

CS231n-Lecture02(KNN,dataset,linear classifier)
18 Aug 2020 | CS231n목차
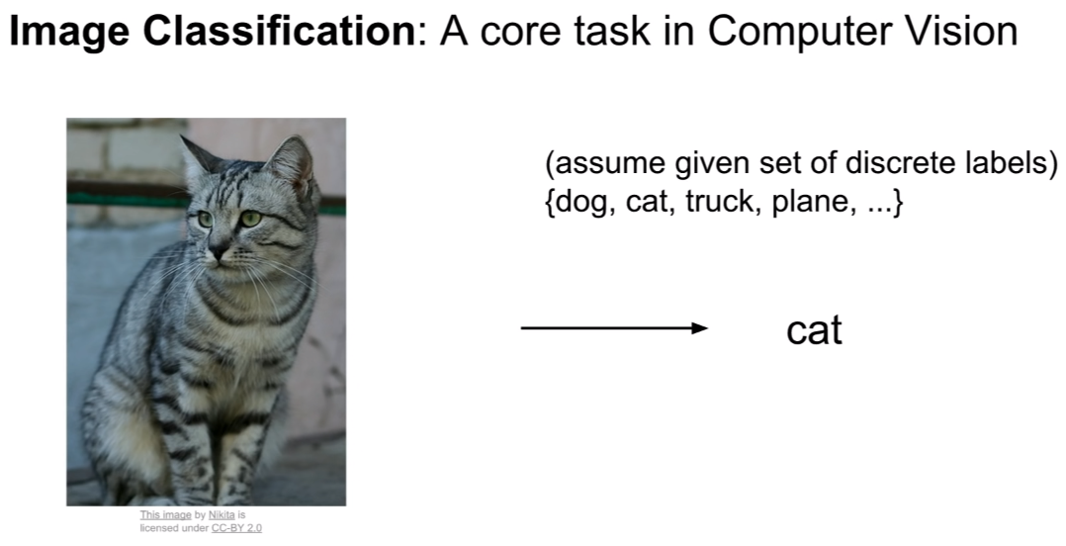
컴퓨터 비전의 핵심 테스크중 하나인 이미지 분류를 생각해보자.
개, 고양이, 트력, 비행기와 같은 클래스가 존재할때, 우리는 왼쪽의 고양이 이미지를 cat으로 분류할 수 있어야 한다.
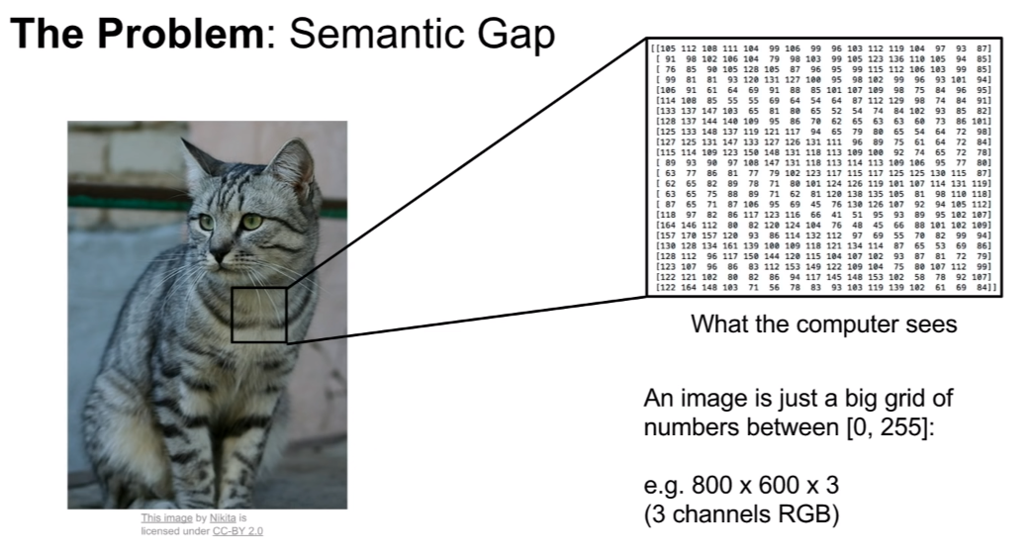
우리가 보는 방식과, 컴퓨터가 이미지를 보는 방식에는 차이가 존재한다.
컴퓨터는 이미지를 단순한 숫자로 보게 된다.
이번 예시의 경우, 색을 RGB 3채널로 보며, 한 위치(픽셀, (x,y,z))의 값을 [0,255]로 표현한다.
이러한 컴퓨터의 특성 때문에, 이미지 분류를 더 어렵게하는 원인들이 존재하게 된다.
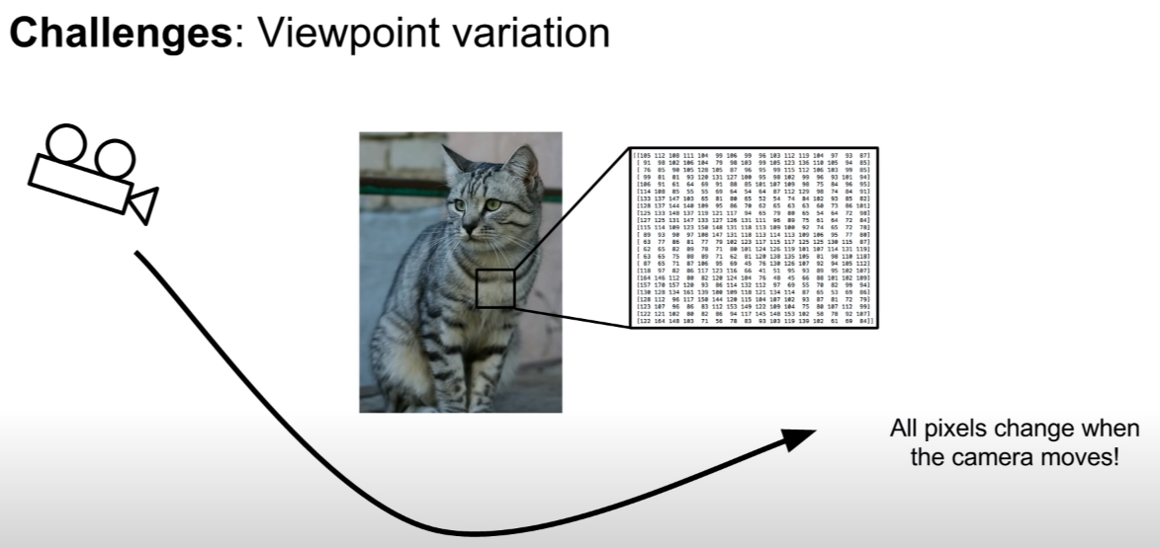
카메라가 고양이를 촬영하는 각도마다, 빛이 들어오는 양, 그리고 각도에 따라 카메라에 담기는 고양이 모습에 변형이 일어나게 된다. 그래서 고양이라는 분류 기준을 정하기 더 어렵게 만든다.

