computer vision에서 아주 눈에띄는 성능의 향상을 불러 일으킨 컨볼루션 네트워크(convolution network)에 대해서 배울 것이다.

History of ConvNet
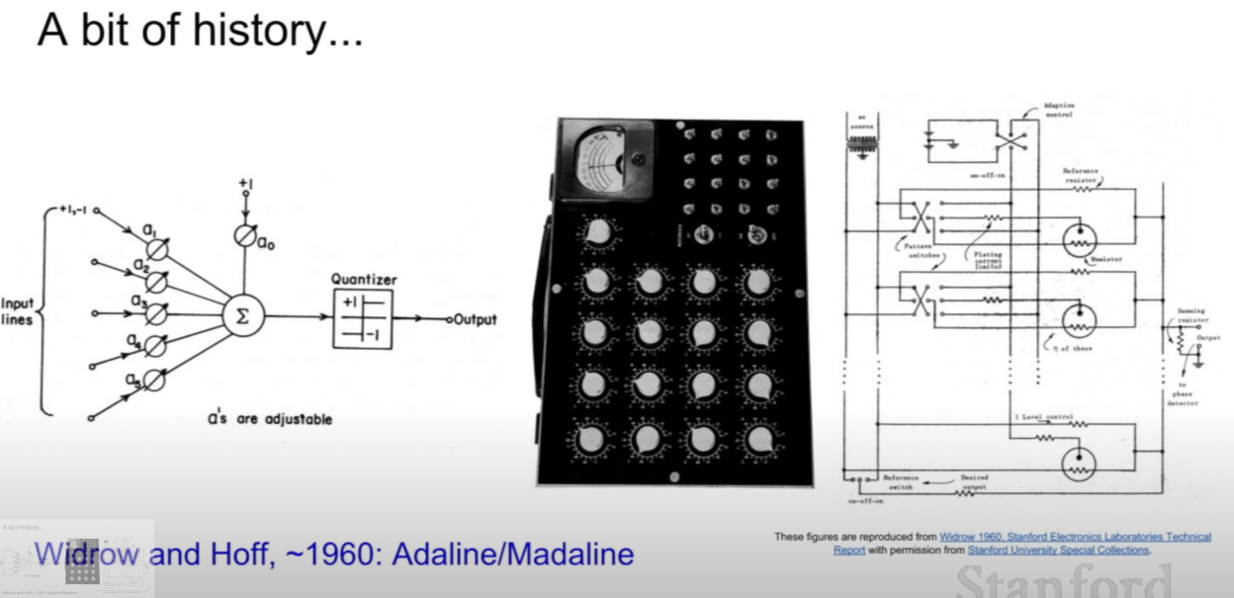
현재와 같은 뉴럴 네트워크의 구조를 가지는데 역사적인 네트워크가 있다. 그것이 바로 위 사진에 나온 Mark I Perceptron이다. 이 퍼셉트론은 activation function이 0과 1의 아웃풋만 가지며, 현재와 비슷한 update rule을 가진 모습을 확인할 수 있다. 다만 현재와 같은 그라디언트를 이용해서 업데이트 하는 방식은 아니다. 퍼셉트론 보다 조금 더 발전한 방식이 adaline, madaline이라닌 네트워크이다.
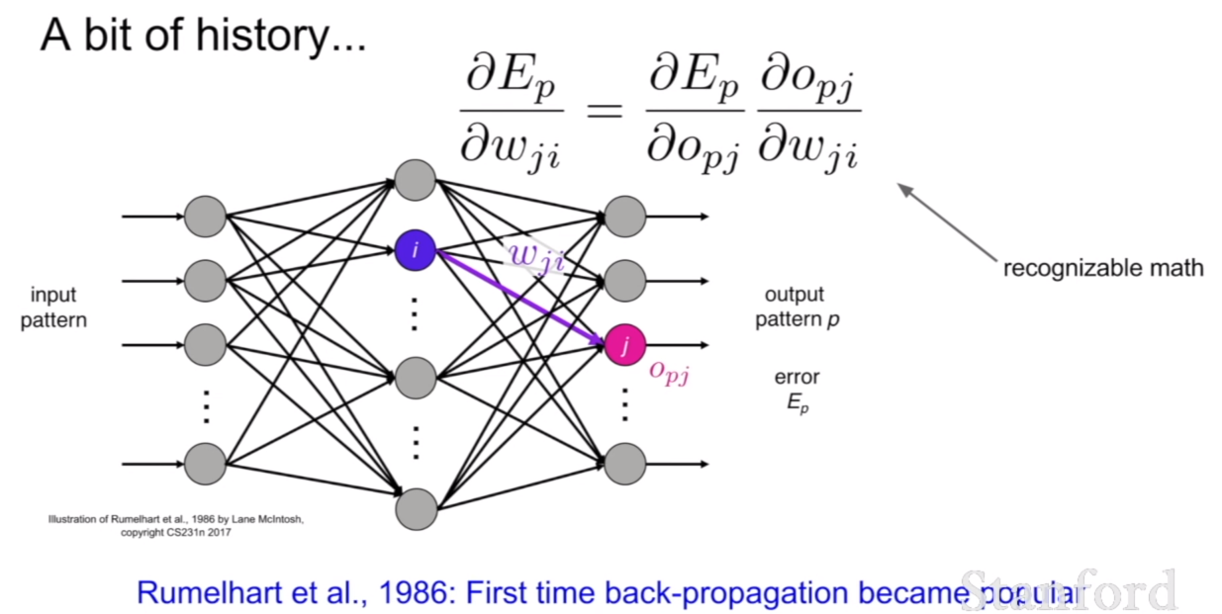
그리고 첫 번째로 Rumelhart가 1986년에 back-propagation을 유행시켰다고 한다.
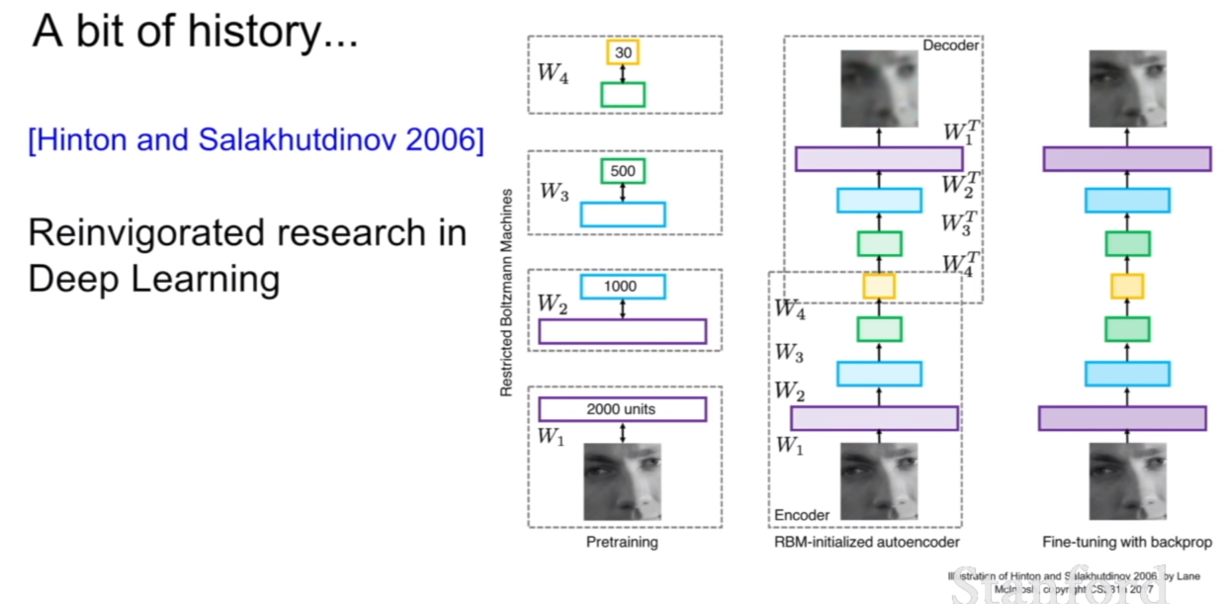
2006년에 Hinton 과 Salakhutdinov가 다시금 deep learning에 대한 연구를 활발하게 만들었다고 한다. 위 그림의 구조를 보면 지금과 같은 딥러닝의 구조를 비슷하게 띄고 있는것 같다.
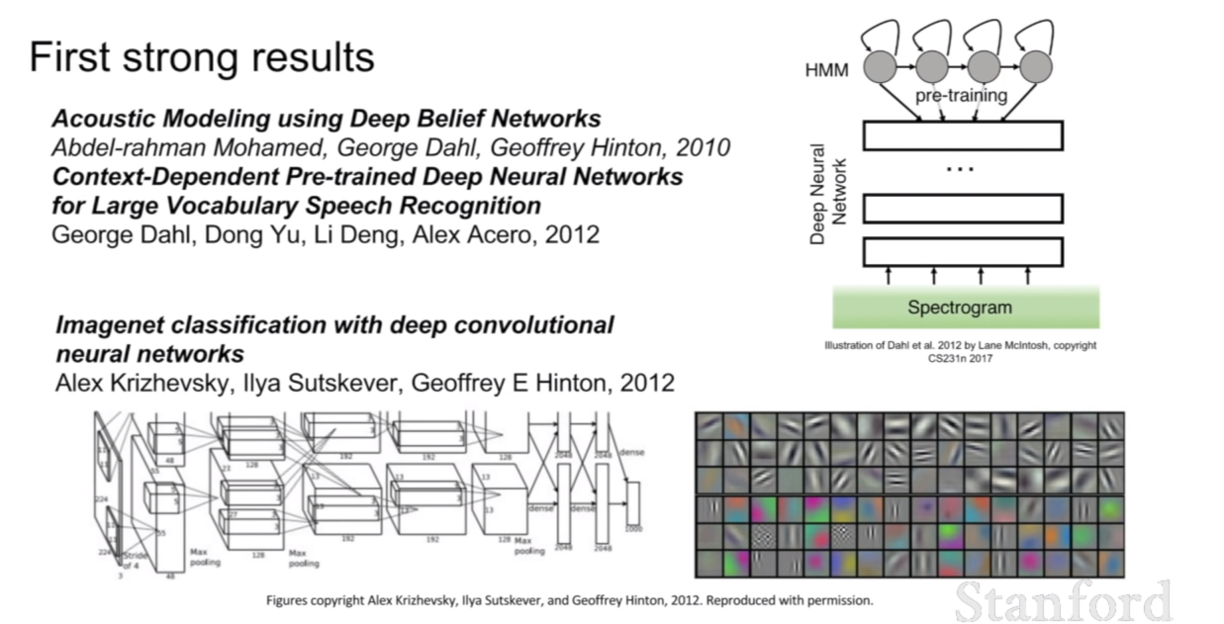
첫 번째로 딥러닝이 강력한 성능을 보이며 주목받기 시작한 연구는 2012년에 딥러닝을 이용한 speech recognition과 우리가 익히 알고있는 이미지 인식에 관한 논문인 AlexNet이다.