조명이 문제가될 수 있다. 조명이 너무 어둡거나 너무 밝은 경우, 물체의 특성이 가려지게 되고, 모두 까맣게 보이거나 하얗게 보일 수 있게 된다. 이 때 우리는 물체의 특성을 파악하기 어려워 진다.
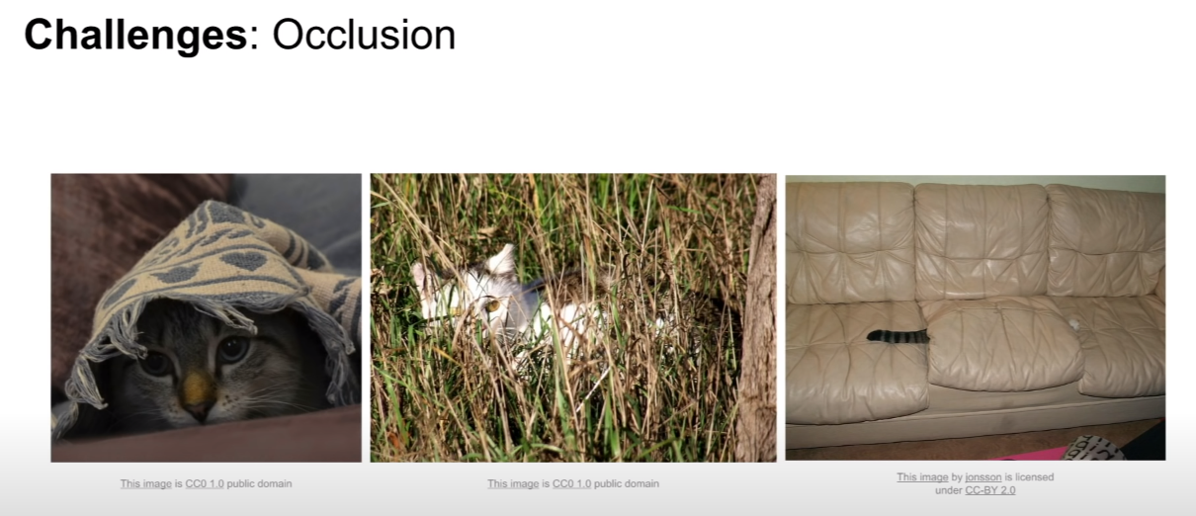
우리가 분류하고자 하는 물체가 다른 물체에 의해 가려져있을 수 있다. 위 그림을 보면, 고양이가 모두 다른 물체에 가려져 있어서, 고양이 특유의 특징이 잘 드러나지 않는다. 특히 세번째 사진은 집에서 키우는 동물은 개, 고양이 정도로 함축되어 있다는 사전 정보가 없이는 저 꼬리가 고양이 꼬리인지 알기 쉽지 않다.

마지막으로, 클래스 내 분산이 클수록 어려워 진다. 똑같은 고양이더라도 종류에 따라서, 유전적 요인에 따라서 무늬와 색, 신체적 모양이 모두 조금씩 달라질 수 밖에 없다. 이 모든 것을 고려하여 고양이는 어느정도 특징을 가져야 고양이인지 기준을 정할 수 없는 노릇이다.

개별적인 물체의 특징자체도 이미 복잡한데. 위와 같이 방해를 하는 다양한 특징이 있기 때문에, 하드 코딩(일일히, if-else문을 통하여 기준을 정하는것)을 통하여 이를 완벽하게 수행할 수 있는 방법은 존재하지 않는다.

위와 같이 고양이의 이미지에서 엣지를 추출한 다음에, 코너의 방향과 같은 정보를 통하여 찾는 방법이 제시된적이 있었다.

하지만 역시, 높은 성능은 보이지 못했다. 딥러닝과 머신러닝에서 이용되는 방식인 데이터를 이용한 접근 방법이 있다. 이 방법은 데이터를 수집하고, 모든 각각의 이미지에 레이블(정답)을 설정한다. 그 다음, 알고리즘을 통하여 분류기를 훈련 시키고, 새로운 이미지를 통하여 평가한다.
KNN (K-Nearest Neighbor)
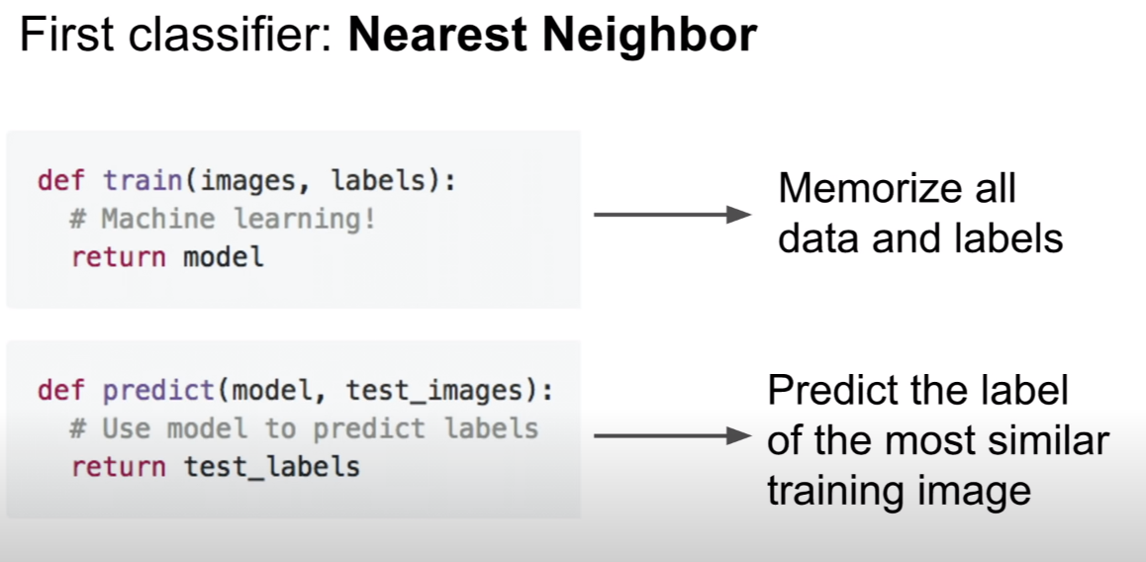
첫 번째 분류기는 Nearest Neighbor 방식이다.
훈련시 훈련 데이터와 레이블을 모두 기억하고,
예측시, 입력 이미지와 가장 빗스한 이미지를 찾아 레이블을 예측한다.

이 강의에서 예시로 쓰이는 데이터셋은 CIFAR-10이다.
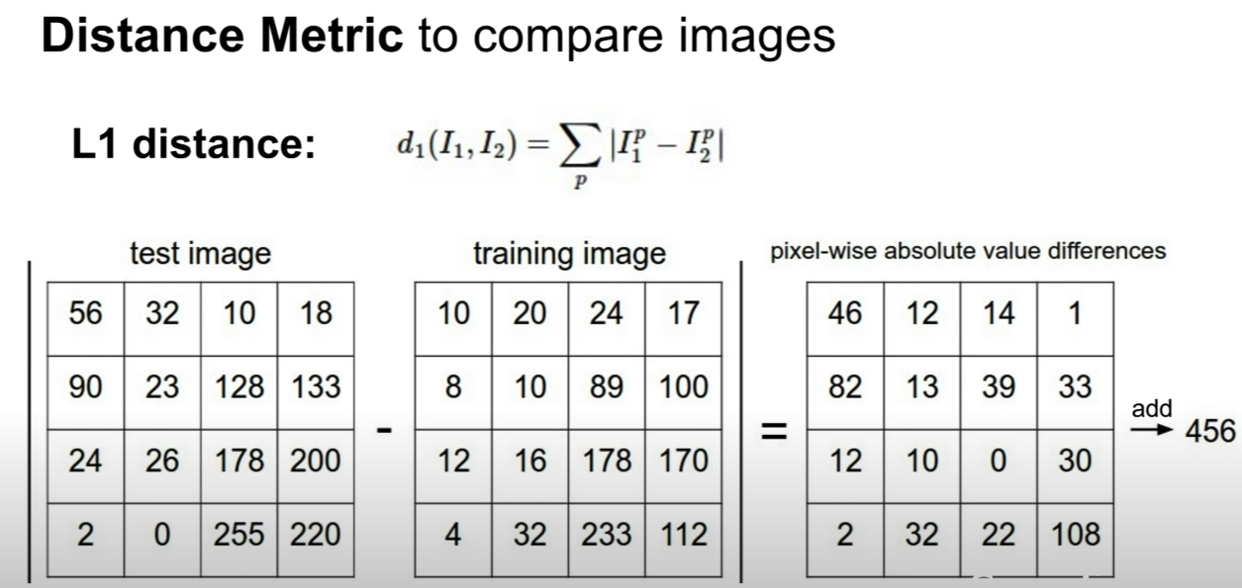
그렇다면, 우리는 이미지끼리 비교를 어떻게 할 수 있을까?
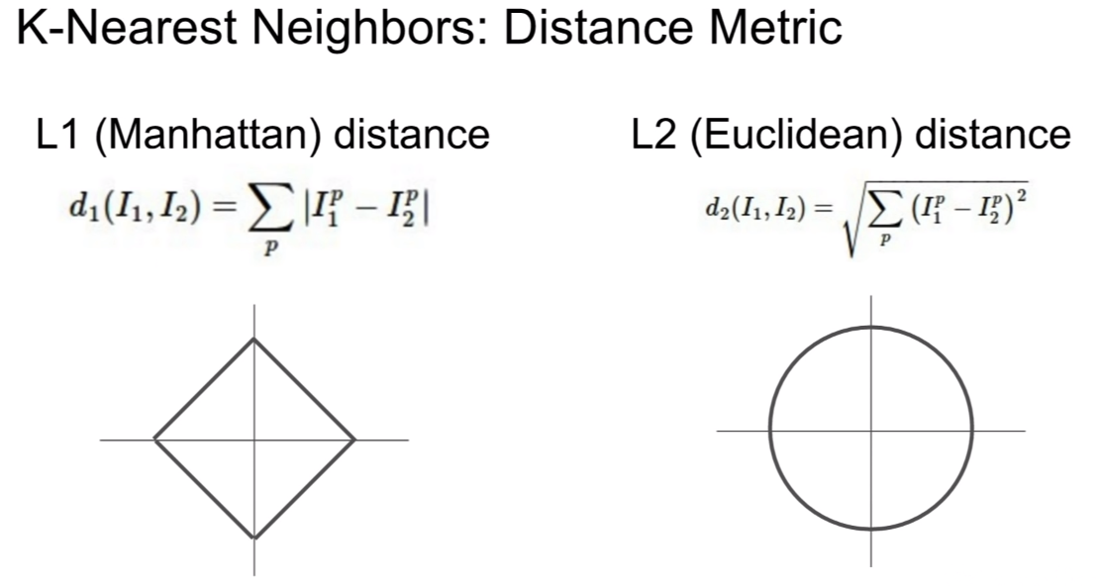
바로 거리를 제는 것(distance metric)이다.
이 슬라이드에서 보여주는 것은, 각 위치에 대응되는 픽셀값끼리의 차에, 절댓값을 취한다.
이것을 모든 픽셀에 대해서 수행한 후 더하는 작업을 한다.
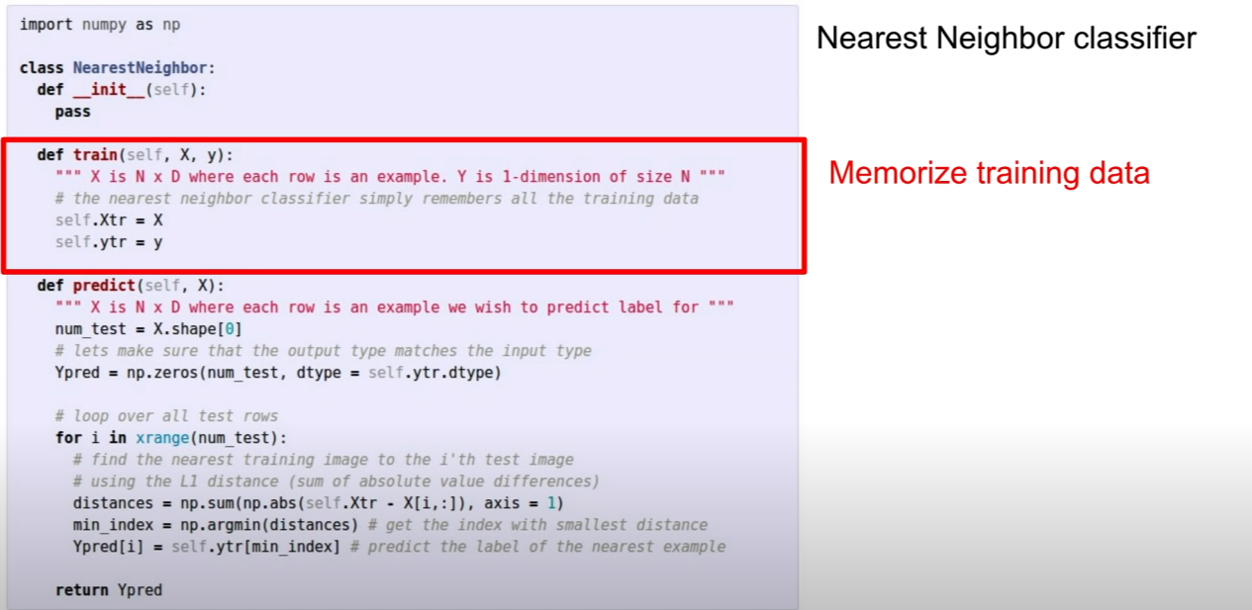
이미지 한장의 데이터와 레이블을 입력받아 저장한다.