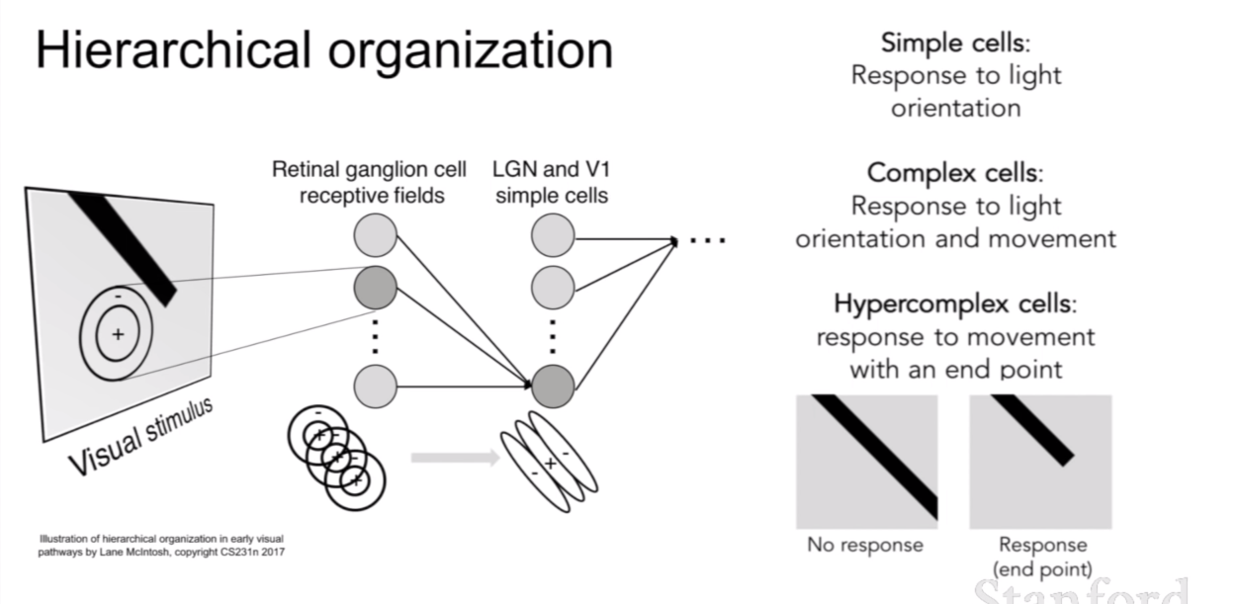
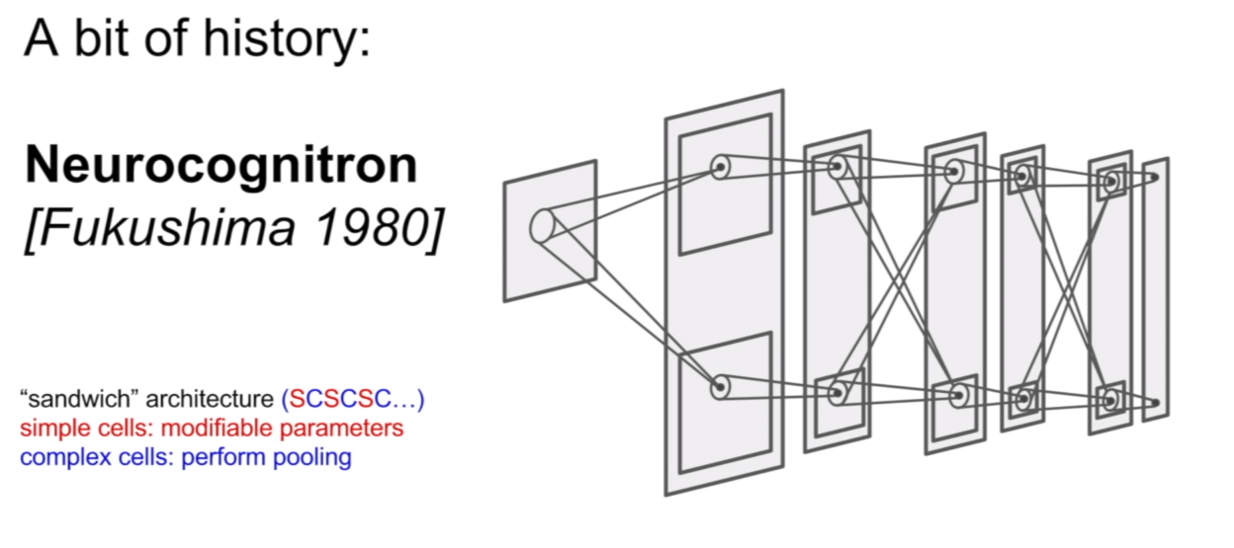
사실 이러한 구조는 우리 피질(cortex)에서 아이디어를 얻었다고 한다. 인간 대뇌 피질은 바깥 쪽에서는 간단한 구조를 인식하고 그와 연결된 뉴런을 타고타고 깊이 들어갈수록 이 정보들을 조합해 복잡한 정보를 인식한다고 한다. 이러한 구조를 계층적(hierarchical)하다고 표현하고 있다. 이에 착안해서 나온 논문이 Neurocognitron이다.
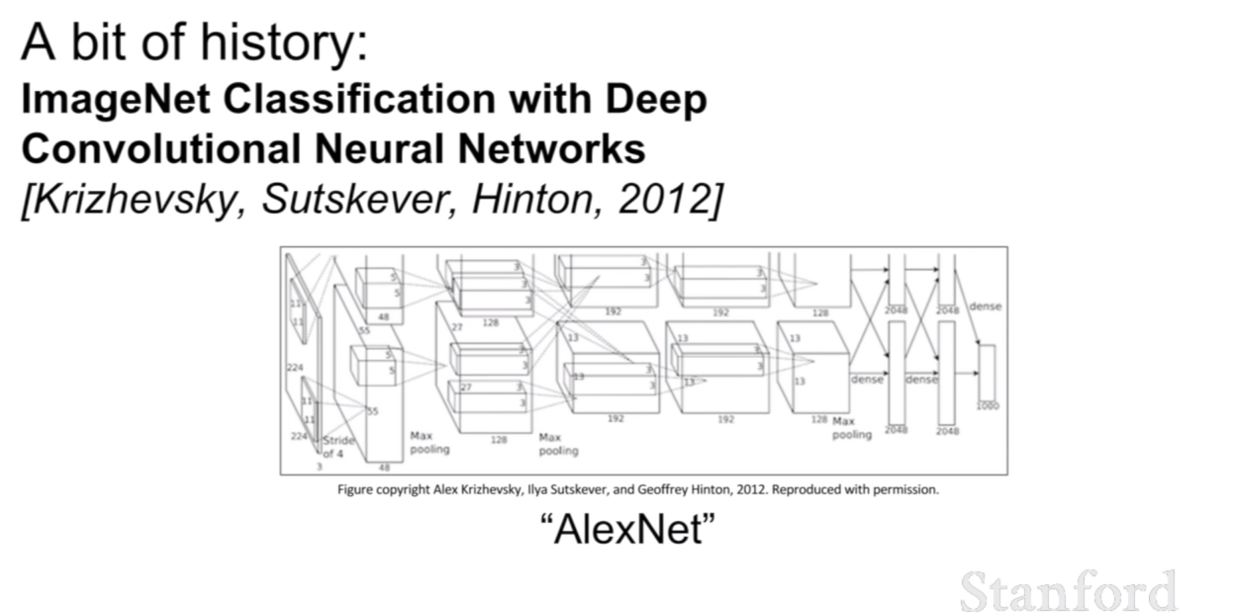
그리고 이를 더 발전 시킨 논문이 AlexNet이다.


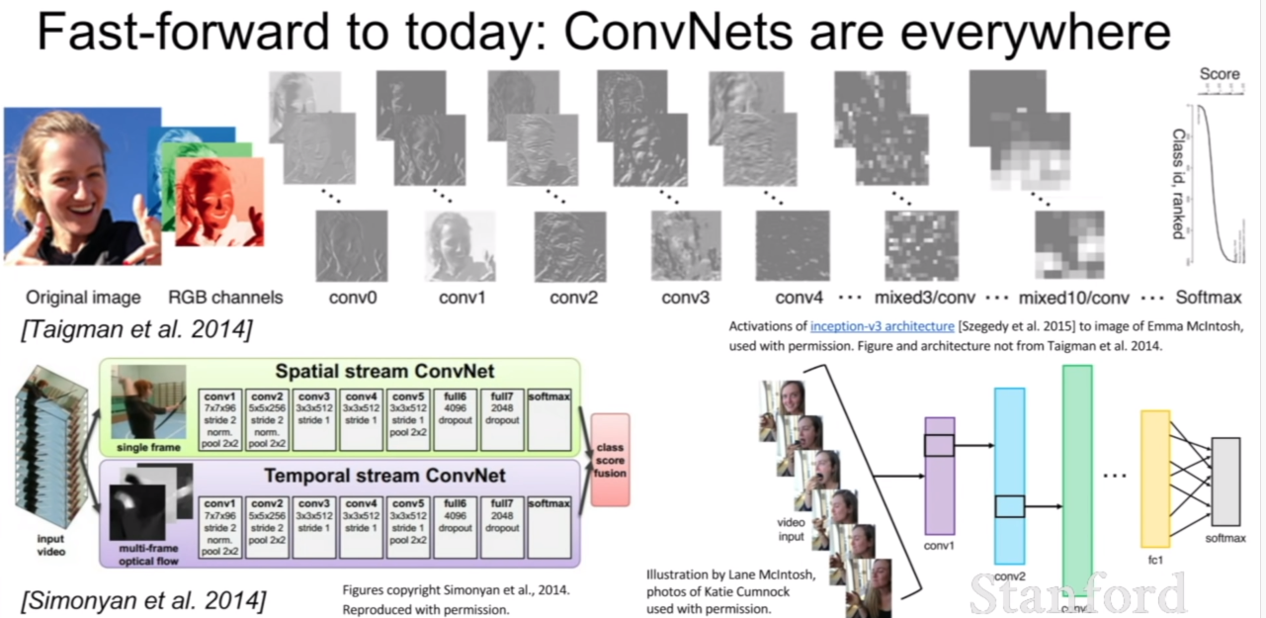



컨볼루션 네트워크가 활용되는 응용분야는 위와 같다. 이것 말고도 더욱 많은 분야들이 있을 것이다.