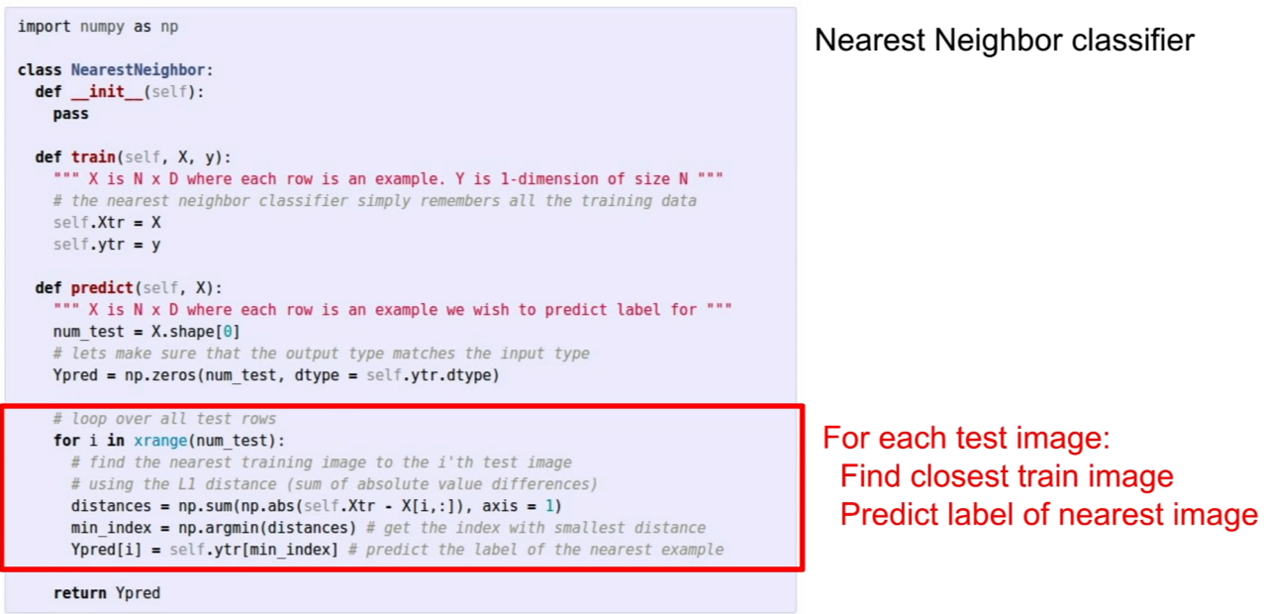
테스트 이미지가 들어오면 저장된 이미지들과 거리비교를 통하여 거리가 가장 낮은 이미지를 찾아낸다. 코드에서는 해당 이미지의 인덱스를 찾아내는 방식이다.

이미지 한장을 기준으로 헀을 때, 시간복잡도이다.
이미지 한장을 train 시키는 것은 해당 정보를 기입하면 되기 때문에, O(1)이다.
하지만 이미지 한 장을 predic하는 것은 n장의 이미지와 비교를 해야 하기 때문에 O(n)이다.
또한, 훈련시에 느린것은 괜찮지만, 테스트시에 더 느린것은 안된다. 왜냐하면 실제롷 활용 될 때에는
빠르가 inference가 되야하기 때문이다.
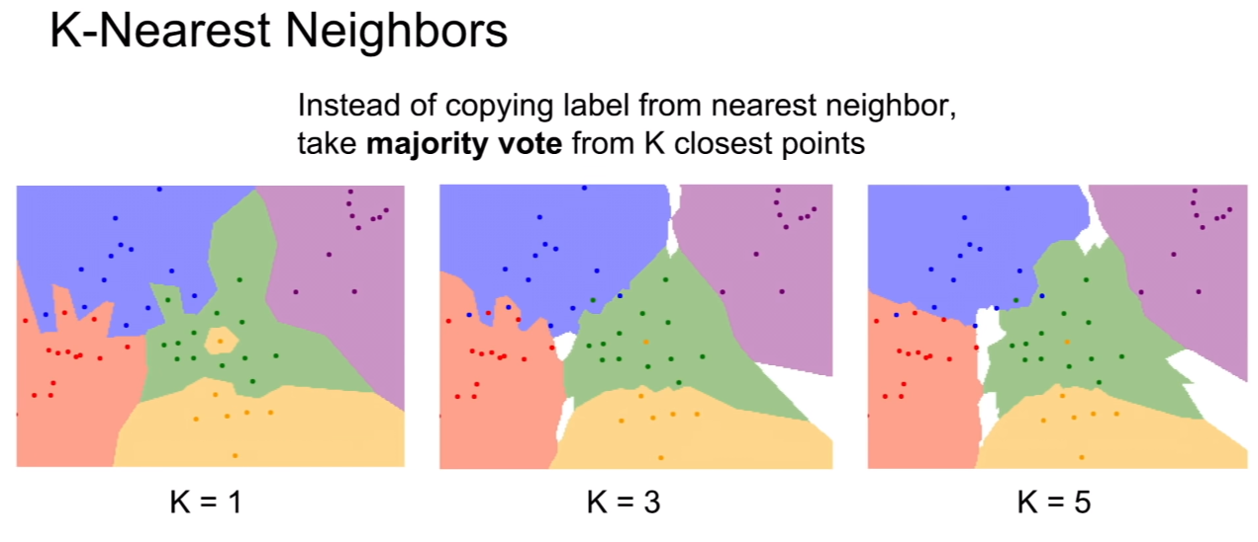
K=1 일 때에는 서로 다른 클래스끼리 포인트 사이의 거리가 동일할 것이다.
k-=3, k=5가 될 수록 majority voting을 통하여 경계가 더욱 정교해질 것이다. (주변 포인트의 영향을 받기 때문.)
Distance metric에 따라서, 결과가 다르게 나올수도 있다.
응용 분야에 따라서 적합한 distance metric을 사용해야한다.