Convolutional Network
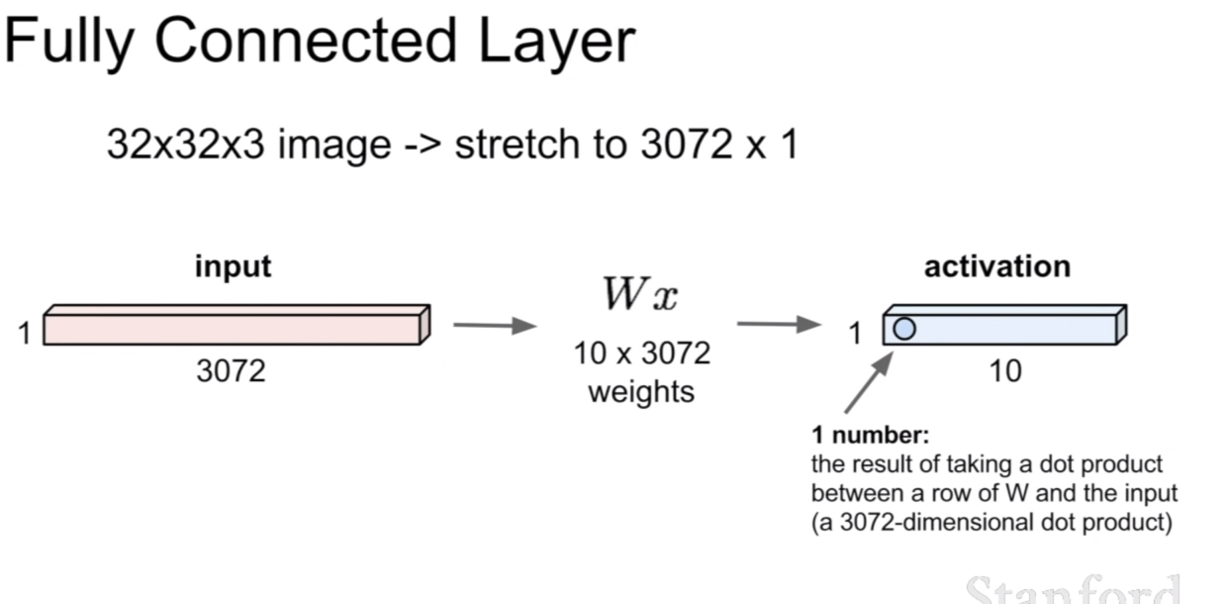
위 그림은 우리가 전에 봤었던 Fully connected layer(FCL)이다. FCL은 전체를 1차원의 벡터로 펼쳐 가중치와 곱을하게 된다. 이렇게 되면 이미지 혹은 특징맵이 1차원으로 펼쳐져 가중치 행렬과 곱해지기 때문에, 전체 원소(혹은 픽셀)의 관계를 파악하는 역할을 한다고 볼 수 있다.
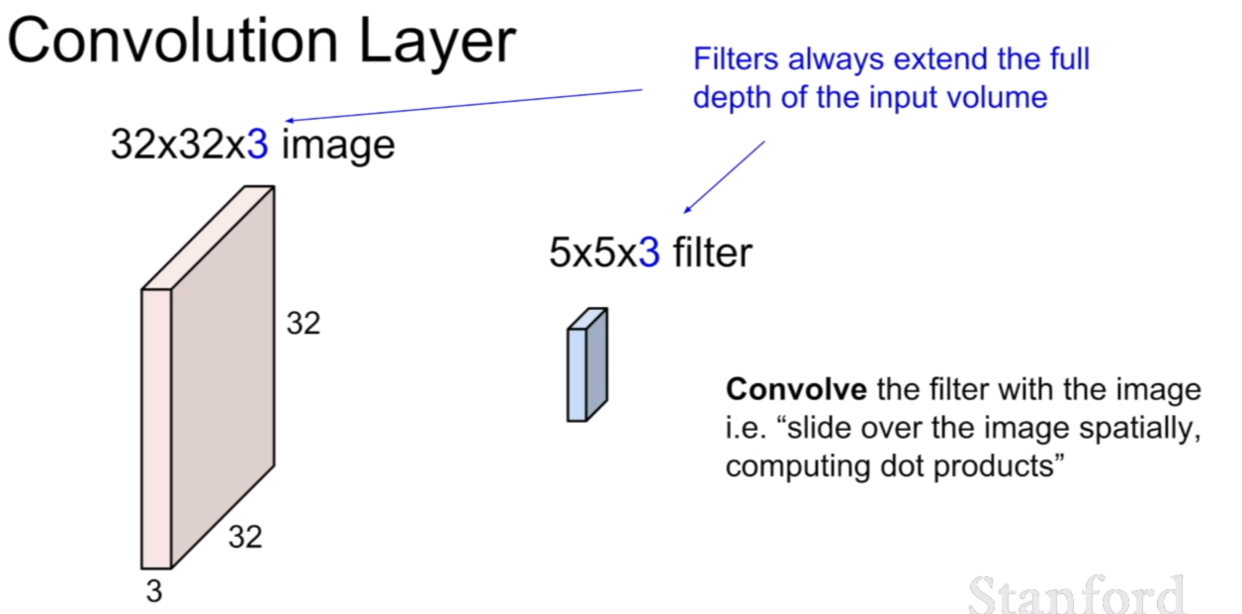
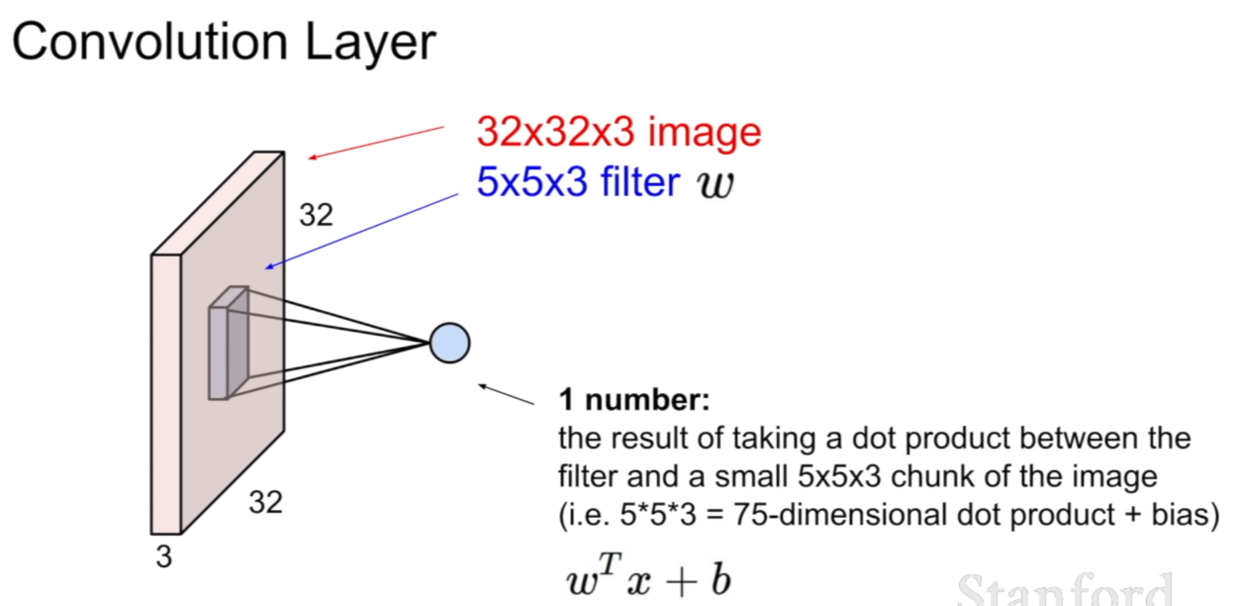
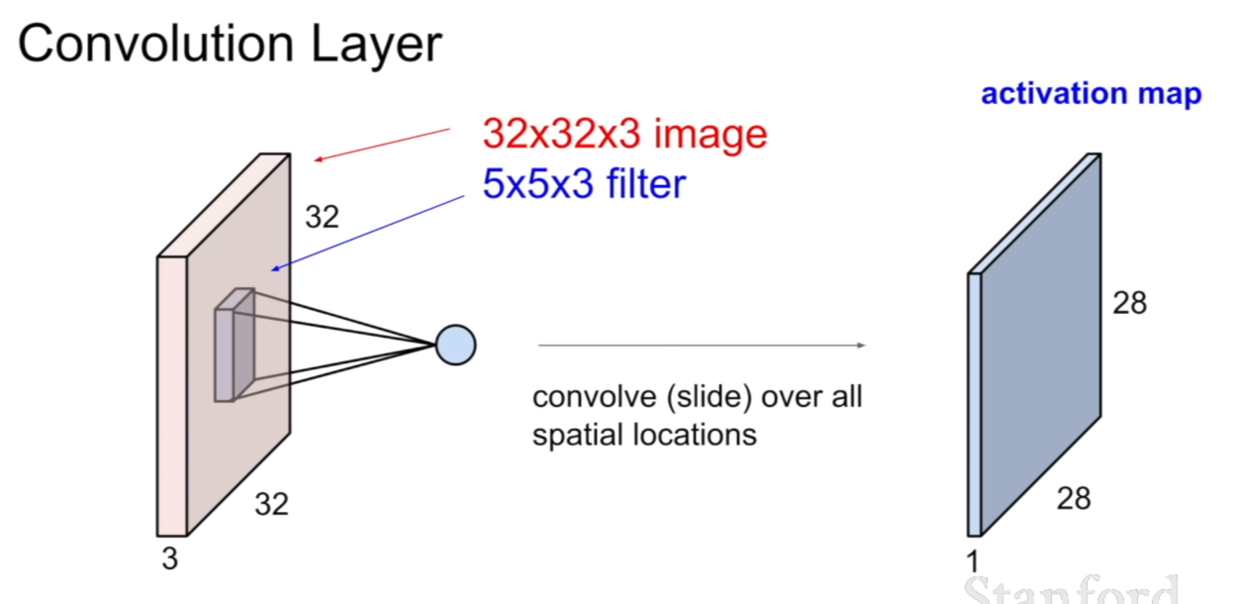
컨볼루션 레이어는 위에서 보았던 FCL과 다른점이 있다. 첫번 째는 지역적(local)적인 특성을 띤다는 것이다. 그리고 원소곱(element-wise multiplication)이다. 이것을 슬라이드에서는 dot product(내적)이라고 표현을 하고 있다. 같은 말이다. 내적의 공식을 보면 같은 뜻임을 알 수 있다. FCL은 가중치 W행렬과 행렬곱을 이룬 반면, 컨볼루션은 필터와 원소곱을 한 후, 그 원소곱이 끝난 원소의 합이 다시 한 픽셀의 값이 된다.
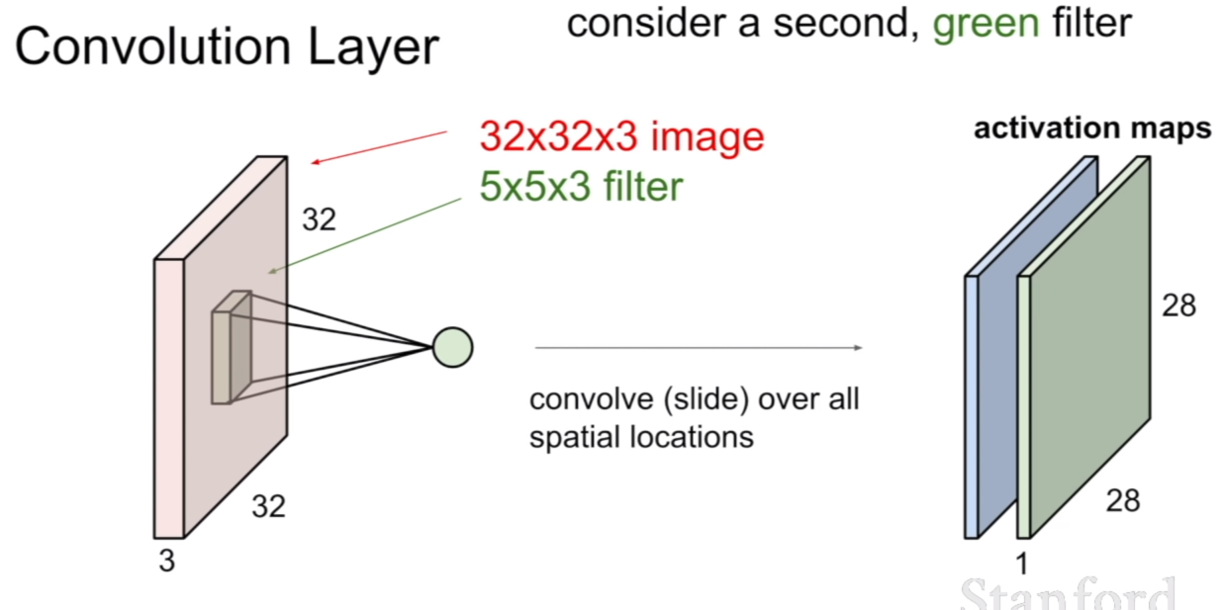
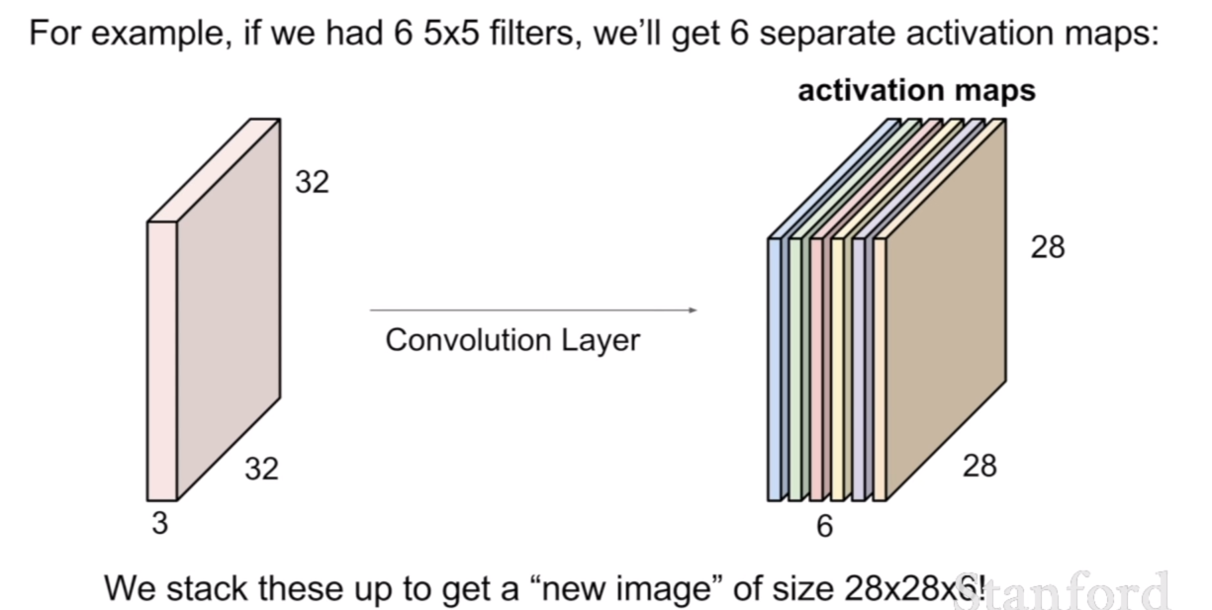
만약 필터가 두 개라면 필터링을 한 후의 activation map은 filter의 개수만큼 존재하게 된다. 우리가 5x5x3 필터를 6개 가지고 있다면 위 그림처럼 6개의 activation map을 얻을 수 있다.
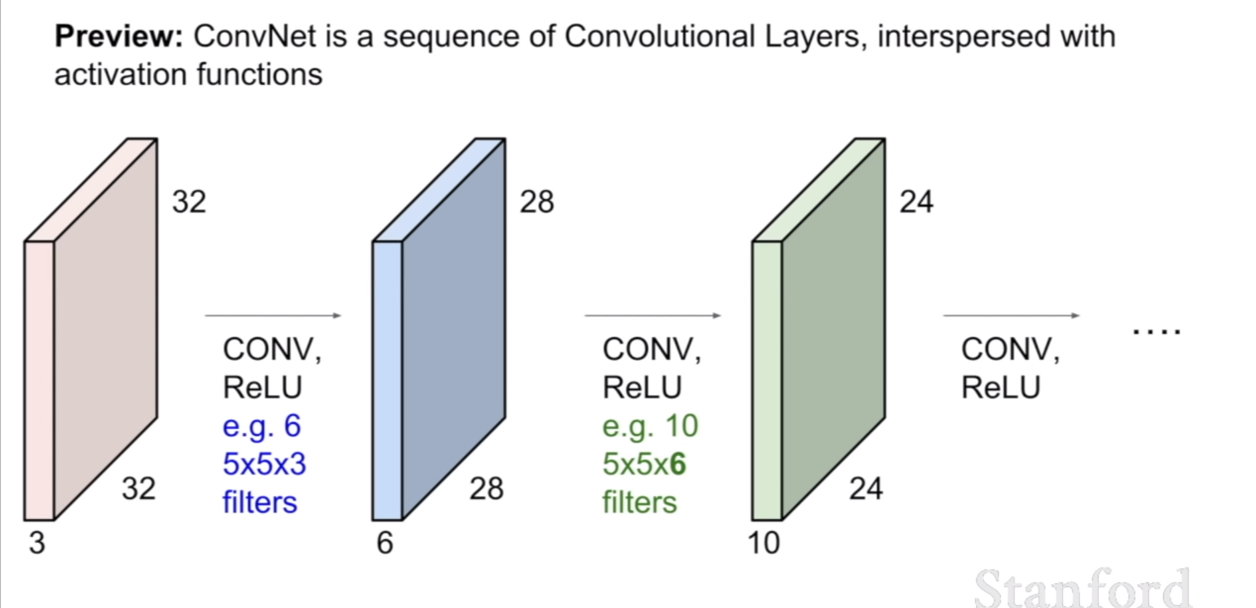
컨볼루션 네트워크는 위 슬라이드와 같이 컨볼루션 레이어 사이에 ReLU와 같은 activation function을 사이에 넣는다고 한다.