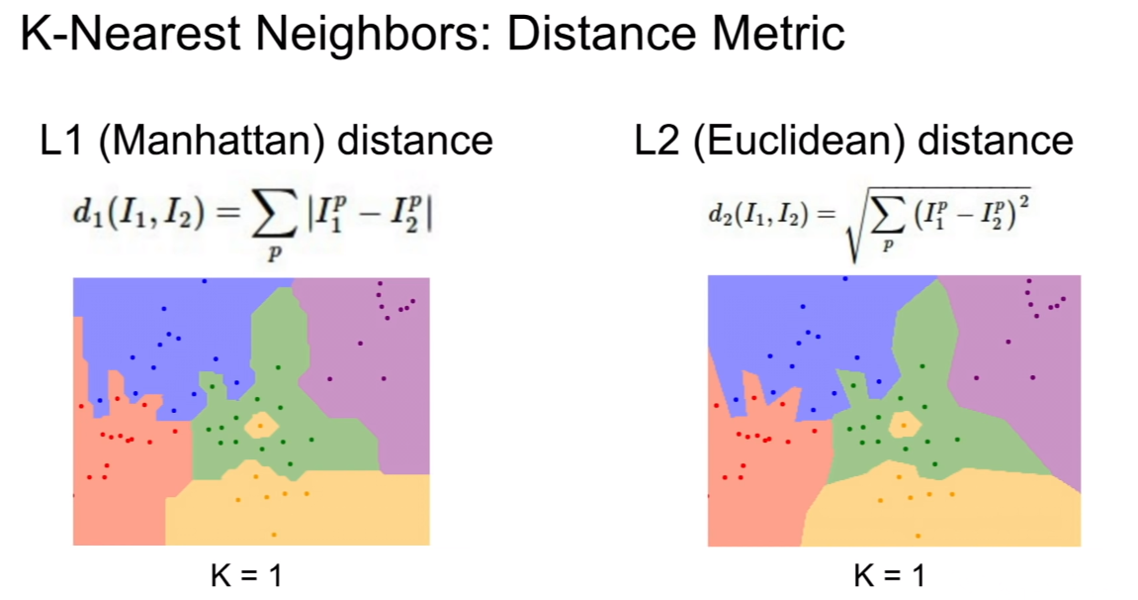
Distance metric에 따라서, KNN의 경계가 달라진 모습을 볼 수 있다.

적절한 k 그리고 적절한 distance metric을 찾아내기 위해서는 최대한 여러번 반복을 하여 가능한 최고의 하이퍼파라미터를 선택해야 한다.
Train/Validation/Test set split
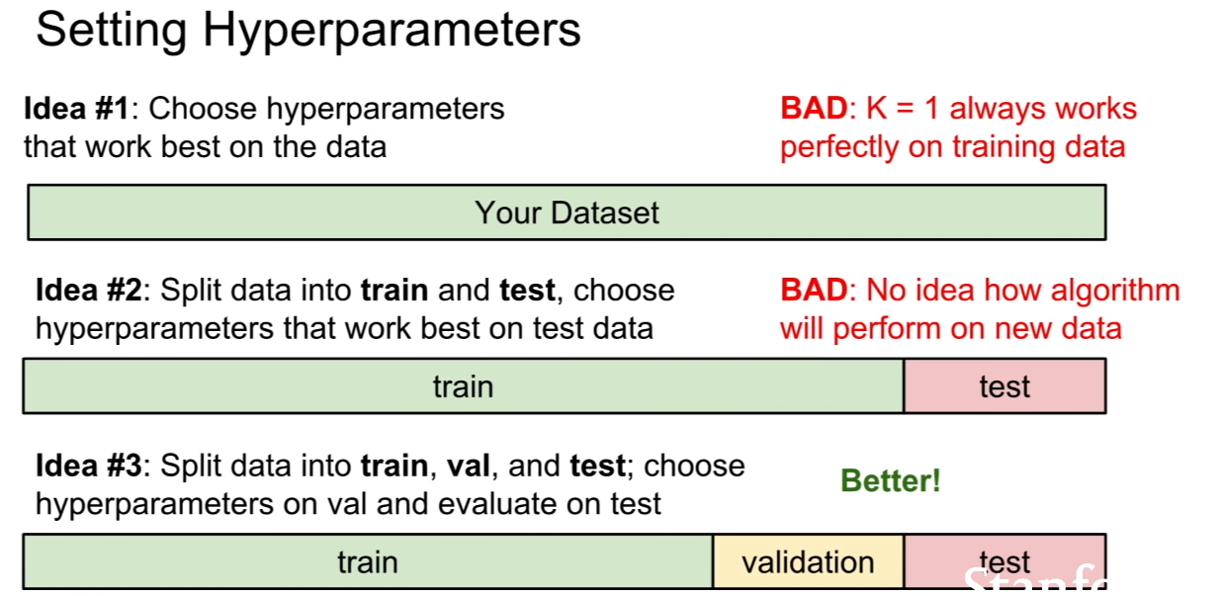
새로운 데이터가 들어올 때, 더 잘 대응하기 위하여 기존에 가지고 있는 데이터셋을 잘 이용할 필요가 있다. 만약에 idea#1과 같이, 모든 데이터를 훈련을 위해 사용하여 경계를 설정해놓으면 위에서 보았던 것과 같이 K=1에 대해서는 훈련데이터에 대해서는 100%의 정확도를 보인다. 하지만, 이것은 훈련 데이터에 대해서만 성립할 뿐, 새로운 데이터가 들어오게 되면 얘기가 달라진다.
k가 1보다 커지게 되면, 훈련데이터에 대해서 100%들어맞지 않게 되는 모습을 k=3, k=5일 때 이미지에서 찾아볼 수 있다. 하지만 새로운 데이터에 대해서는 k=1일 때보다 정확도가 더 증가하는 모습을 보일 것이다. 이를 확인하기 위하여 test셋을 만들어야 한다. 마치 idea#2처럼 말이다.
그런데 idea#2처럼 해도 무언가 모자르다. 무엇이 모자를까? 우리가 하나의 프로세스를 만든다고 생각해보자. 훈련데이터로 경계를 만들고, 임의의 데이터에 대해서도 잘 동작하는지 검증해보면서 하이퍼파라미터를 조정하고, 최종적으로 진짜 새로운 데이터를 실험해봐야 한다. idea#2는 파라미터를 검증해보고 새로운 데이터를 실험해보는게 아닌, 그냥 새로운 데이터만 실험해보는 과정밖에 없다. 그렇기 때문에 idea#3이 가장 이상적이라 할 수 있다.