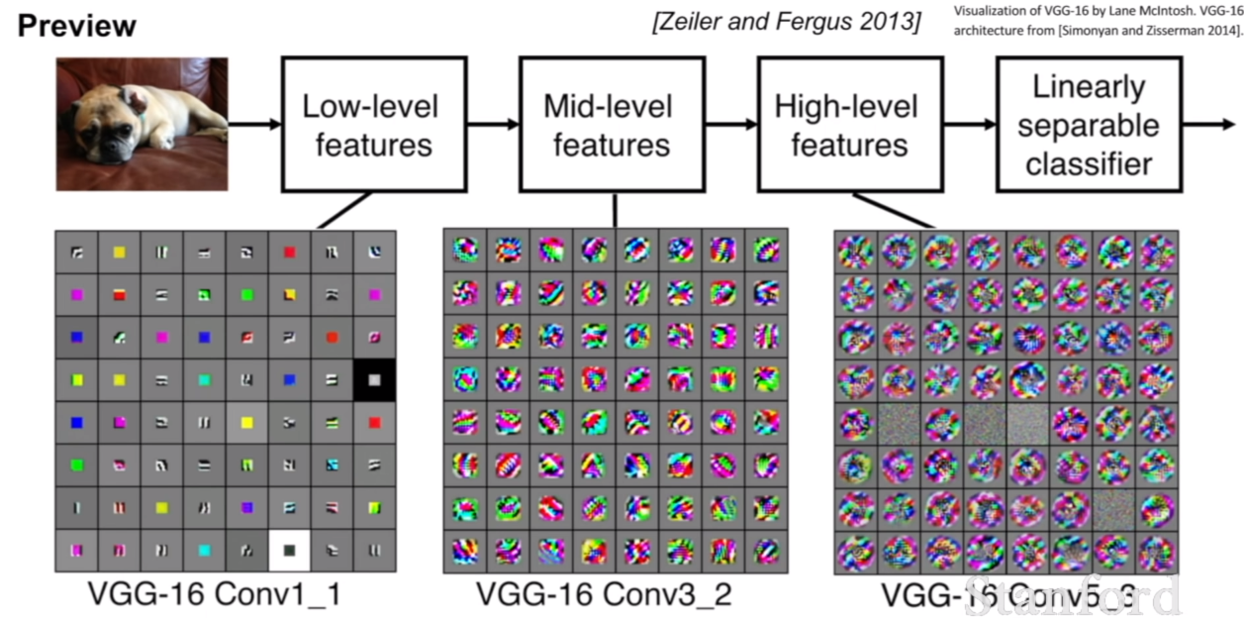
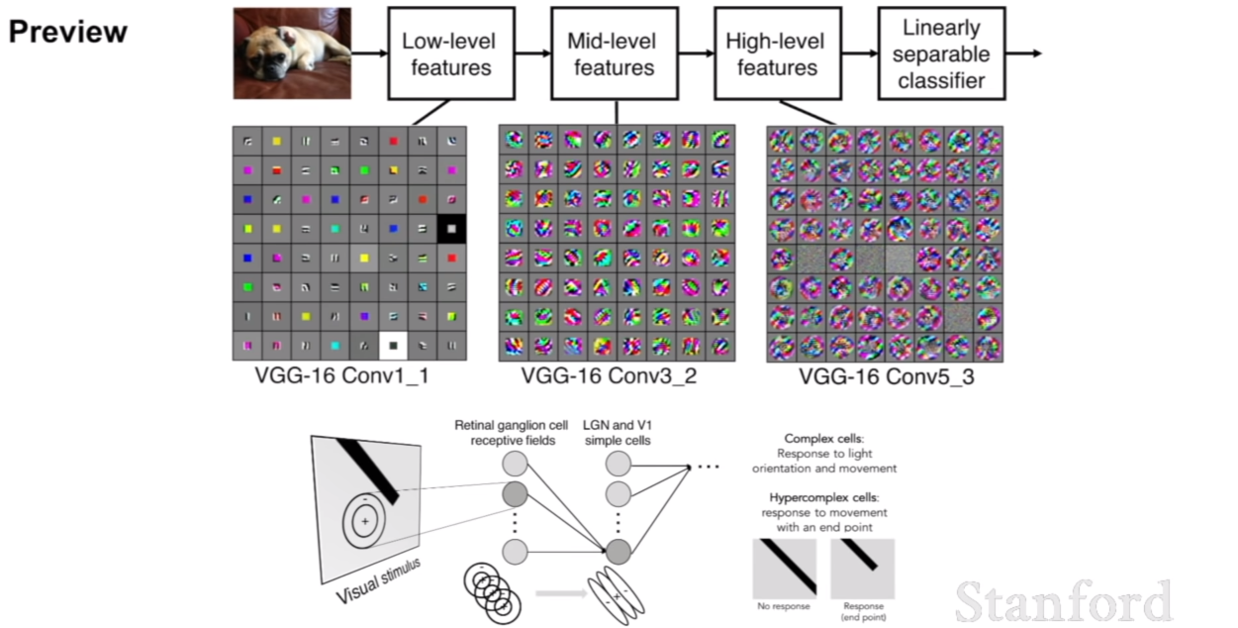
우리는 위에서 컨볼루션 네트워크가 대뇌 피질에서 동작하는 방식같이 작동한다고 설명을 하였다. 우리가 의도적으로 앞에 층에는 low level feature, 뒷 층에는 high level feature을 학습하라고 설계한것은 아니지만, 실제로 그와 비슷하게 작동하고 있는 모습을 볼 수 있다.


위 두 슬라이드를 참고하면, 컨볼루션 네트워크의 필터는 이미지의 특징을 추출하는 역할을 하는 것을 볼 수 있다. 무작정 아무 특징이나 추출하는것이 아니고, 이미지의 엣지, 블롭등 해당 이미지가 지니는 특징을 잘 추출하도록 학습이 진행되는 것이다. ReLU activation function을 보면 컨볼루션을 수행한 후의 특징맵이 ReLU함수를 거치면 보다 특징적인 부분만 선택되어 남아있는 것을 확인할 수 있다.
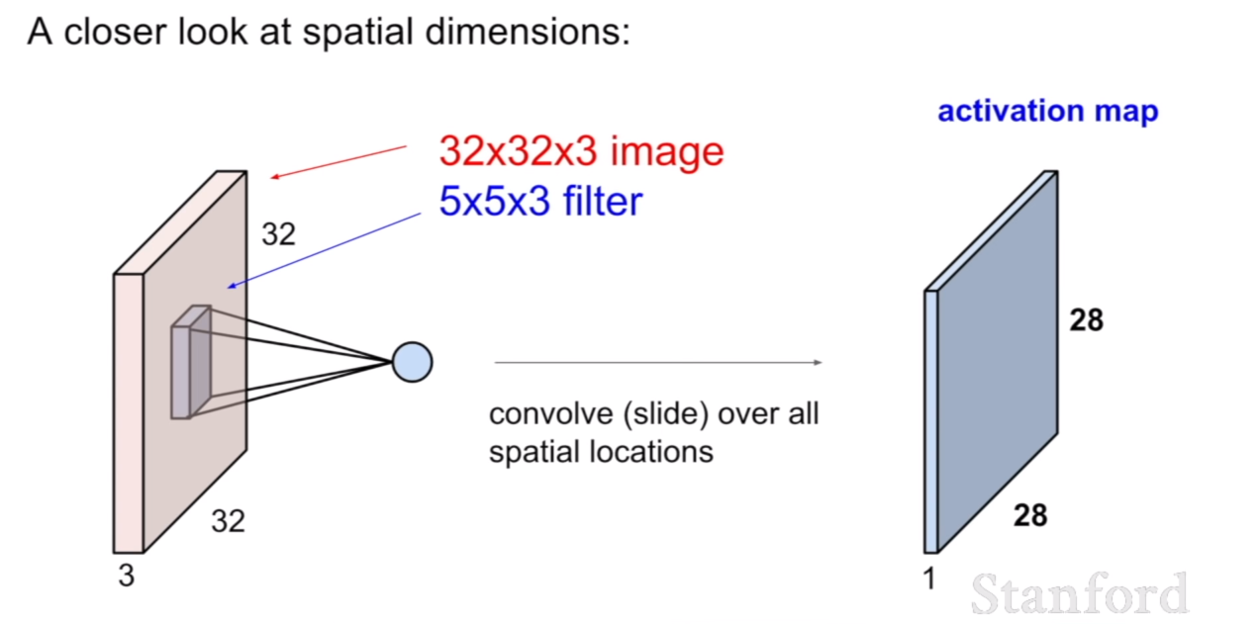
그렇다면 이제 위 슬라이드의 컨볼루션 연산을 표본으로 어떻게 컨볼루션이 이루어지는 것인지 조금 더 자세하게 살펴보자.
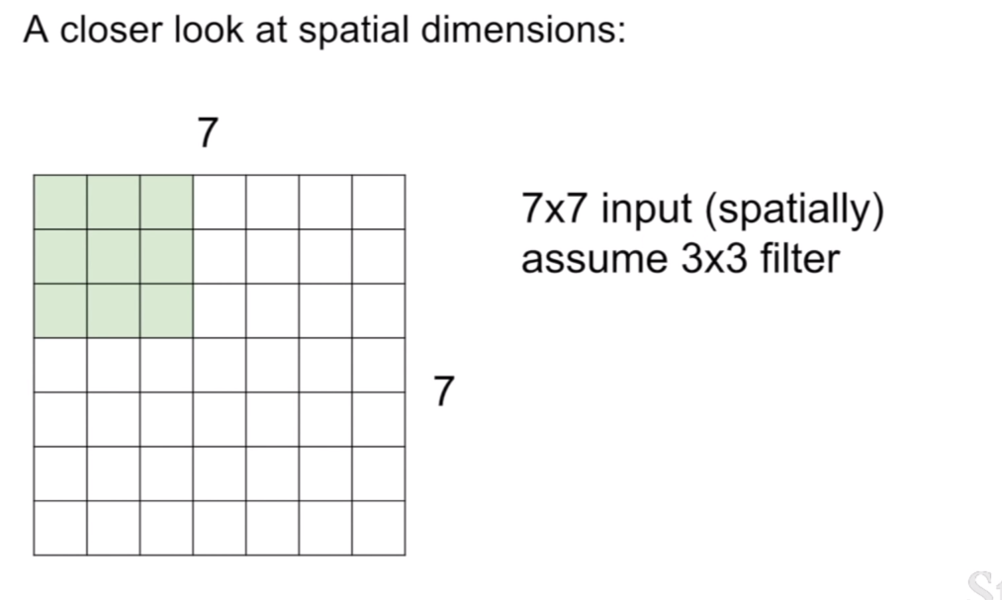
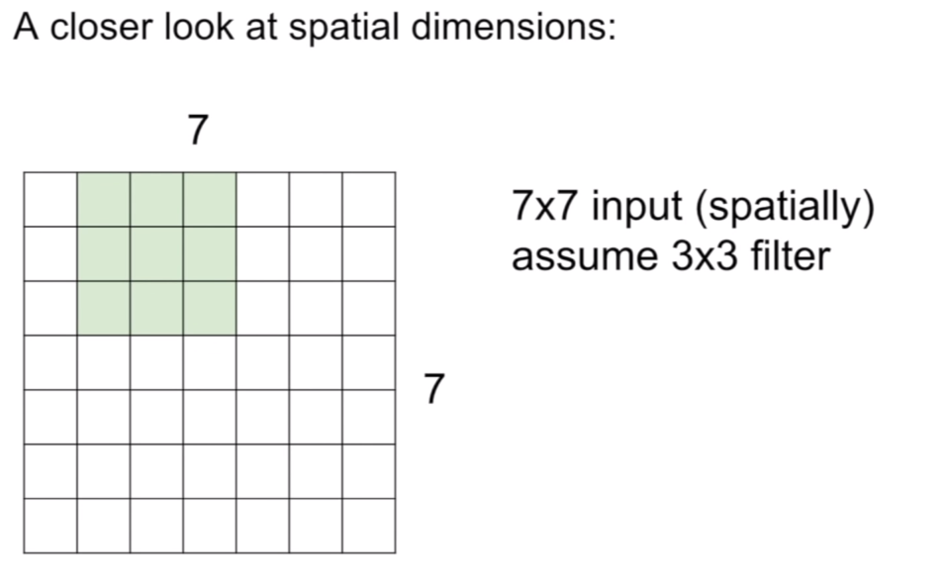
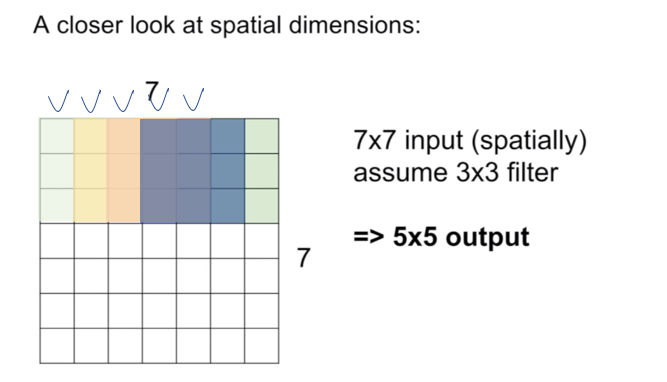
먼저 이미지(혹은 피쳐맵(feature map))의 크기는 7x7 이고 이 때, 필터의 크기는 3x3이라 하자. 그리고 padding=0, stride=1이다. 이때 컨볼루션은 필터가 이미지의 좌 상단에 맞추어지는 지점부터 시작한다. (이 때, 필터의 중심점은 3x3필터의 중심부분이라고 생각해두고 필터가 움직이는 모습을 생각해보자.) stride=1이기 때문에, 현재 위치의 컨볼루션 연산을 수행했다면, 오른쪽으로 한 칸 움직여 컨볼루션을 수행한다. 이렇게 컨볼루션을 수행하면 오른쪽으로 총 4번을 이동할 수 있을 것이다. 그러면 처음 1번의 컨볼루션이 있었으므로, 5번의 컨볼루션이 수행된것이다. 이렇게 오른쪽 끝에 다다랐다면, 다시 좌상단 지점으로 돌아와 중심이 한 픽셀 내려간지점을 기준으로 방금 한 컨볼루션을 반복한다. 이렇게 컨볼루션을 하면 총 5x5의 activation map이 나오게 된다.

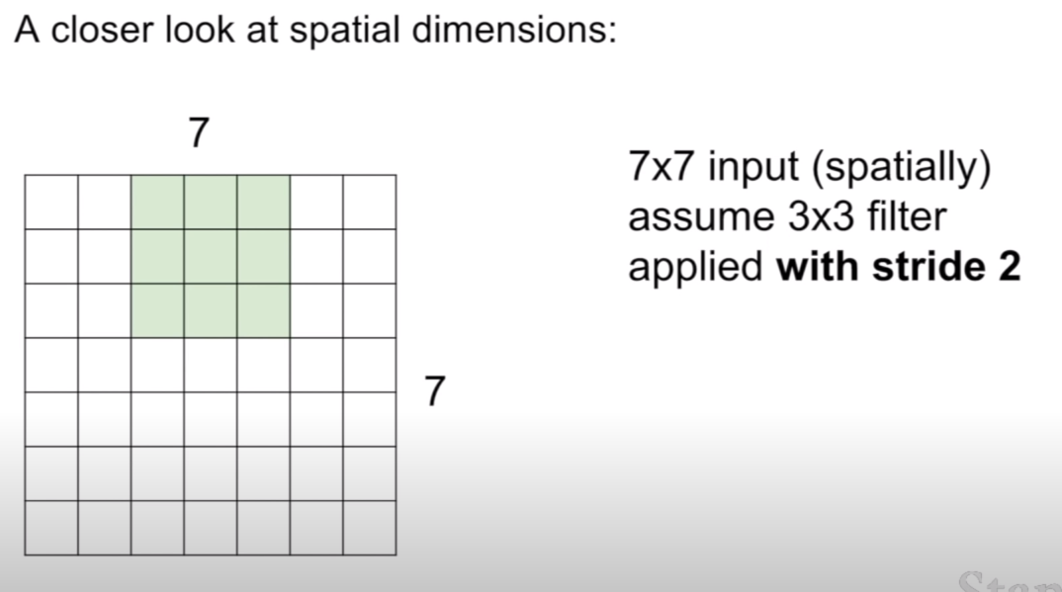
이 때, stride=1 에서 stride=2로 변했다면 어떻게 컨볼루션이 진행될까? 그 답은 바로 필터가 2칸씩 움직이면서 컨볼루션이 진행된다는 점이다.
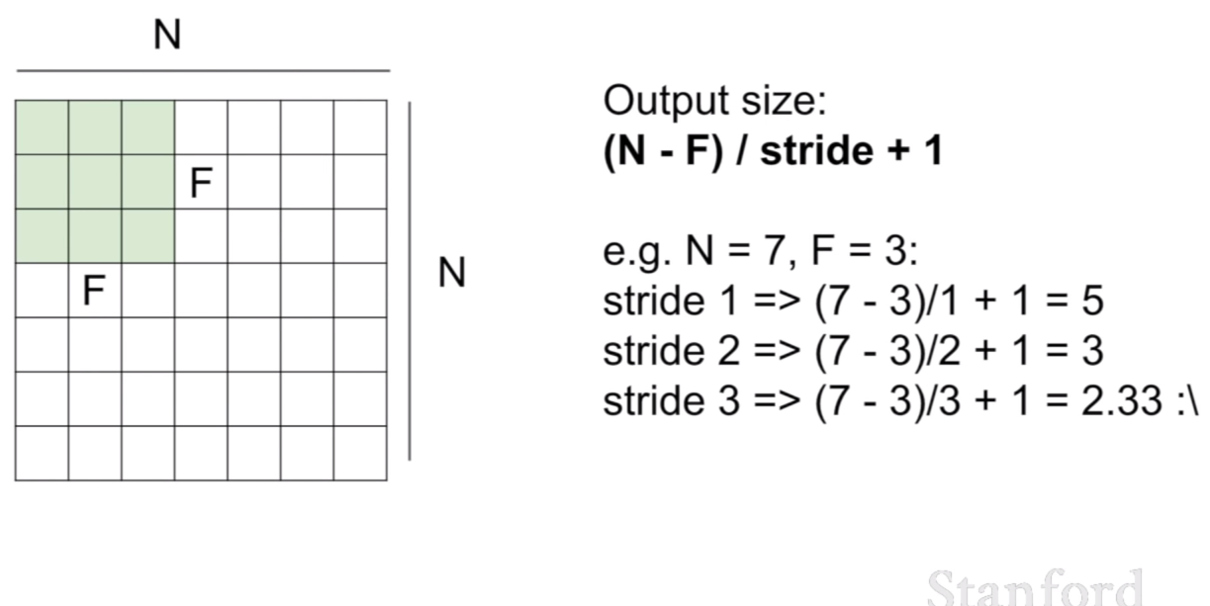
그렇다면, 이미지의 크기와 필터의 크기가 주어졌을 때, 컨볼루션 결과 예상되는 activation map의 크기를 미리 알 수 있는 방법이 없을까? 라고 생각한다면 바로 위 슬라이드에 이에 관한 공식이 적혀져있다.