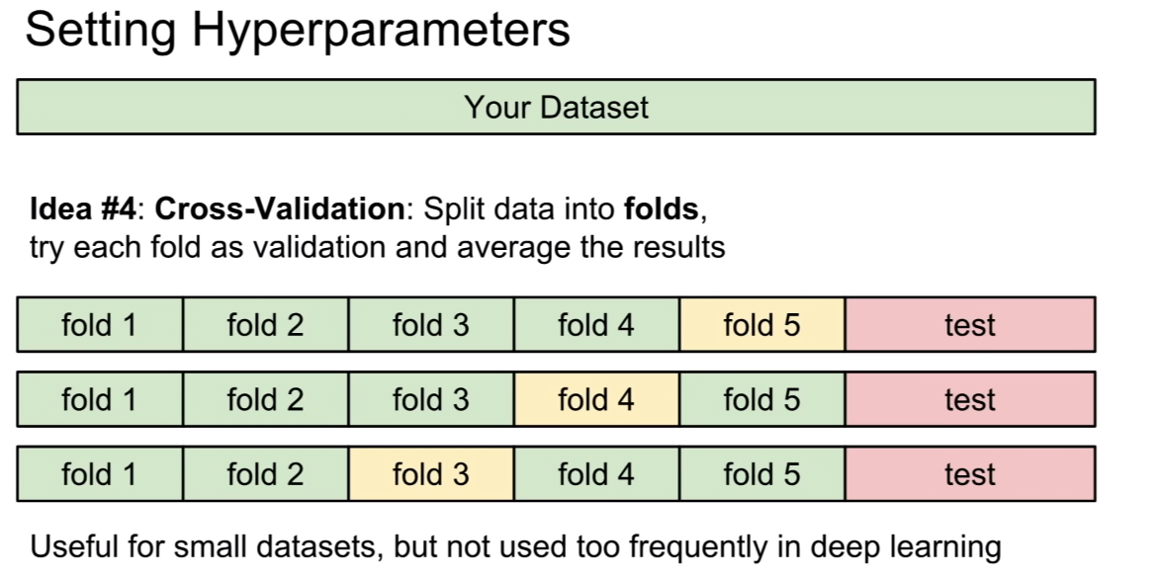
딥러닝에서는 잘 사용하지는 않지만, 머신러닝에서 종종 사용되곤 하는 k-fold validation 방법이다. 훈련 데이터셋을 k개의 fold(부분집합)으로 나누고(예제에서는 5개의 fold로 나누었으므로, 5-fold validation), 4개는 training set 나머지 1개는 validation set으로 설정하는 방법이다. 그리고 해당 validation을 통해서 나온 파라미터를 평균을 하는 것으로 최종 파라미터를 결정한다.
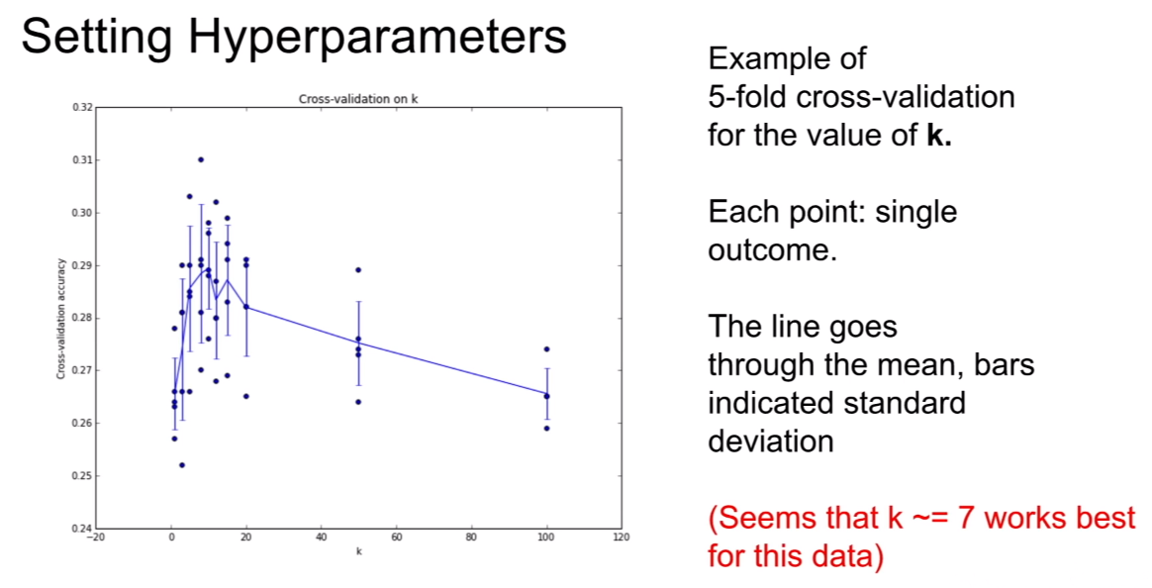
하지만 무조건 k가 클수록 좋은것은 아니다. 위 그래프를 통하여 약 k=7에서 잘 작동하는 모습을 볼 수 있으며 이것은 적용하는 데이터, 기법이 무엇인지에 따라 달라질 수 있다.

이미지 도메인에서는 KNN이 잘 사용되지 않는다고 한다. 왜냐하면 distance metric을 통하여 거리를 비교해야 하는데, 위에 나온 예시들 처럼 4개의 이미지는 서로 다른 이미지이지만, distance가 모두 동일하여 어떤 정보도 제공해줄 수 없다.
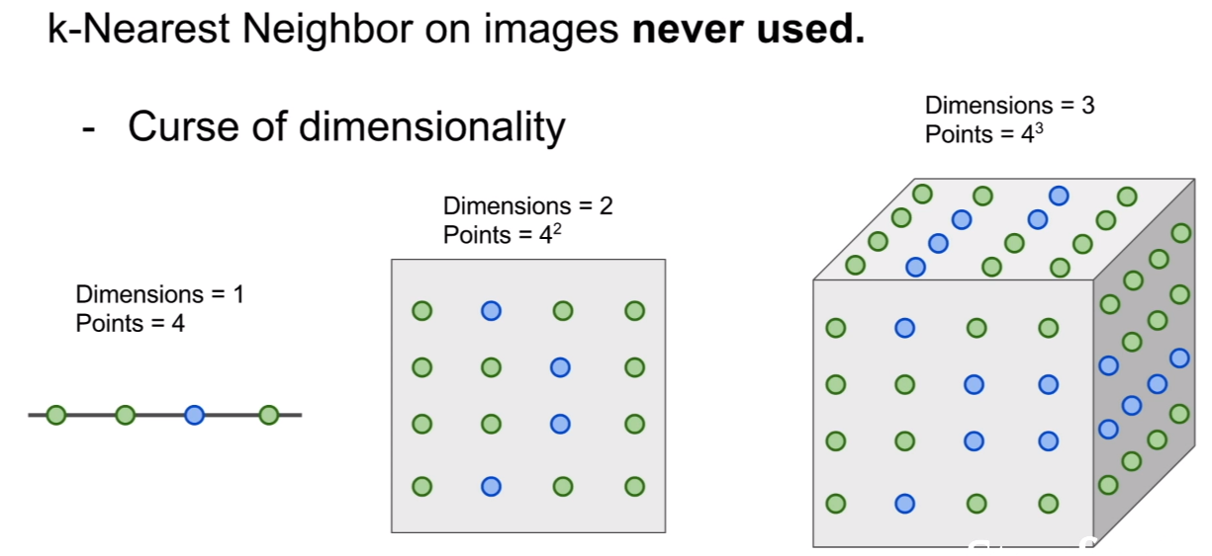
또한 위 사진 처럼 차원이 증가할 수록 비교해야 되는 픽셀수가 급수적으로 많아쟈, 일일히 비교하기에 너무 느리기 때문이다.
Linear Classifier
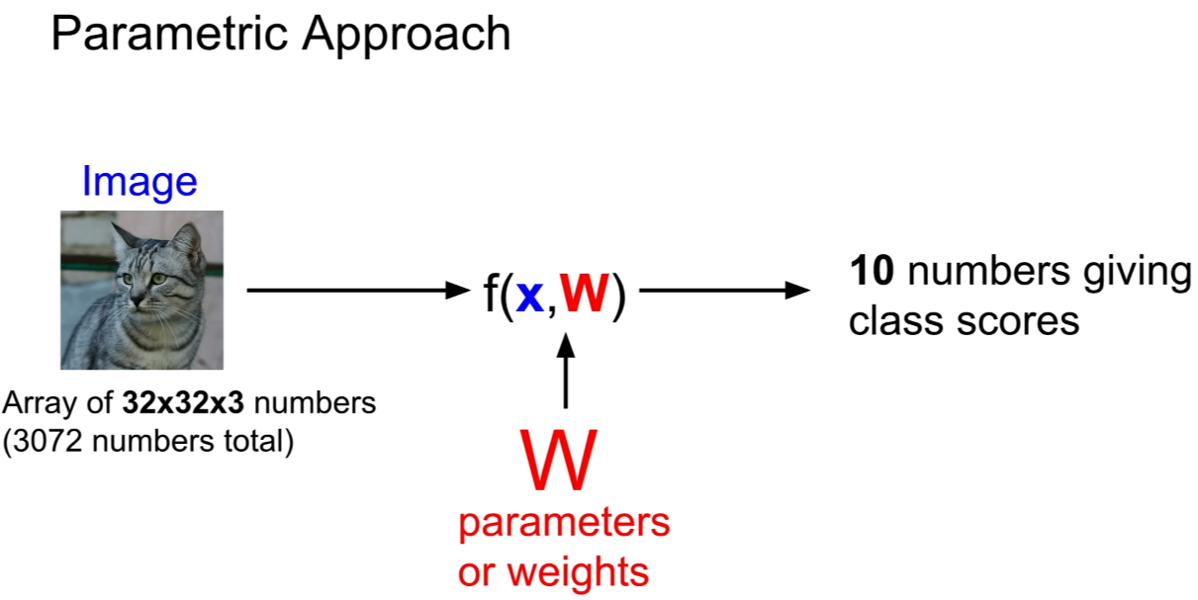
이번에는 KNN과 같은 분류기가 아닌 선형 분류기를 살펴볼 것이다. 이 방법이 더욱 딥러닝에 쓰이는 방법과 유사하다 볼 수 있다. 이미지와 이미지를 특정 공간에 매핑 시키는 파라미터W 를 통하여 분류기가 작동한다.
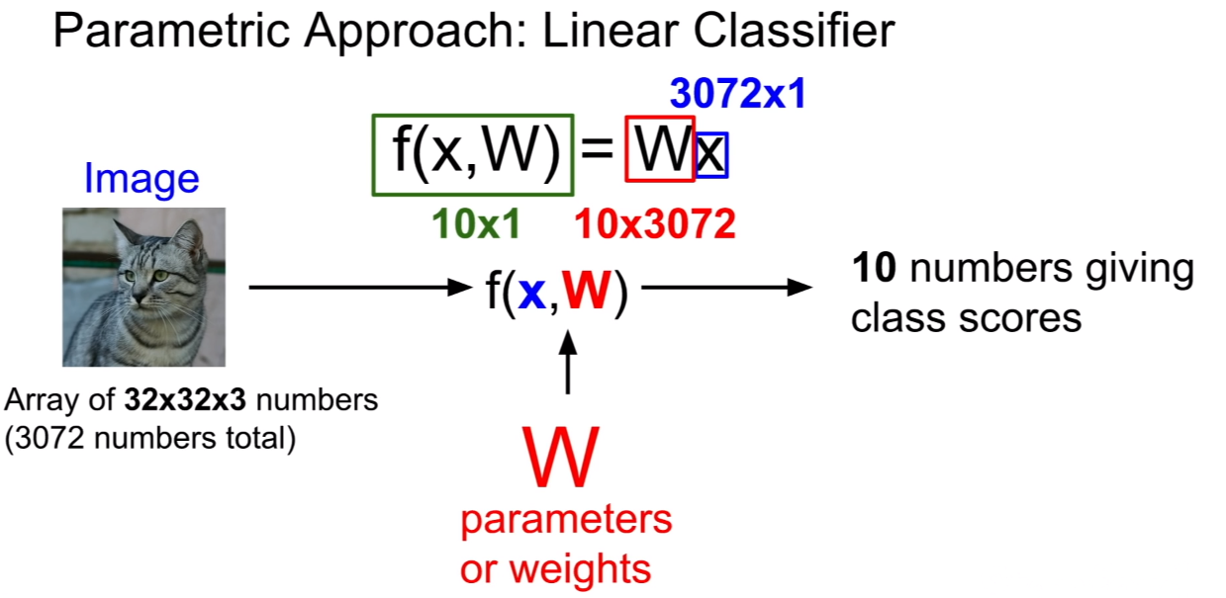
32x32x3 크기의 이미지를 flatten하면, 3072x1의 벡터로 변형이 가능하다. 그리고 CIFAR-10의 클래스의 개수는 10개이므로, 10개의 클래스의 스코어에 대해서 추론하기 위하여 파라미터W 는 10x3072의 형태를 뗘야한다. 이후 행렬곱을 진행하면, 10x1 형태의 스코어를 가진 벡터가 나오게 된다.