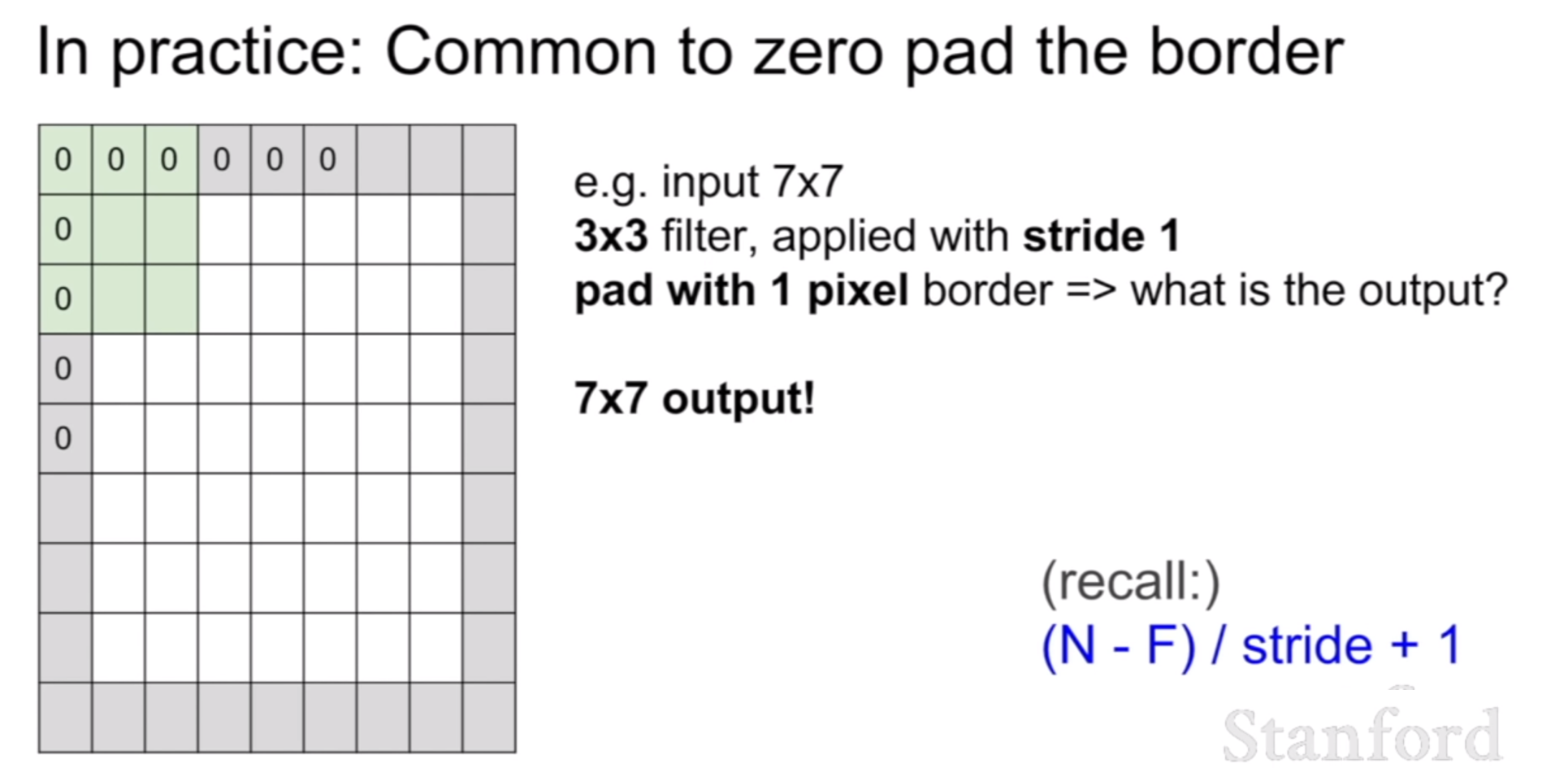

그런데, 아까 컨볼루션 공식에서 봤듯이, stride=3인경우에 컨볼루션후 활성맵의 크기가 2.33 이라는 소수점으로 나온다. 즉, 이것은 해당 stirde의 크기로는 컨볼루션이 불가능하다는 뜻이다. 그렇다면 나는 stride=3으로 컨볼루션을 하고 싶은데, 이렇게 불가능한 상황이발생한다면 어떻게 해야할까? 그것은 바로 위 슬라이드에 나와있는 것 처럼, 0-padding을 하는 것이다. padding을 함으로써, 컨볼루션 후 우리가 원하는 크기의 활성화맵을 얻을 수 있다.
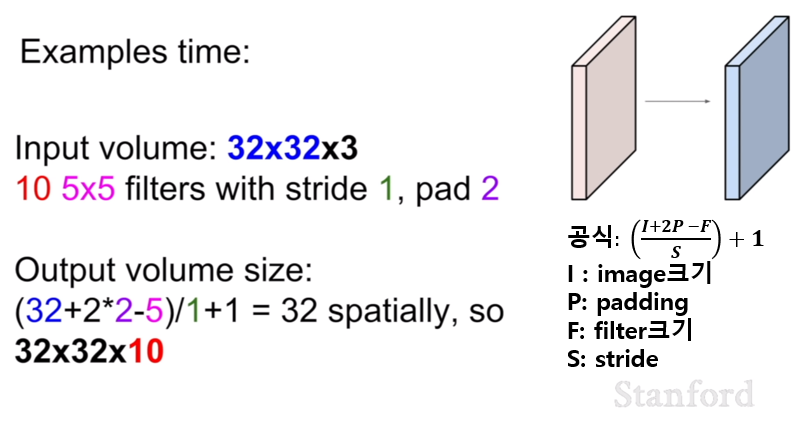
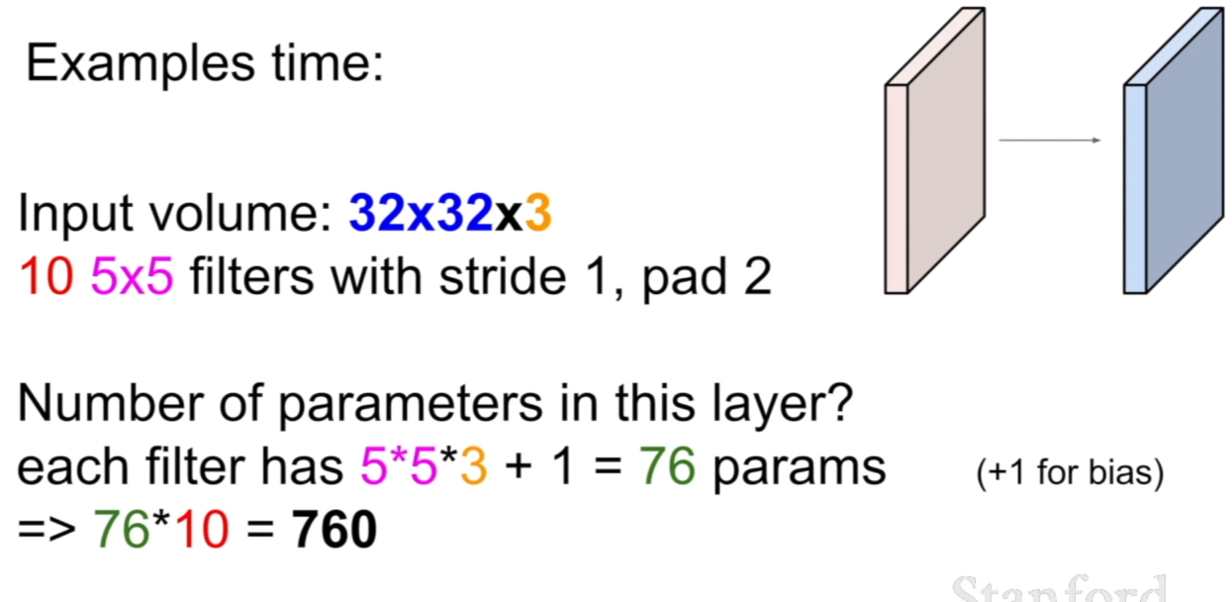

위 세 장의 슬라이드를 통해서 컨볼루션 시 크기가 어떻게 변화하는지 알 수 있다. 그렇다면 컨보룰션시 사용되는 파라미터의 개수는 어떻게 구할 수 있을 까? 그것은 바로 필터의 개수 x (필터의 크기 + bias=1) 이다.
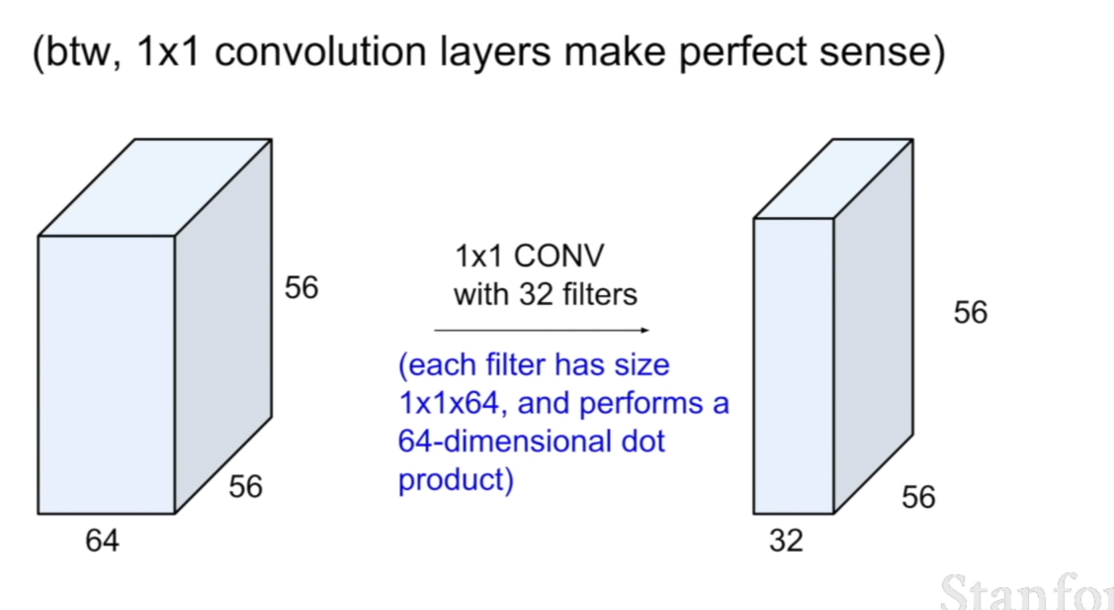
추가적으로, 컨볼루션은 1x1크기의 필터로 수행될 수 있다. 이경우에는 1x1x64의 필터가 32개가 있고, 그 후 컨볼루션된 결과를 보여준다. 이것은 지역적인 특성은 고려하지않고 비선형성만 증가시키는 결과를 가져온다고 한다.

다시 한번 뇌와 뉴런의 입장에서 컨볼루션 레이어를 살펴보면 이것은 마치 일정 지역의 뉴런들이 지역적으로 연결되어 더 깊숙한 지점의 한개의 뉴런으로 활성화되는 것과 같다고 할 수 있다.