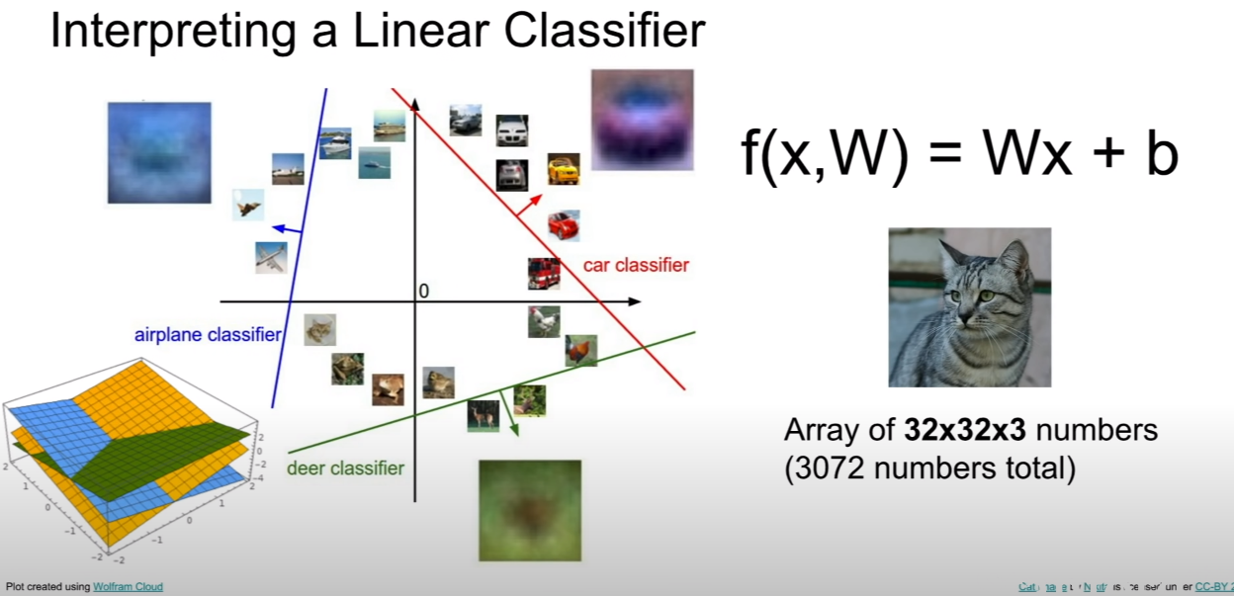
이게 선형 분류기인 이유는 위 그림처럼, 마치 분류되는 공간이 선을 여러개 그어 분류하기 때문이다. 즉, 위 식을 해석하자면 3072차원에 10개의 직선이 그어진다고 볼 수 있다. 그렇다면 10개의 직선은 무엇을 뜻할까? 하나의 직선은 binary classifier다. 즉 하나의 직선은 해당 클래스인가 아닌가를 분류하는 기준선을 뜻한다.즉, cifar10-classes = {비행기, 자동차, 새, 고양이, 사슴, 개 , 개구리, 말 배, 트럭}의 총 10가지 클래스가 존재하는데 하나의 직선은, 비행기 인가 아닌가, 자동차인가 아닌가, 새인가 아닌가, 고양이인가 아닌가… 트럭인가 아닌가를 판단하는 직선이 총 10개가 있는 것이다.
이럴 때 클래스가 분류되는 방법은 집합처럼, 비행기인 영역에 속하고, 나머지 클래스가 아닌 영역에 속하면 비행기로 분류될 것이다.
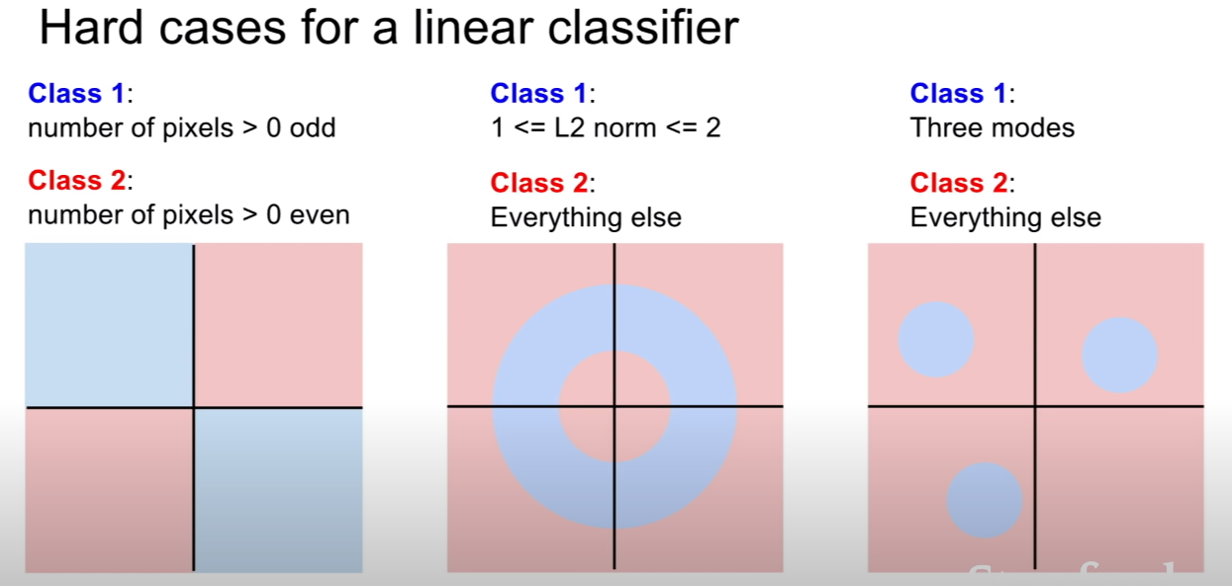
이런 선형 분류기의 성질 때문에, 위와 같은 그림들은 선형 분류기가 분류하기 어려운 사례로 꼽힌다. 클래스가 2개이기 때문에, class1인가 아닌가를 판별하므로, 우리가 쓸수있는 선은 단 한개 뿐이다. 단 한개의 선으로 위 그림을 빨강과 파랑 영역으로 나누기는 불가능 하다.

위에서 말했던것과 같은 선형 분류기의 결과로 나온 스코어를 나타낸 벡터이다.
스코어의 절댓값이 높다는 것은 무엇을 의미할까? 그것은 매핑된 포인트가 경계선으로 부터 거리가 멀다는 뜻이다. 예를 들어, 경계선은 그 포인트가 비행기를 나타내는 포인트인지 아닌지를 결정짓는 마지노선이다. 즉, 경계선으로 부터 멀어질수록 더욱 확실하게 비행기인지 아닌지를 나타낸다는 것이다. 양의 값으로 크다는 것은 경계선으로 부터 거리가 멀다는 뜻이고, 해당 클래스일 확률이 크다는 것을 의미하며, 음의 값으로 크다는 것은 역시 경계선으로부터 거리가 멀다는 것을 의미하고, 해당 클래스일 확률이 낮다는 것을 의미한다.