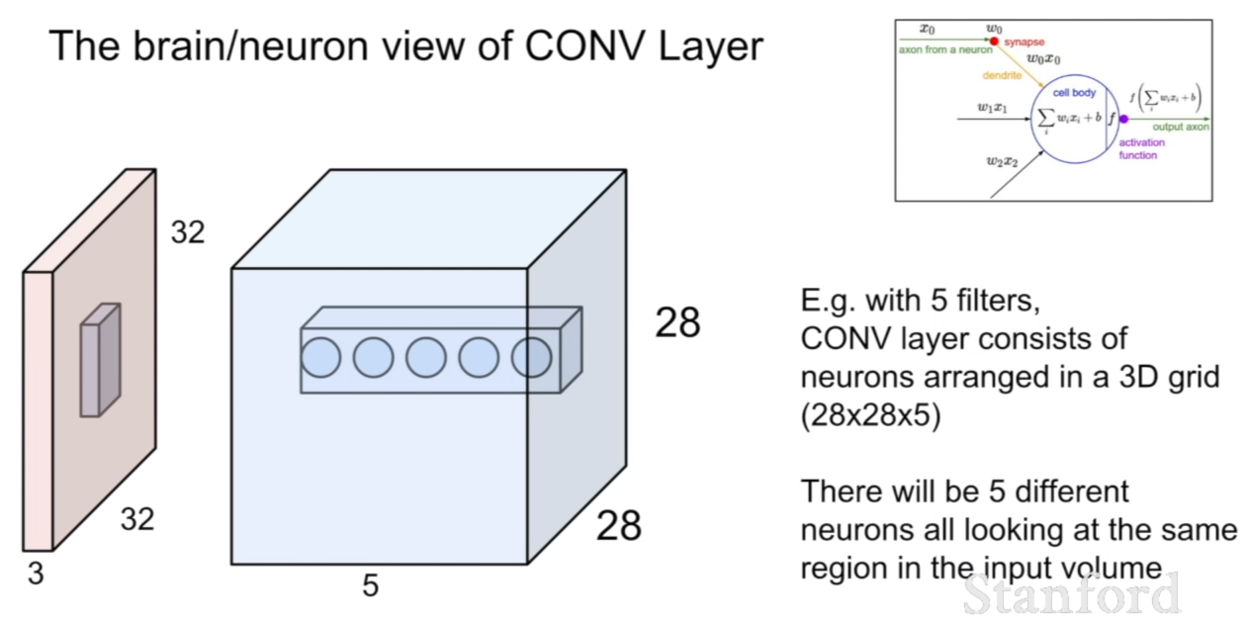
뇌의 뉴런에는 한 개의 뉴런이 한 포인트에 대한 특징을 전달하는데 , 이것은 같은 지점에 대해서 다르게 해석한 뉴런이 존재할 수도 있다는 것을 의미한다. 그렇기 때문에, 컨볼루션 레이어에서 특징맵에 depth가 있다는 것은 같은 지점을 보는 뉴런이 5개 있는데, 그 특징을 각각 다르게 해석한 것이라고 볼 수 있다.
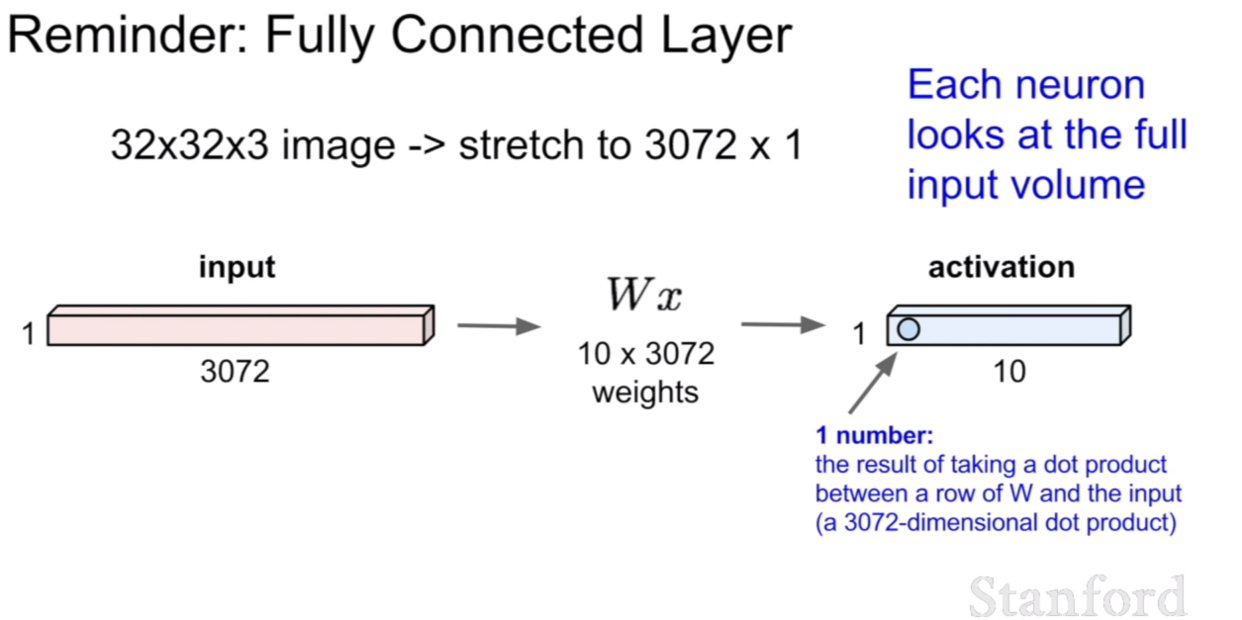
마지막으로 fully connected layer지점은 전체를 보고 한 결정을 내리는 지점이라고도 볼 수 있을것 같다.
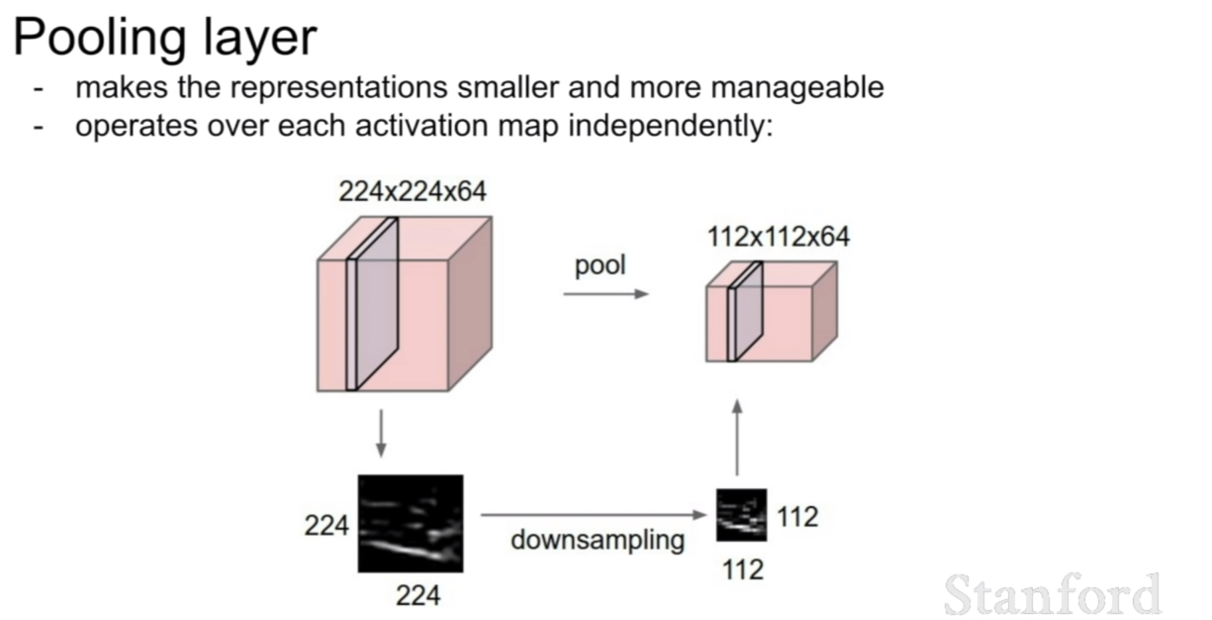
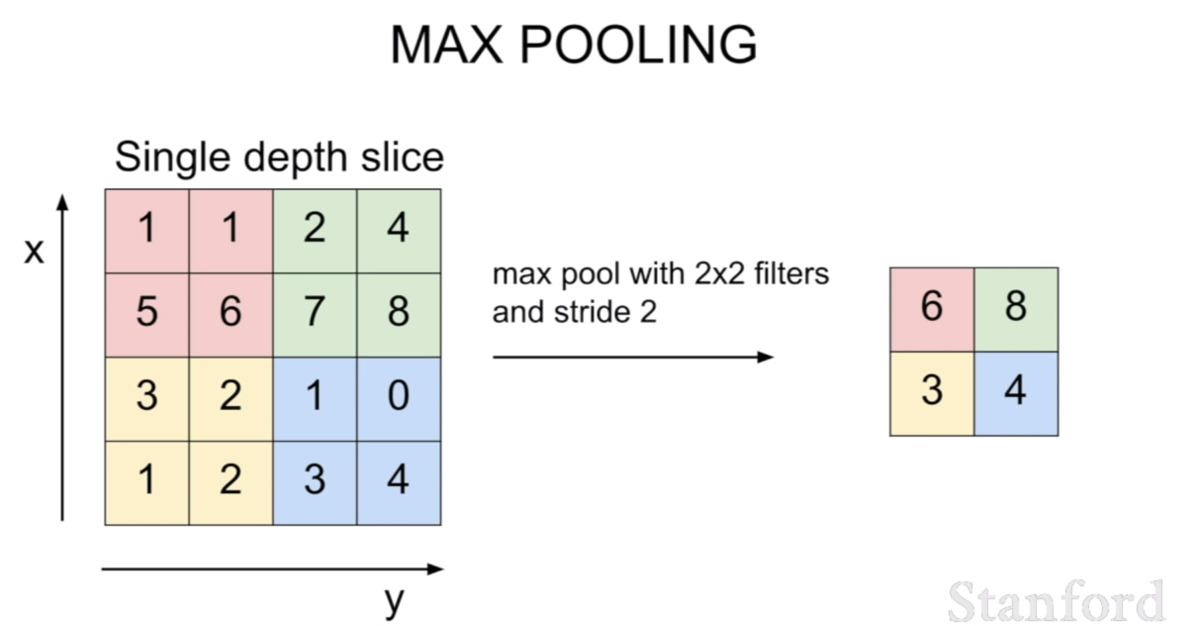
우리는 또한 지역적으로 특징을 살피는 컨볼루션 네트워크의 특징에 고안하여, 풀링 레이어(pooling layer)라는 것을 추가하였다. 풀링 레이어는 해당 영역안에서 평균값을 고르거나, max, min등 연산에 해당하는 값을 취하여 영상에서 특정값을 취하여 크기를 downsampling하는 과정이다. 이를 통하여 해당 특징을 더 작은 스케일에 대해서도 학습할 수 있도록 할 수 있다고 생각한다.